在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
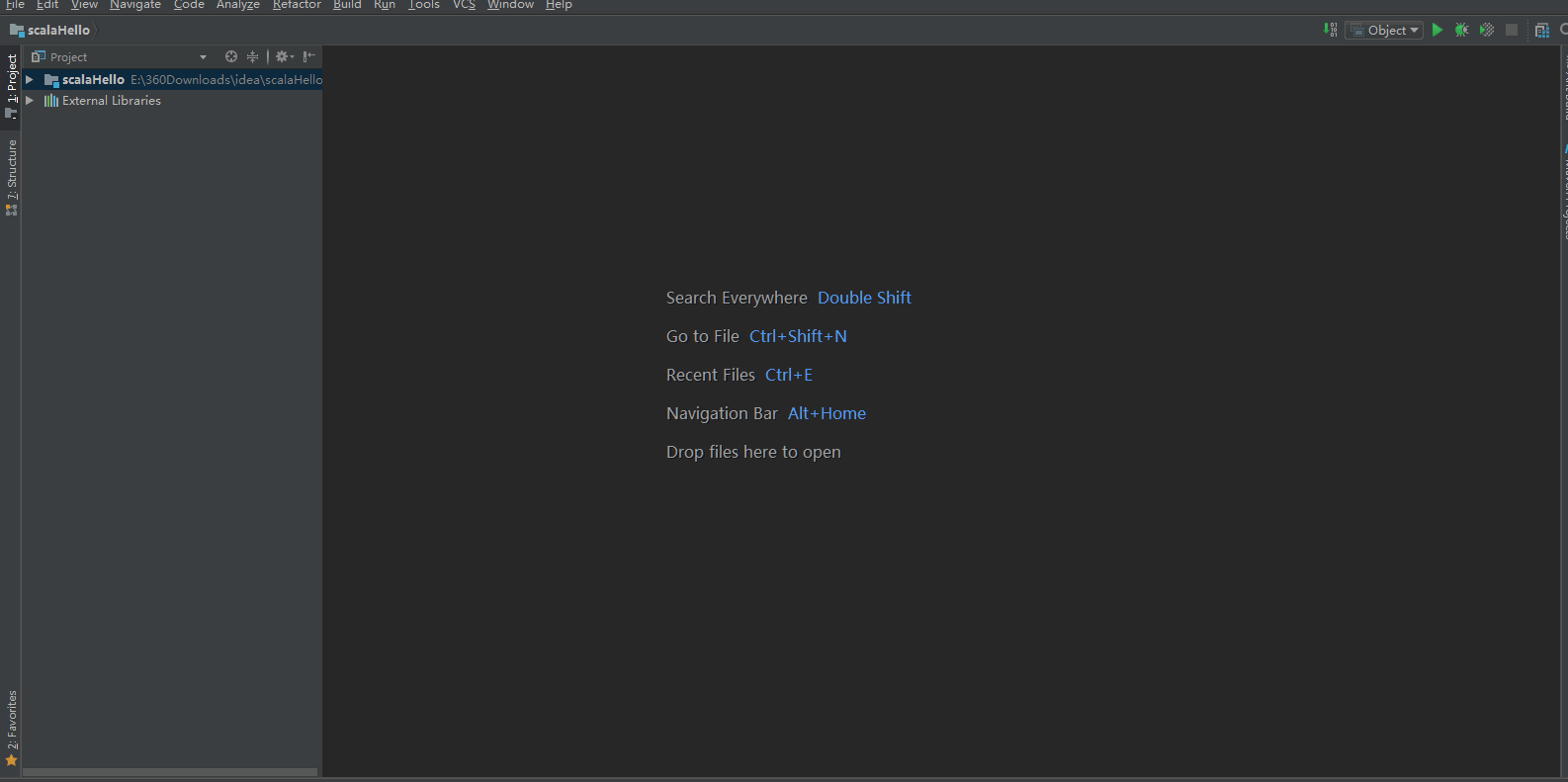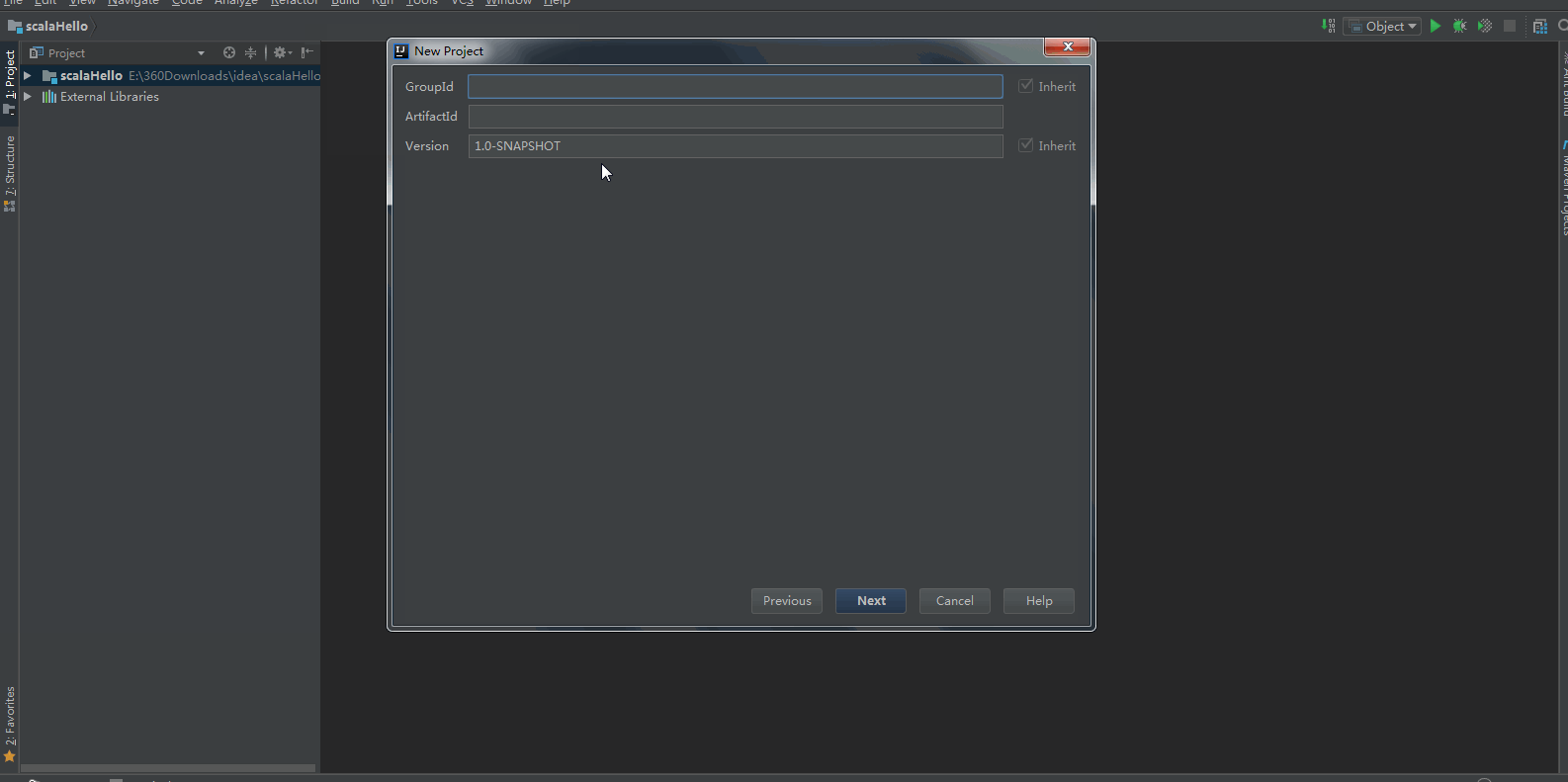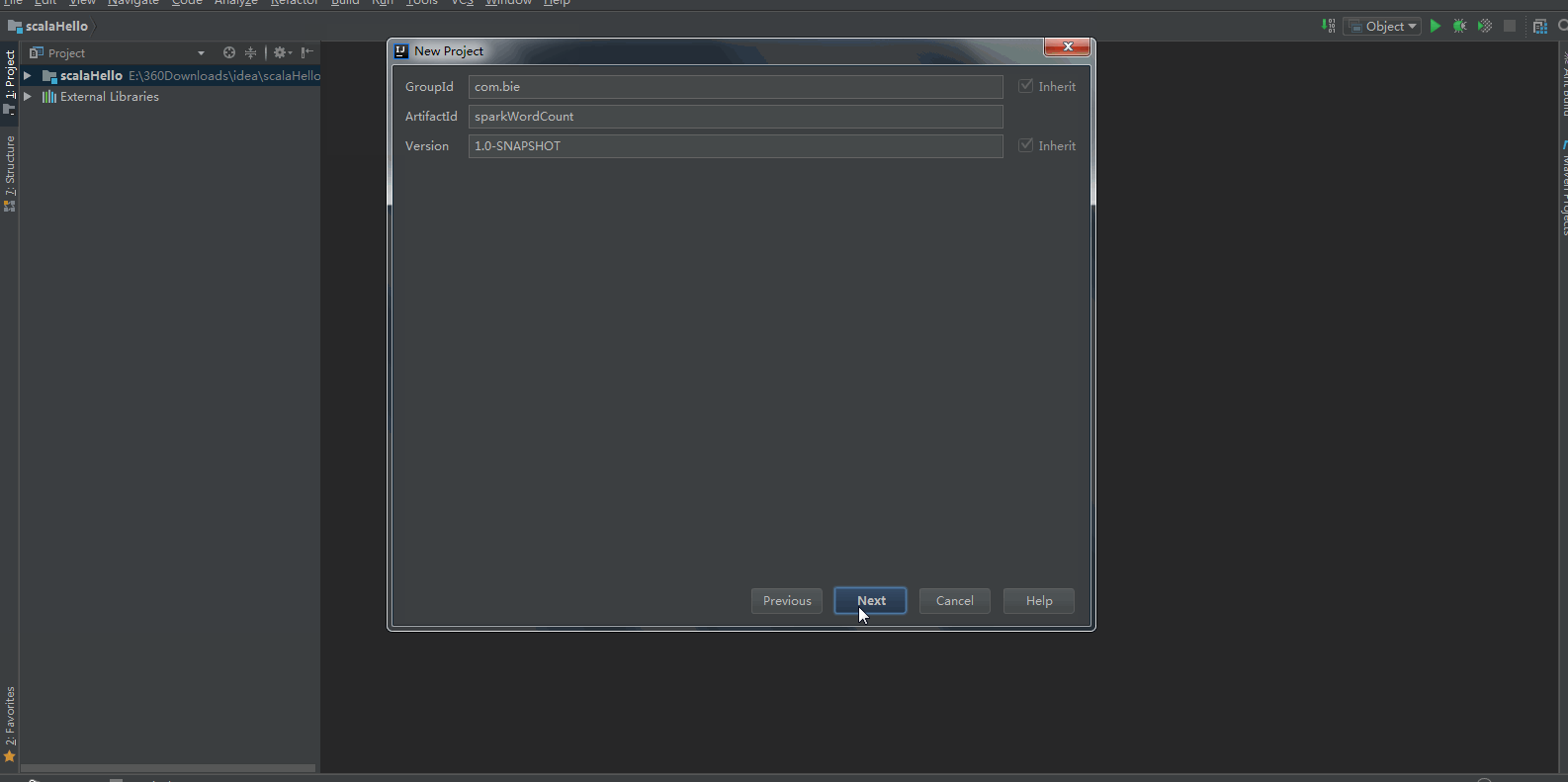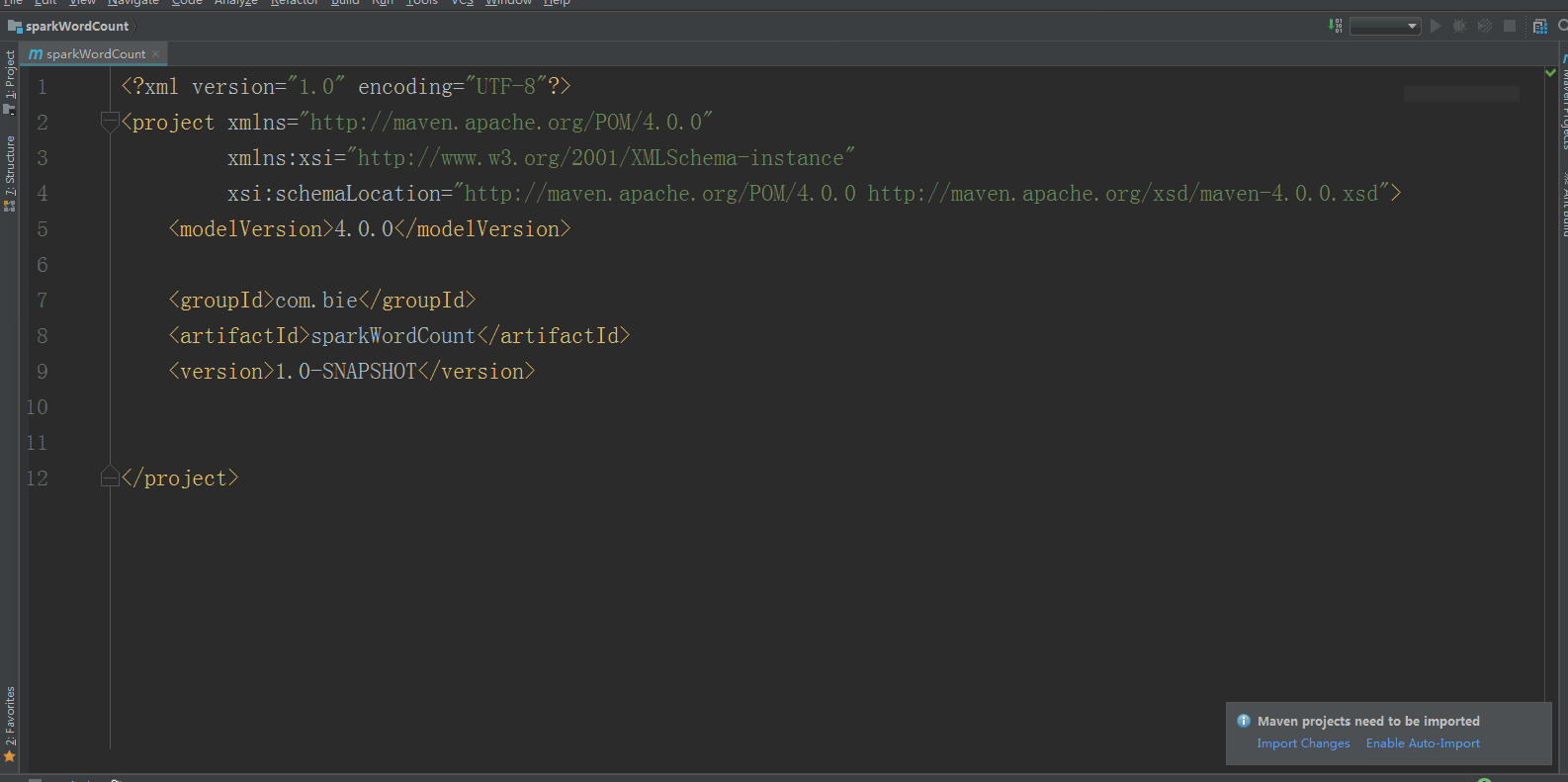
2:配置Maven的pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.bie</groupId>
<artifactId>sparkWordCount</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-</encoding>
<scala.version>2.10.</scala.version>
<scala.compat.version>2.10</scala.compat.version>
</properties> <dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>1.5.</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.</artifactId>
<version>1.5.</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.bie.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
注意:配置好pom.xml以后,点击Enable Auto-Import即可;
3:将src/main/java和src/test/java分别修改成src/main/scala和src/test/scala,与pom.xml中的配置保持一致();
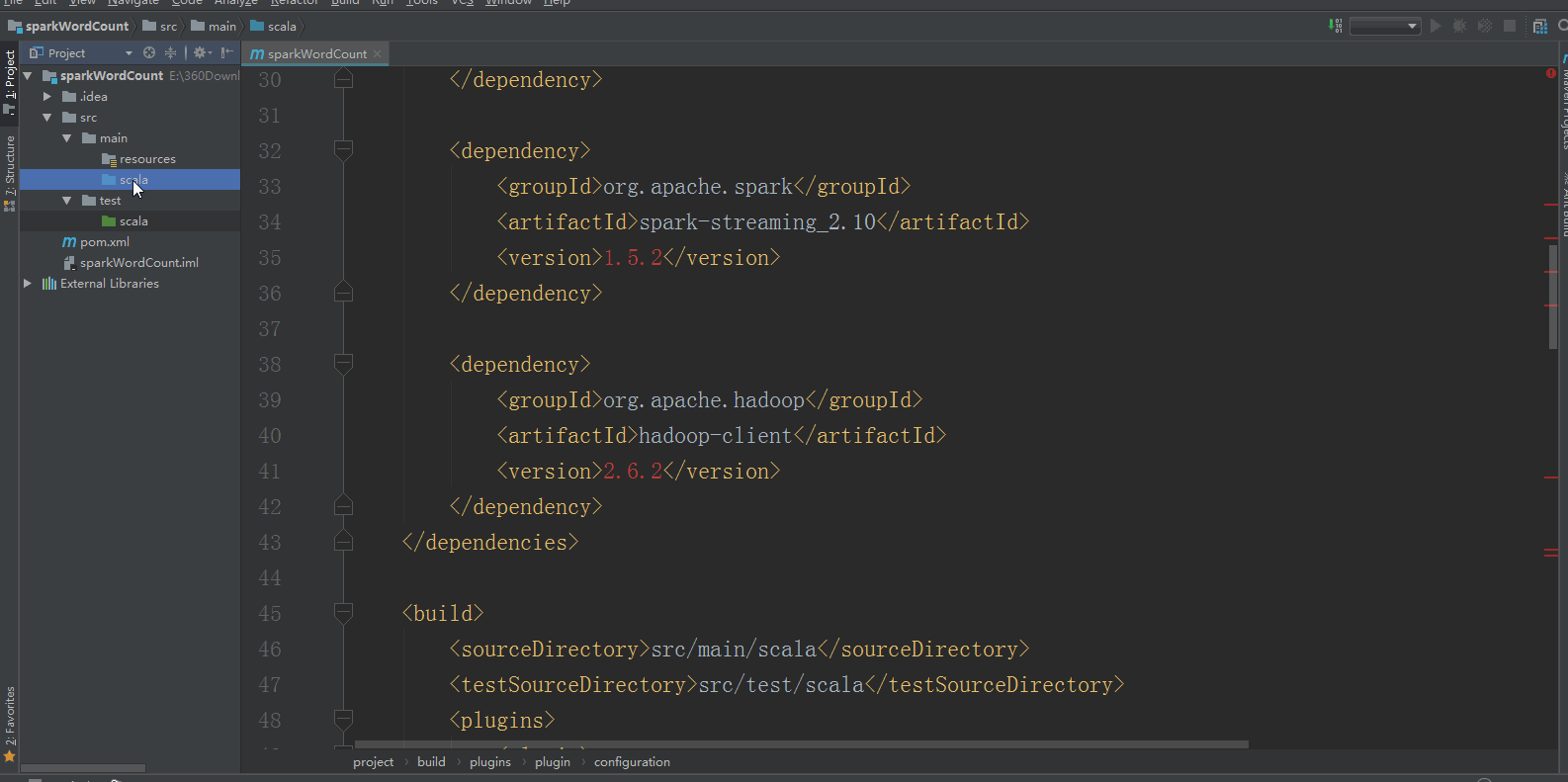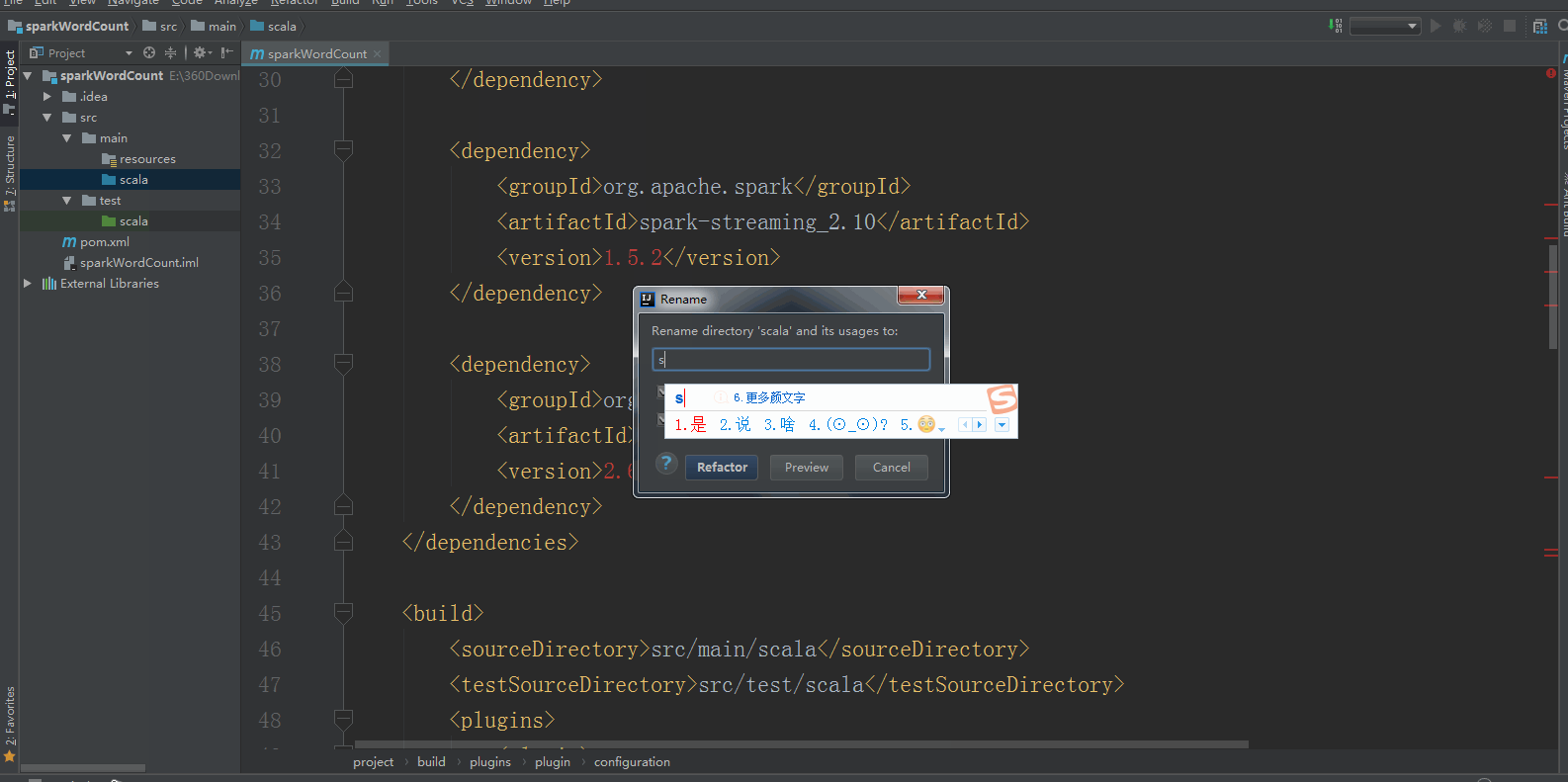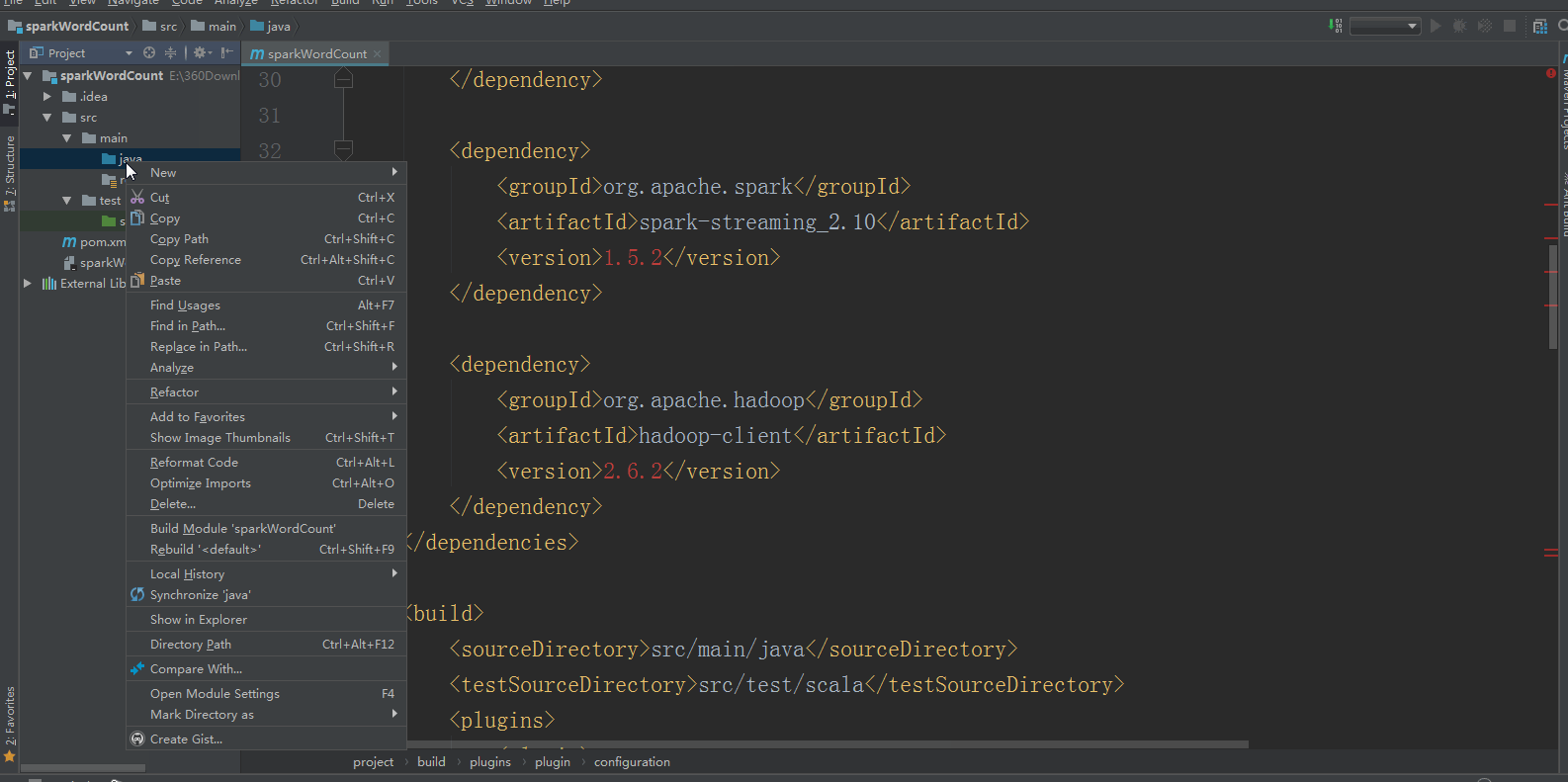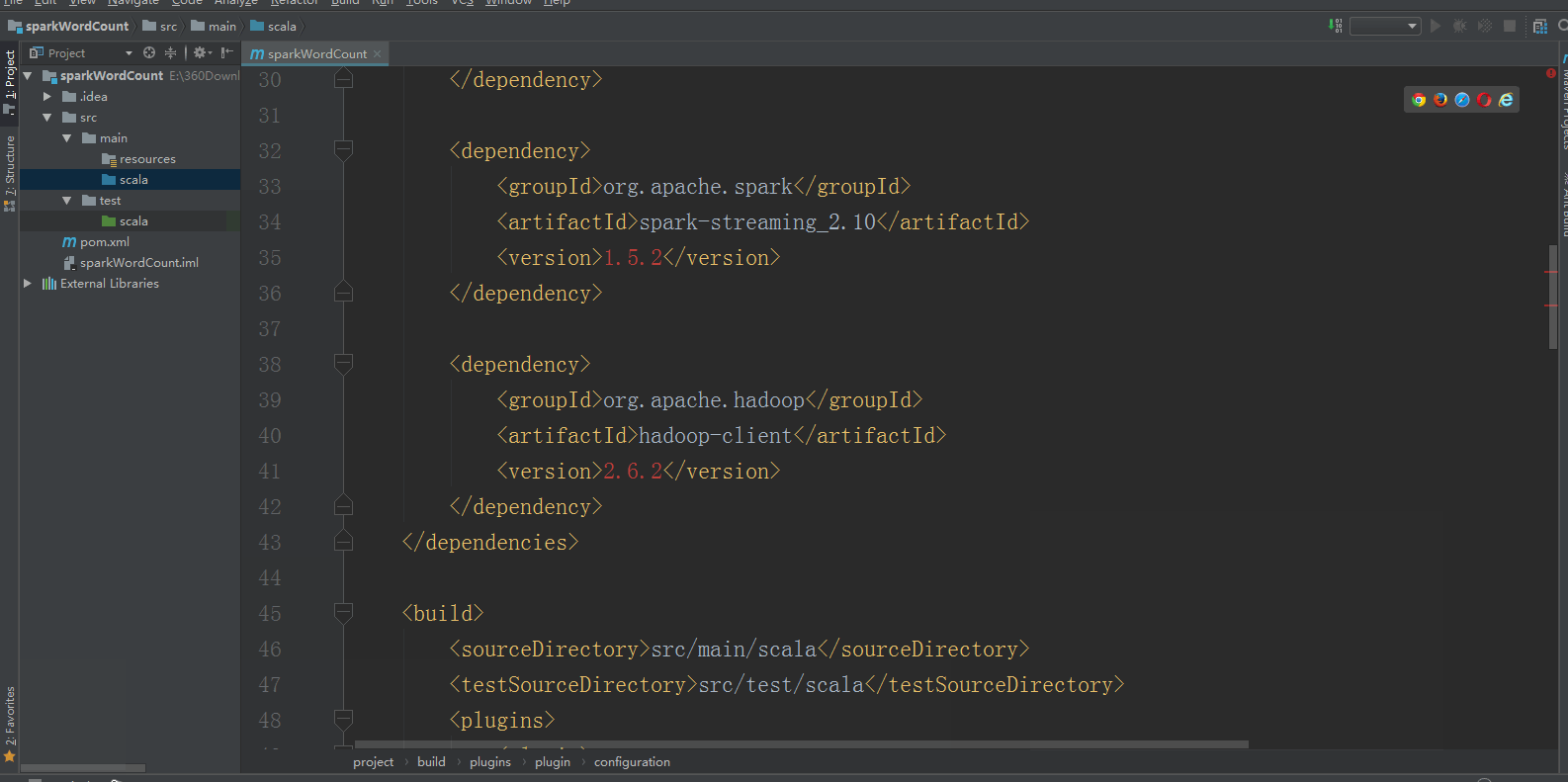
4:新建一个scala class,类型为Object,然后编写spark程序,如下所示:
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//创建SparkConf()并且设置App的名称
val conf = new SparkConf().setAppName("wordCount");
//创建SparkContext,该对象是提交spark app的入口
val sc = new SparkContext(conf);
//使用sc创建rdd,并且执行相应的transformation和action
sc.textFile(args()).flatMap(_.split(" ")).map((_ ,)).reduceByKey(_ + _,).sortBy(_._2,false).saveAsTextFile(args());
//停止sc,结束该任务
sc.stop();
}
}
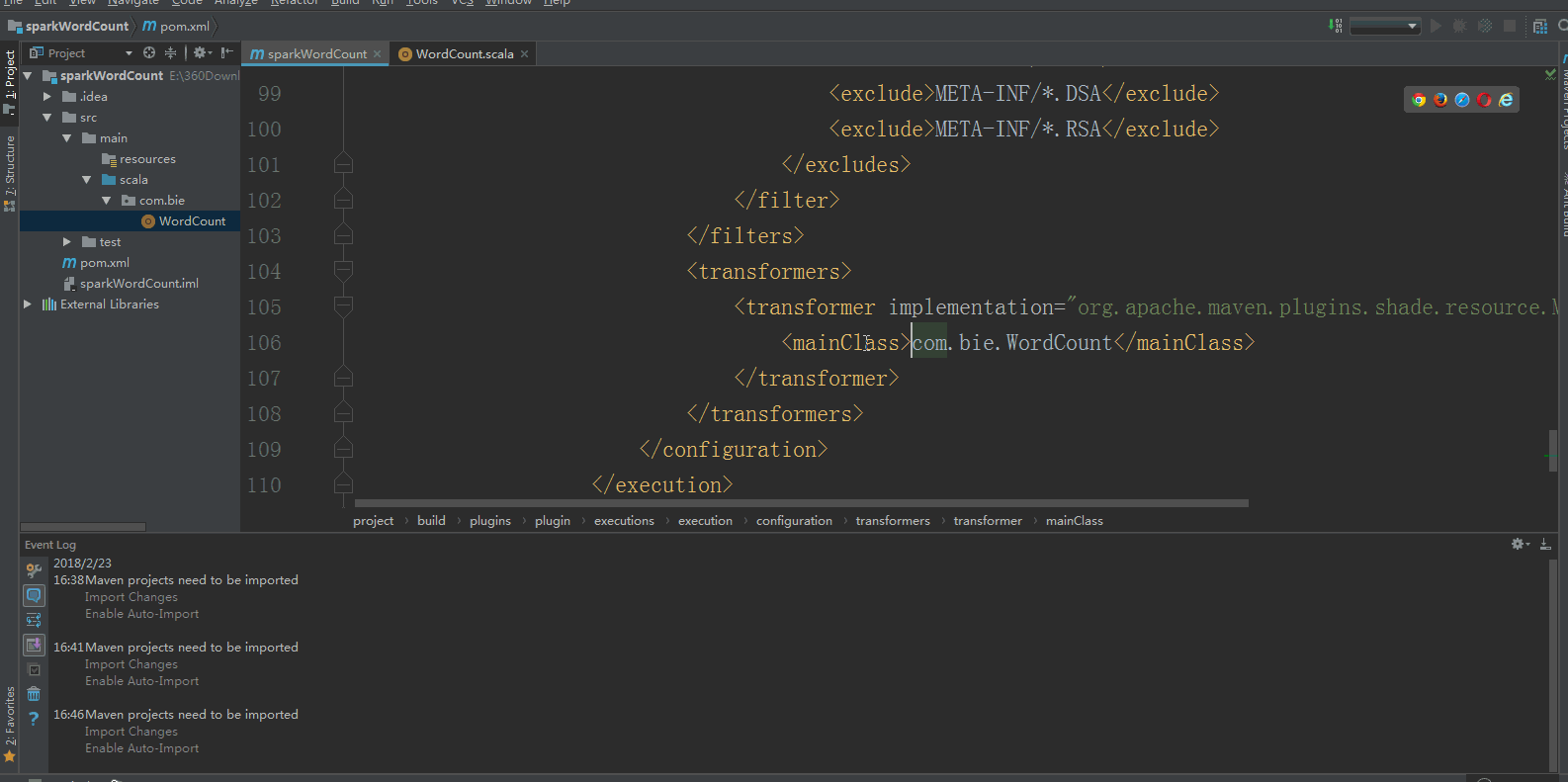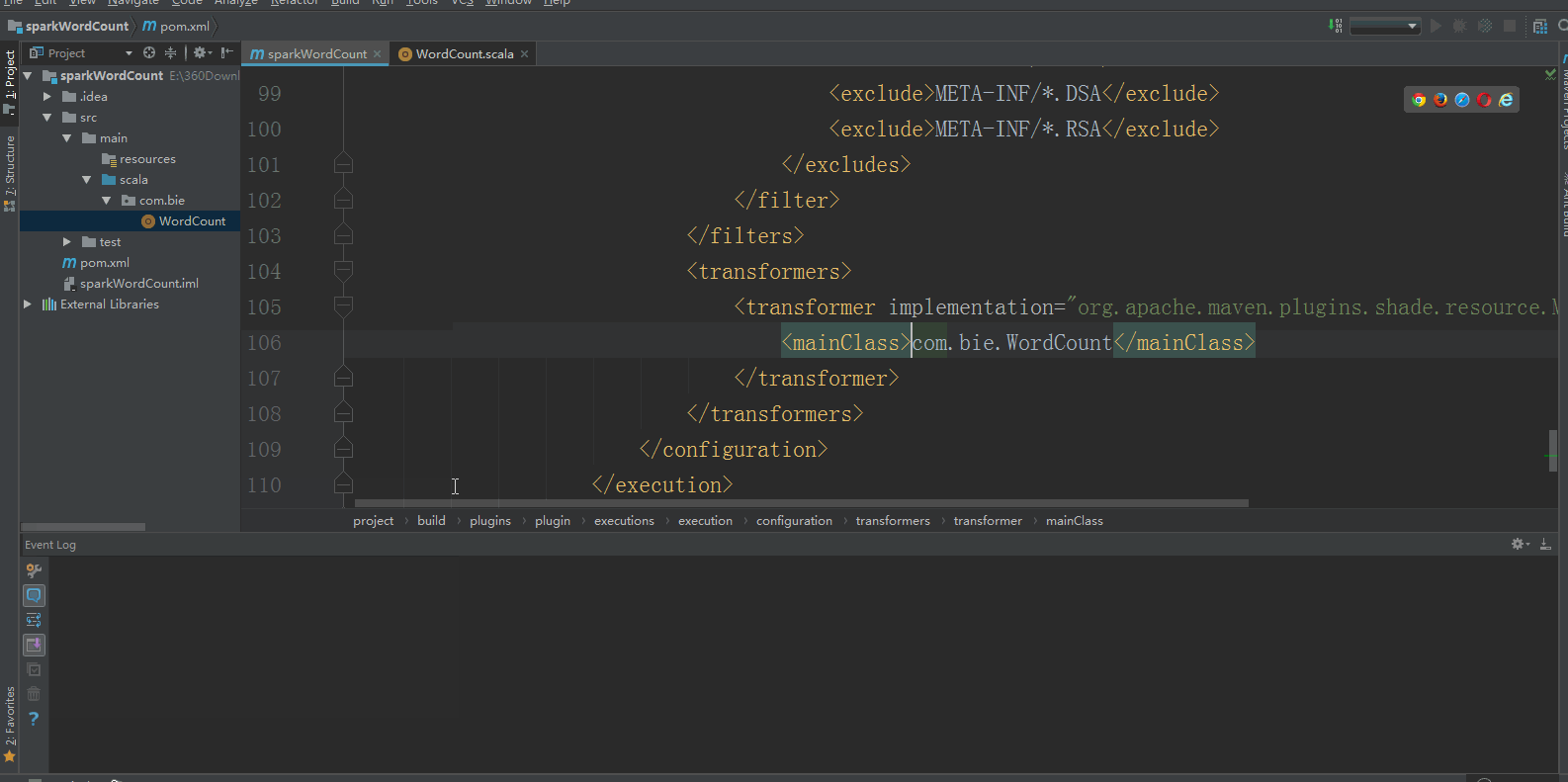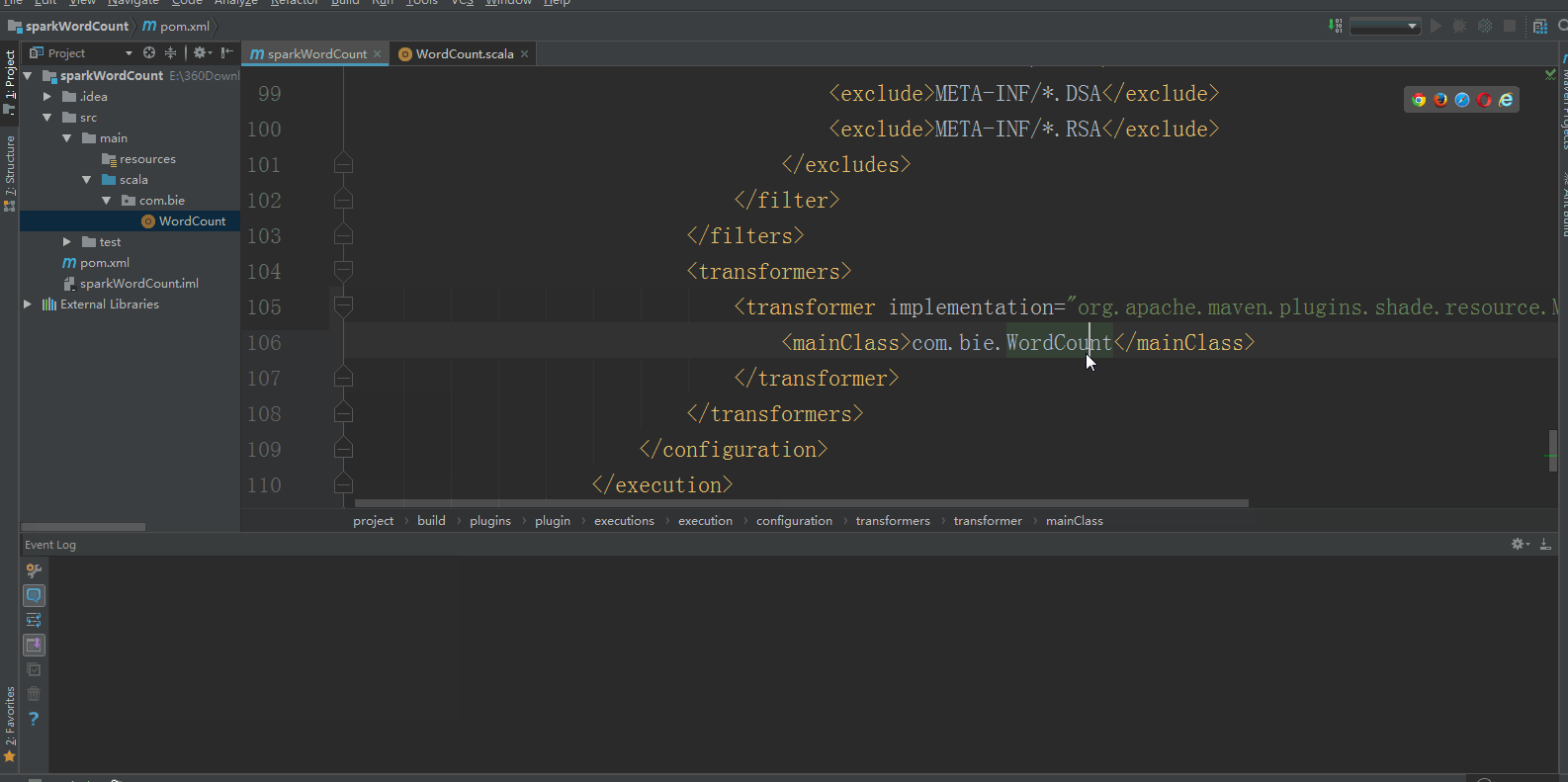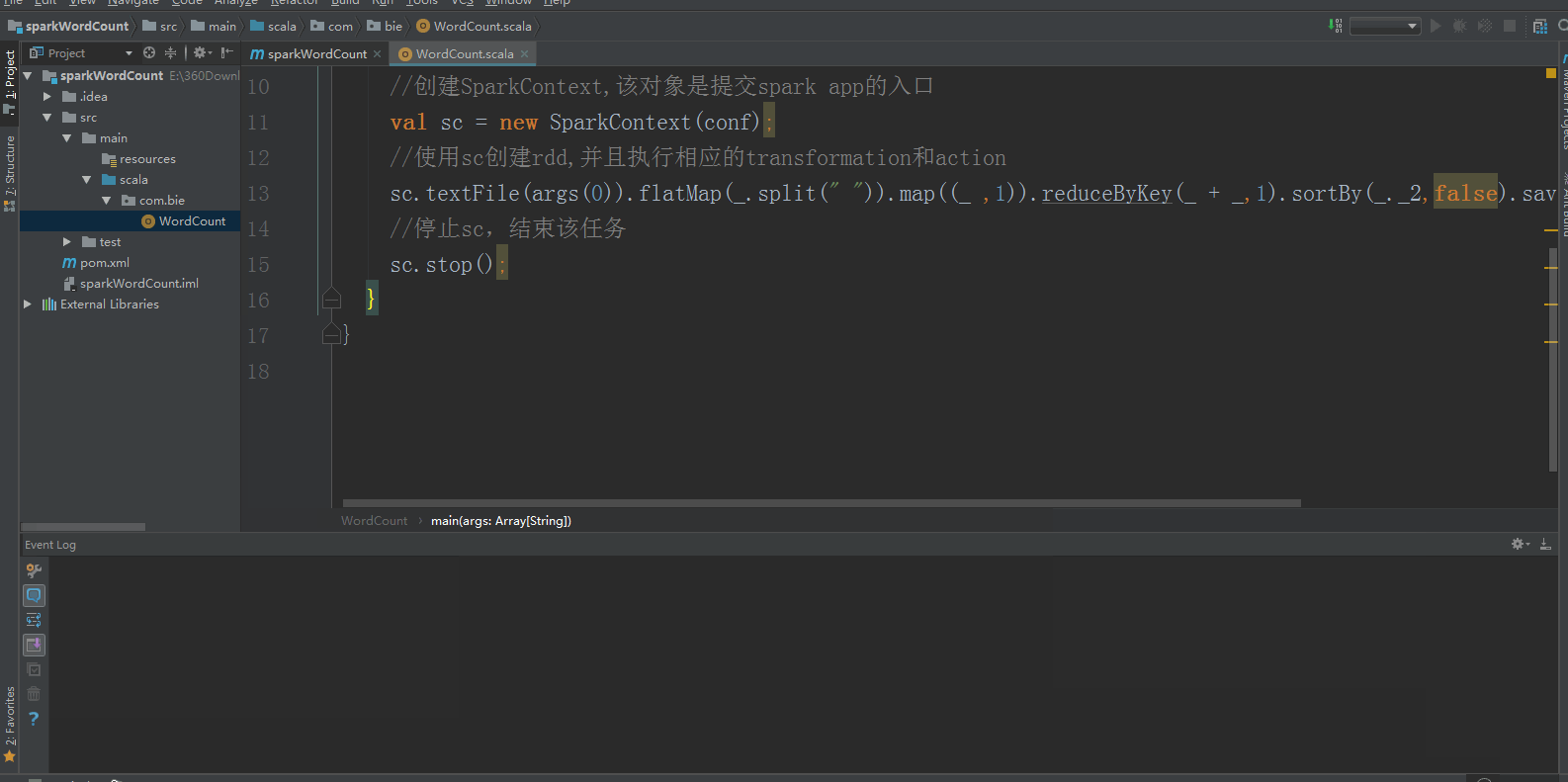
5:使用Maven打包:首先修改pom.xml中的mainClass,使其和自己的类路径对应起来:
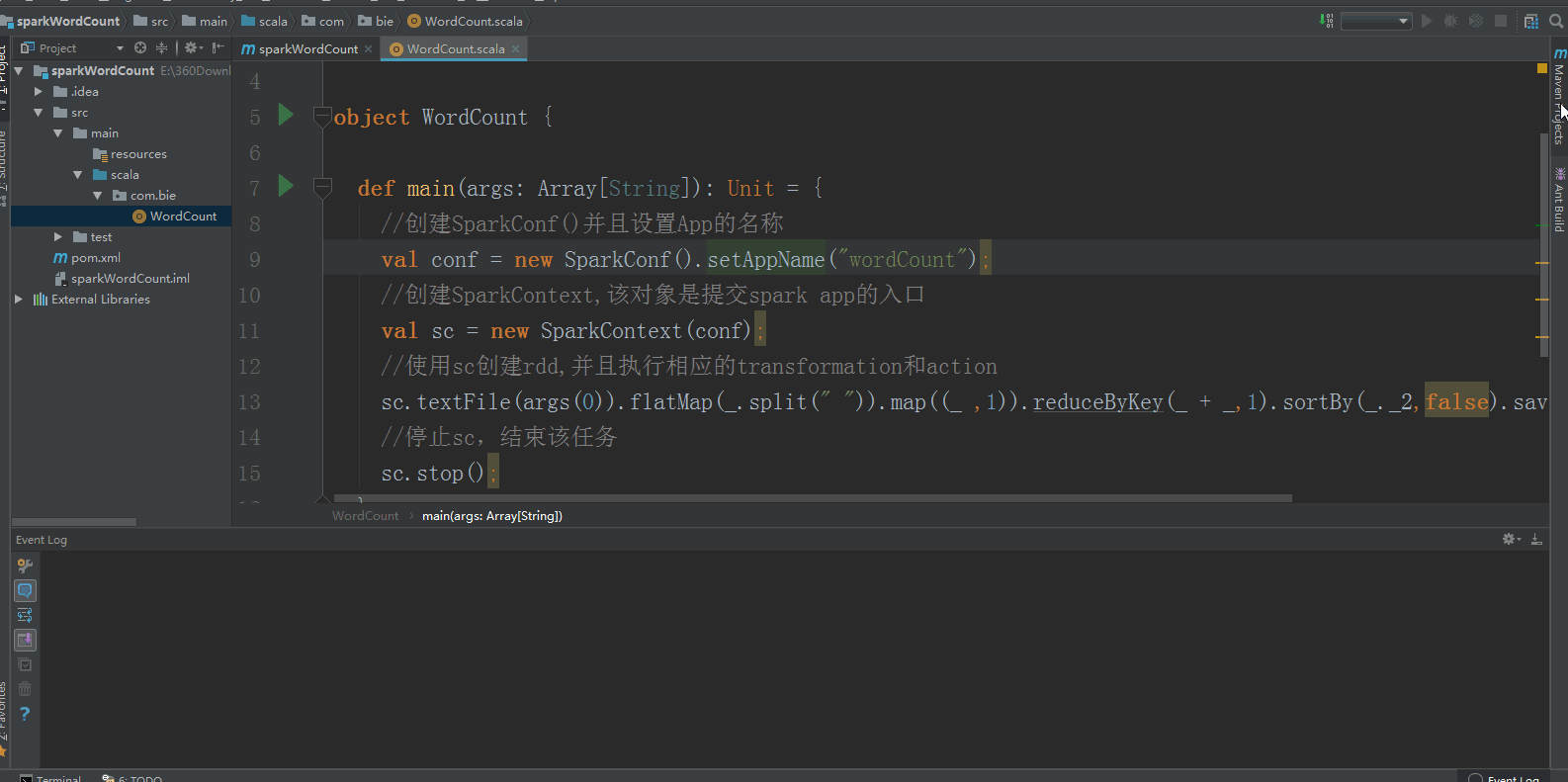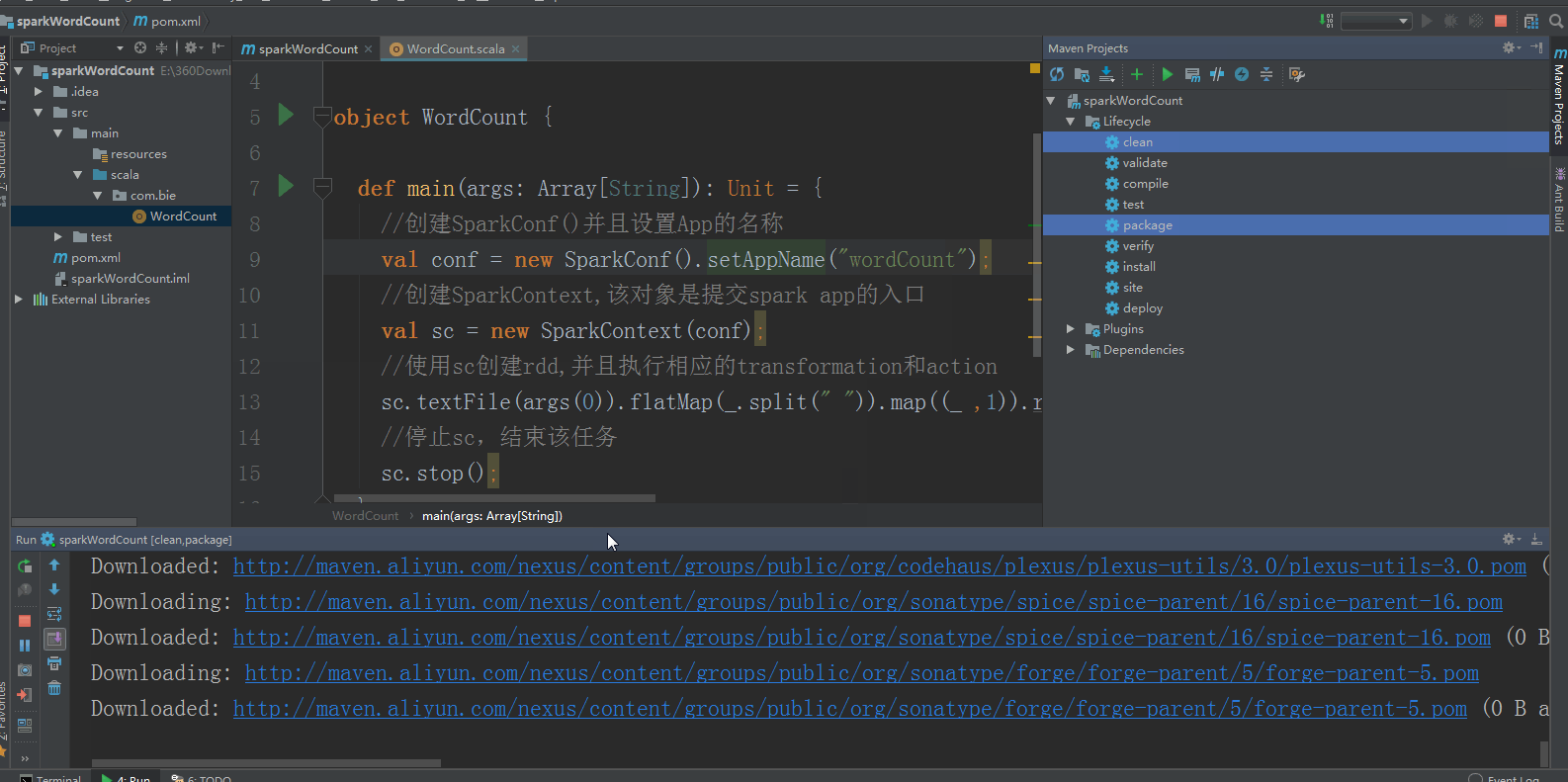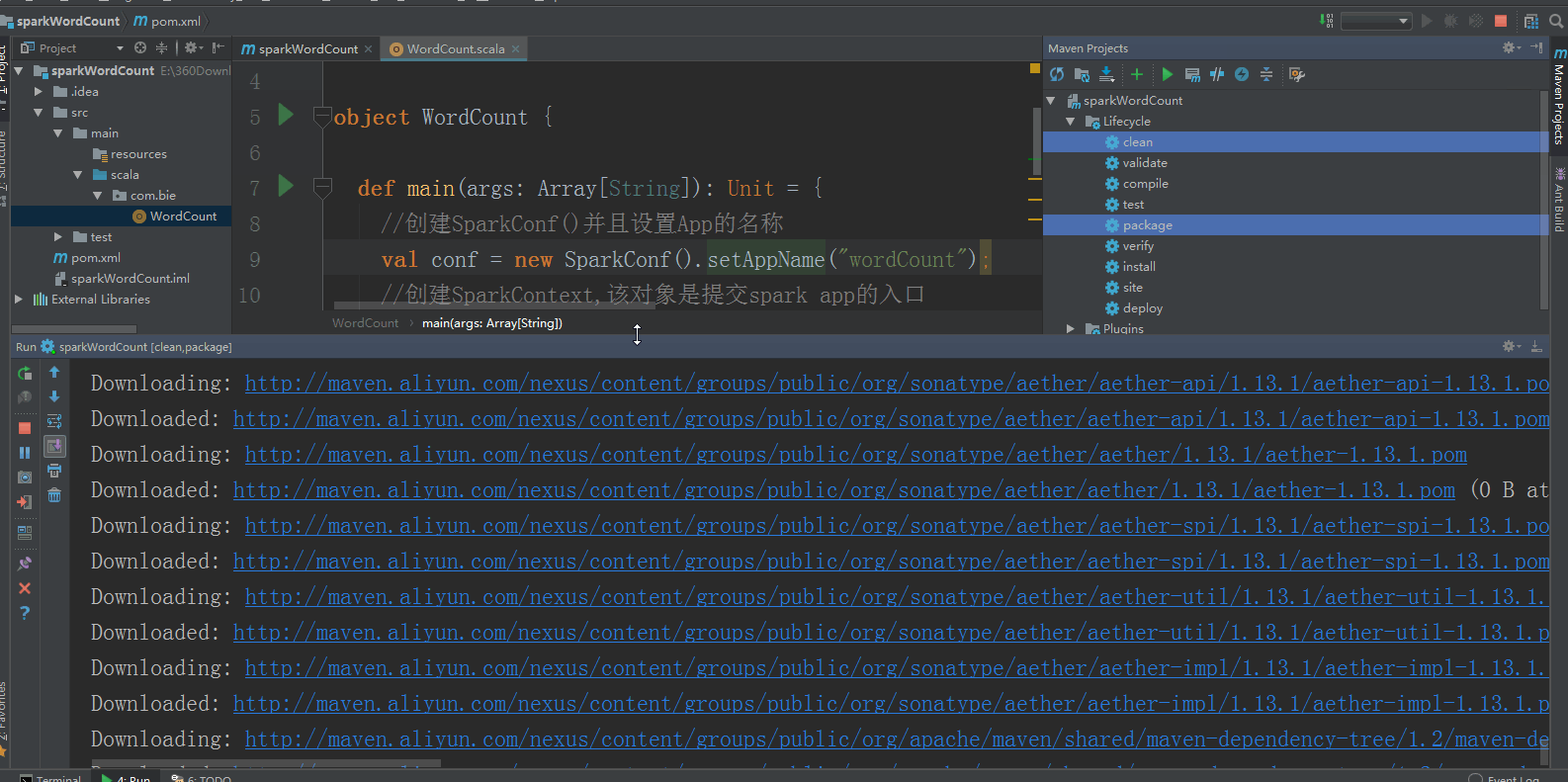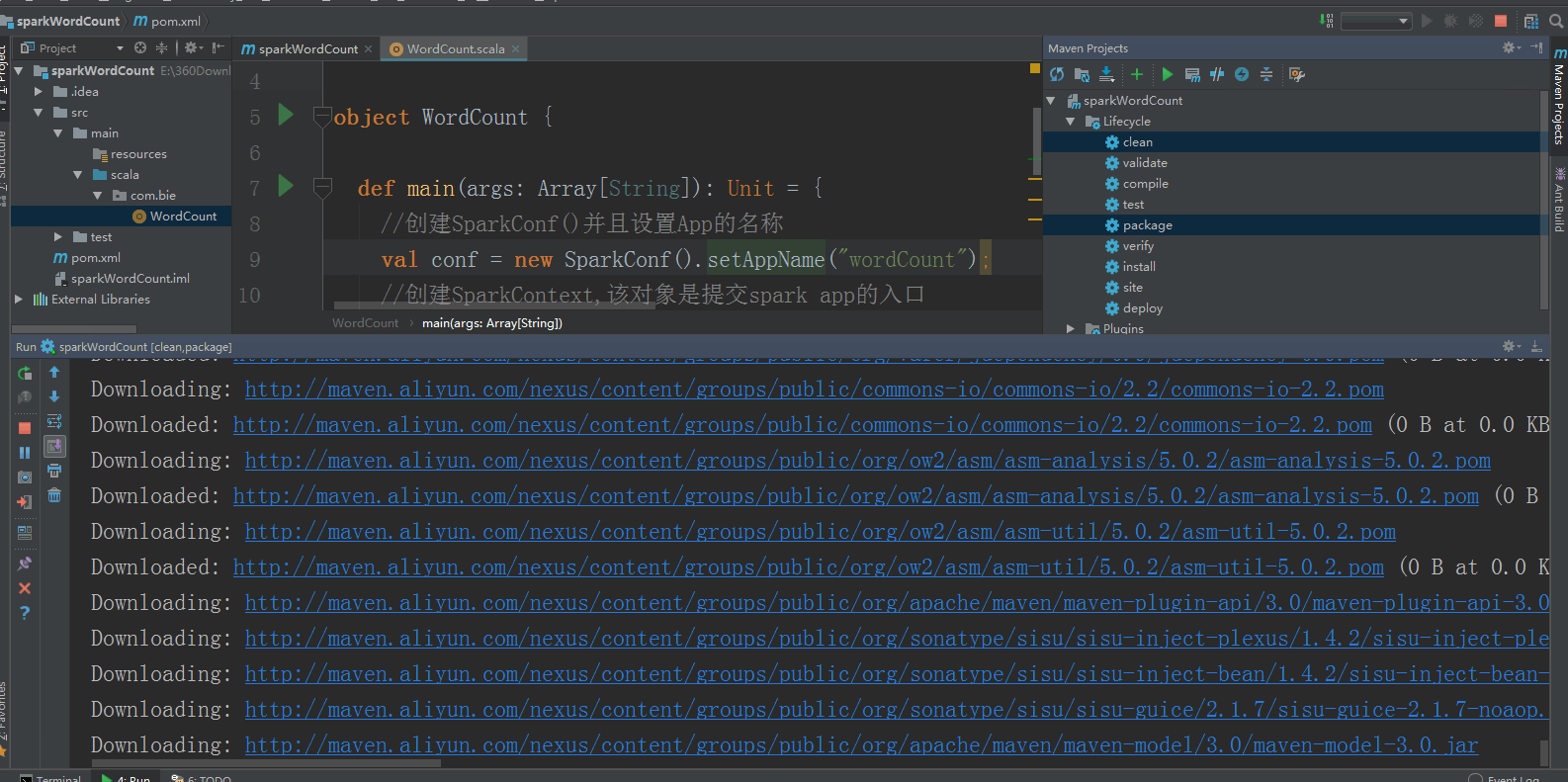
然后,点击idea右侧的Maven Project选项,点击Lifecycle,选择clean和package,然后点击Run Maven Build:
等待编译完成,选择编译成功的jar包,并将该jar上传到Spark集群中的某个节点上:
记得,启动你的hdfs和Spark集群,然后使用spark-submit命令提交Spark应用(注意参数的顺序):
可以看下简单的几行代码,但是打成的包就将近百兆,都是封装好的啊,感觉牛人太多了。

然后开始进行Spark Submit提交操作,命令如下所示:
[root@master spark-1.6.-bin-hadoop2.]# bin/spark-submit \
> --class com.bie.WordCount \
> --master spark://master:7077 \
> --executor-memory 512M \
> --total-executor-cores \
> /home/hadoop/data_hadoop/sparkWordCount-1.0-SNAPSHOT.jar \
> hdfs://master:9000/wordcount.txt \
> hdfs://master:9000/output 或者如下:
bin/spark-submit --class com.bie.WordCount --master spark://master:7077 --executor-memory 512M --total-executor-cores 2 /home/hadoop/data_hadoop/sparkWordCount-1.0-SNAPSHOT.jar hdfs://master:9000/wordcount.txt hdfs://master:9000/outpu
操作如下所示:

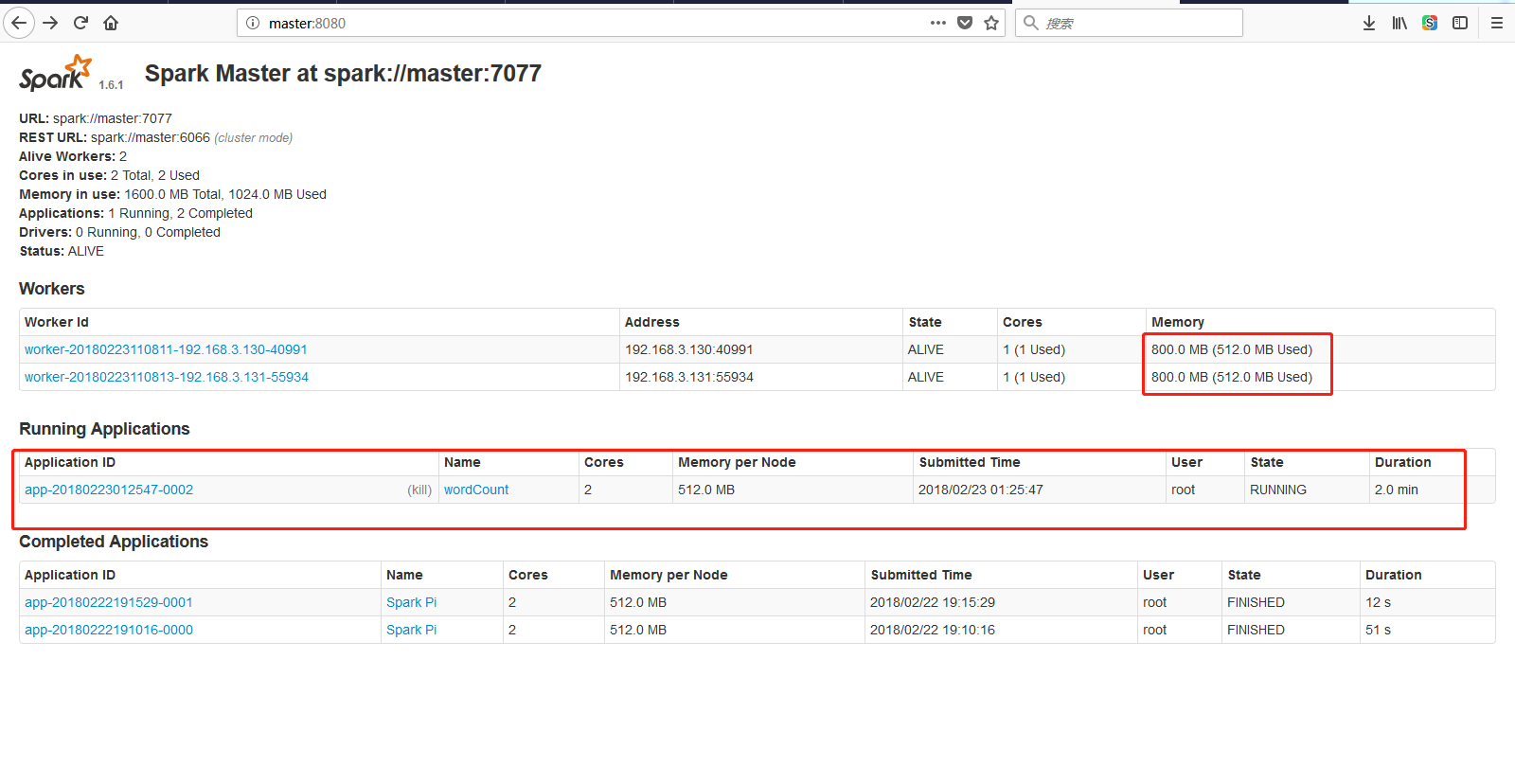
可以在图形化页面看到多了一个Application:
然后呢,就出错了,学知识,不出点错,感觉都不正常:
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [ seconds]. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:)
at org.apache.spark.rpc.RpcEndpointRef.askWithRetry(RpcEndpointRef.scala:)
at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.removeExecutor(CoarseGrainedSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend.executorRemoved(SparkDeploySchedulerBackend.scala:)
at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$receive$.applyOrElse(AppClient.scala:)
at org.apache.spark.rpc.netty.Inbox$$anonfun$process$.apply$mcV$sp(Inbox.scala:)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:)
at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [ seconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:)
at scala.concurrent.Await$$anonfun$result$.apply(package.scala:)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:)
at scala.concurrent.Await$.result(package.scala:)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:)
... more
// :: WARN NettyRpcEndpointRef: Error sending message [message = UpdateBlockInfo(BlockManagerId(driver, 192.168.3.129, ),broadcast_1_piece0,StorageLevel(false, true, false, false, ),,,)] in attempts
org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in seconds. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:)
at scala.util.Failure$$anonfun$recover$.apply(Try.scala:)
at scala.util.Try$.apply(Try.scala:)
at scala.util.Failure.recover(Try.scala:)
at scala.concurrent.Future$$anonfun$recover$.apply(Future.scala:)
at scala.concurrent.Future$$anonfun$recover$.apply(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:)
at scala.concurrent.impl.ExecutionContextImpl$$anon$.execute(ExecutionContextImpl.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at scala.concurrent.Promise$class.complete(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:)
at scala.concurrent.Future$$anonfun$map$.apply(Future.scala:)
at scala.concurrent.Future$$anonfun$map$.apply(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.processBatch$(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply$mcV$sp(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply(Future.scala:)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at scala.concurrent.Promise$class.tryFailure(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$.run(NettyRpcEnv.scala:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in seconds
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$.run(NettyRpcEnv.scala:)
... more // :: WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(,Command exited with code )] in attempts
org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in seconds. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:)
at scala.util.Failure$$anonfun$recover$.apply(Try.scala:)
at scala.util.Try$.apply(Try.scala:)
at scala.util.Failure.recover(Try.scala:)
at scala.concurrent.Future$$anonfun$recover$.apply(Future.scala:)
at scala.concurrent.Future$$anonfun$recover$.apply(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:)
at scala.concurrent.impl.ExecutionContextImpl$$anon$.execute(ExecutionContextImpl.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at scala.concurrent.Promise$class.complete(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:)
at scala.concurrent.Future$$anonfun$map$.apply(Future.scala:)
at scala.concurrent.Future$$anonfun$map$.apply(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.processBatch$(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply$mcV$sp(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply(Future.scala:)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at scala.concurrent.Promise$class.tryFailure(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$.run(NettyRpcEnv.scala:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in seconds
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$.run(NettyRpcEnv.scala:)
... more
// :: WARN NettyRpcEndpointRef: Error sending message [message = UpdateBlockInfo(BlockManagerId(driver, 192.168.3.129, ),broadcast_1_piece0,StorageLevel(false, true, false, false, ),,,)] in attempts
org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in seconds. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$.applyOrElse(RpcTimeout.scala:)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:)
at scala.util.Failure$$anonfun$recover$.apply(Try.scala:)
at scala.util.Try$.apply(Try.scala:)
at scala.util.Failure.recover(Try.scala:)
at scala.concurrent.Future$$anonfun$recover$.apply(Future.scala:)
at scala.concurrent.Future$$anonfun$recover$.apply(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:)
at scala.concurrent.impl.ExecutionContextImpl$$anon$.execute(ExecutionContextImpl.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at scala.concurrent.Promise$class.complete(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:)
at scala.concurrent.Future$$anonfun$map$.apply(Future.scala:)
at scala.concurrent.Future$$anonfun$map$.apply(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.processBatch$(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply$mcV$sp(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$.apply(Future.scala:)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:)
at scala.concurrent.Promise$class.tryFailure(Promise.scala:)
at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:)
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$.run(NettyRpcEnv.scala:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in seconds
at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$.run(NettyRpcEnv.scala:)
... more
解决思路,百度了一下,也没缕出思路,就只知道是连接超时了,超过了120s,然后呢,我感觉是自己内存设置小了,因为开的虚拟机,主机8G,三台虚拟机,每台分了1G内存,然后设置Spark可以占用800M,跑程序的时候,第一次设置为512M,就连接超时了,第二次设置为了700M,顺利跑完,可以看看跑的过程,还是很有意思的:
[root@master hadoop]# bin/spark-submit --class com.bie.WordCount --master spark://master:7077 --executor-memory 700M --total-executor-cores 2 /home/hadoop/data_hadoop/sparkWordCount-1.0-SNAPSHOT.jar hdfs://master:9000/wordcount.txt hdfs://master:9000/output
bash: bin/spark-submit: No such file or directory
[root@master hadoop]# cd spark-1.6.-bin-hadoop2./
[root@master spark-1.6.-bin-hadoop2.]# bin/spark-submit --class com.bie.WordCount --master spark://master:7077 --executor-memory 700M --total-executor-cores 2 /home/hadoop/data_hadoop/sparkWordCount-1.0-SNAPSHOT.jar hdfs://master:9000/wordcount.txt hdfs://master:9000/output
// :: INFO SparkContext: Running Spark version 1.6.
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO SecurityManager: Changing view acls to: root
// :: INFO SecurityManager: Changing modify acls to: root
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
// :: INFO Utils: Successfully started service 'sparkDriver' on port .
// :: INFO Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.3.129:55353]
// :: INFO Utils: Successfully started service 'sparkDriverActorSystem' on port .
// :: INFO SparkEnv: Registering MapOutputTracker
// :: INFO SparkEnv: Registering BlockManagerMaster
// :: INFO DiskBlockManager: Created local directory at /tmp/blockmgr-17e41a67-b880-4c06-95eb-a0f64928f668
// :: INFO MemoryStore: MemoryStore started with capacity 517.4 MB
// :: INFO SparkEnv: Registering OutputCommitCoordinator
// :: INFO Utils: Successfully started service 'SparkUI' on port .
// :: INFO SparkUI: Started SparkUI at http://192.168.3.129:4040
// :: INFO HttpFileServer: HTTP File server directory is /tmp/spark-99c897ab-ea17---3a5df89ed490/httpd-f346e1dd-642d-437d--6190f2e83065
// :: INFO HttpServer: Starting HTTP Server
// :: INFO Utils: Successfully started service 'HTTP file server' on port .
// :: INFO SparkContext: Added JAR file:/home/hadoop/data_hadoop/sparkWordCount-1.0-SNAPSHOT.jar at http://192.168.3.129:35900/jars/sparkWordCount-1.0-SNAPSHOT.jar with timestamp 1519379151547
// :: INFO AppClient$ClientEndpoint: Connecting to master spark://master:7077...
// :: INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app--
// :: INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO NettyBlockTransferService: Server created on
// :: INFO BlockManagerMaster: Trying to register BlockManager
// :: INFO AppClient$ClientEndpoint: Executor added: app--/ on worker--192.168.3.131- (192.168.3.131:) with cores
// :: INFO SparkDeploySchedulerBackend: Granted executor ID app--/ on hostPort 192.168.3.131: with cores, 700.0 MB RAM
// :: INFO AppClient$ClientEndpoint: Executor added: app--/ on worker--192.168.3.130- (192.168.3.130:) with cores
// :: INFO SparkDeploySchedulerBackend: Granted executor ID app--/ on hostPort 192.168.3.130: with cores, 700.0 MB RAM
// :: INFO BlockManagerMasterEndpoint: Registering block manager 192.168.3.129: with 517.4 MB RAM, BlockManagerId(driver, 192.168.3.129, )
// :: INFO BlockManagerMaster: Registered BlockManager
// :: INFO AppClient$ClientEndpoint: Executor updated: app--/ is now RUNNING
// :: INFO AppClient$ClientEndpoint: Executor updated: app--/ is now RUNNING
// :: INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
// :: WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
// :: INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 146.7 KB, free 146.7 KB)
// :: INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 160.6 KB)
// :: INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.3.129: (size: 13.9 KB, free: 517.4 MB)
// :: INFO SparkContext: Created broadcast from textFile at WordCount.scala:
Java HotSpot(TM) Client VM warning: You have loaded library /tmp/libnetty-transport-native-epoll4006421548933729587.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
// :: INFO SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (slaver1:) with ID
// :: INFO BlockManagerMasterEndpoint: Registering block manager slaver1: with 282.5 MB RAM, BlockManagerId(, slaver1, )
// :: INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
// :: INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
// :: INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
// :: INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
// :: INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
// :: INFO SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (slaver2:) with ID
// :: INFO SparkContext: Starting job: saveAsTextFile at WordCount.scala:
// :: INFO FileInputFormat: Total input paths to process :
// :: INFO BlockManagerMasterEndpoint: Registering block manager slaver2: with 282.5 MB RAM, BlockManagerId(, slaver2, )
// :: INFO DAGScheduler: Registering RDD (map at WordCount.scala:)
// :: INFO DAGScheduler: Registering RDD (sortBy at WordCount.scala:)
// :: INFO DAGScheduler: Got job (saveAsTextFile at WordCount.scala:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (saveAsTextFile at WordCount.scala:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at map at WordCount.scala:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 164.7 KB)
// :: INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 167.0 KB)
// :: INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.3.129: (size: 2.3 KB, free: 517.4 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at map at WordCount.scala:)
// :: INFO TaskSchedulerImpl: Adding task set 0.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID , slaver2, partition ,NODE_LOCAL, bytes)
// :: INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID , slaver1, partition ,NODE_LOCAL, bytes)
// :: INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on slaver1: (size: 2.3 KB, free: 282.5 MB)
// :: INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on slaver1: (size: 13.9 KB, free: 282.5 MB)
// :: INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on slaver2: (size: 2.3 KB, free: 282.5 MB)
// :: INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on slaver2: (size: 13.9 KB, free: 282.5 MB)
// :: INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID ) in ms on slaver1 (/)
// :: INFO DAGScheduler: ShuffleMapStage (map at WordCount.scala:) finished in 140.390 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID ) in ms on slaver2 (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: waiting: Set(ShuffleMapStage , ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at sortBy at WordCount.scala:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.5 KB, free 170.5 KB)
// :: INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.0 KB, free 172.5 KB)
// :: INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.3.129: (size: 2.0 KB, free: 517.4 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at sortBy at WordCount.scala:)
// :: INFO TaskSchedulerImpl: Adding task set 1.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID , slaver2, partition ,NODE_LOCAL, bytes)
// :: INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on slaver2: (size: 2.0 KB, free: 282.5 MB)
// :: INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle to slaver2:
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO DAGScheduler: ShuffleMapStage (sortBy at WordCount.scala:) finished in 0.708 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at saveAsTextFile at WordCount.scala:), which has no missing parents
// :: INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID ) in ms on slaver2 (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
// :: INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 65.1 KB, free 237.6 KB)
// :: INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 22.6 KB, free 260.2 KB)
// :: INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.3.129: (size: 22.6 KB, free: 517.4 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at saveAsTextFile at WordCount.scala:)
// :: INFO TaskSchedulerImpl: Adding task set 2.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID , slaver2, partition ,NODE_LOCAL, bytes)
// :: INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on slaver2: (size: 22.6 KB, free: 282.5 MB)
// :: INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle to slaver2:
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO DAGScheduler: ResultStage (saveAsTextFile at WordCount.scala:) finished in 5.008 s
// :: INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID ) in ms on slaver2 (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: Job finished: saveAsTextFile at WordCount.scala:, took 147.737606 s
// :: INFO SparkUI: Stopped Spark web UI at http://192.168.3.129:4040
// :: INFO SparkDeploySchedulerBackend: Shutting down all executors
// :: INFO SparkDeploySchedulerBackend: Asking each executor to shut down
// :: INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: INFO MemoryStore: MemoryStore cleared
// :: INFO BlockManager: BlockManager stopped
// :: INFO BlockManagerMaster: BlockManagerMaster stopped
// :: INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
// :: INFO SparkContext: Successfully stopped SparkContext
// :: INFO ShutdownHookManager: Shutdown hook called
// :: INFO ShutdownHookManager: Deleting directory /tmp/spark-99c897ab-ea17---3a5df89ed490
// :: INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
// :: INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
// :: INFO ShutdownHookManager: Deleting directory /tmp/spark-99c897ab-ea17---3a5df89ed490/httpd-f346e1dd-642d-437d--6190f2e83065
[root@master spark-1.6.-bin-hadoop2.]#
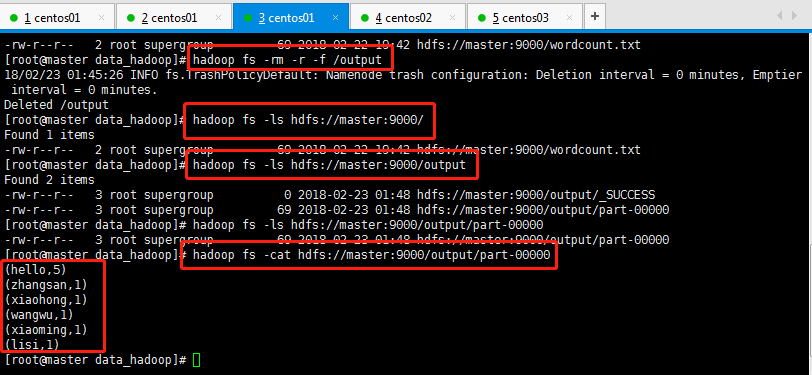
最后查看执行结果即可(由于第一次跑失败了,作为强迫症的我就把第一次的输出结果文件删除了):
在IDEA中编写Spark的WordCount程序的更多相关文章
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 【未完成】[Spark SQL_2] 在 IDEA 中编写 Spark SQL 程序
0. 说明 在 IDEA 中编写 Spark SQL 程序,分别编写 Java 程序 & Scala 程序 1. 编写 Java 程序 待补充 2. 编写 Scala 程序 待补充
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 如何在KEIL中编写模块化的C程序
在KEIL中的模块化程序写法在使用KEIL的时候,我们习惯上在一个.c的文件中把自己要写的东西按照自己思路的顺序进行顺序书写.这样是很普遍的写法,当程序比较短的时候比如几十行或者一百多行,是没有什么问 ...
- spark运行wordcount程序
首先提一下spark rdd的五大核心特性: 1.rdd由一系列的分片组成,比如说128m一片,类似于hadoop中的split2.每一个分区都有一个函数去迭代/运行/计算3.一系列的依赖,比如:rd ...
- Spark开发wordcount程序
1.java版本(spark-2.1.0) package chavin.king; import org.apache.spark.api.java.JavaSparkContext; import ...
- 用IDEA编写spark的WordCount
我习惯用Maven项目 所以用IDEA新建一个Maven项目 下面是pom文件 我粘上来吧 <?xml version="1.0" encoding="UTF-8& ...
随机推荐
- V4L2开发要点【转】
转自:https://blog.csdn.net/mr_raptor/article/details/7441141 首先来看 Read/Write ,如果 VIDIOC_QUERYCAP 调用返回的 ...
- 题解-拉格朗日(bzoj3695变种)
Problem 在无穷大的水平面上有一个平面直角坐标系,\(N-1\)条垂直于\(x\)轴的直线将空间分为了\(N\)个区域 你被要求把\((0,0)\)处的箱子匀速推到\((x,y)\) 箱子受水平 ...
- html5 - drag 拖拽
参考资料: 张鑫旭 : http://www.zhangxinxu.com/wordpress/2011/02/html5-drag-drop-%E6%8B%96%E6%8B% ...
- PHP header 允许跨域请求
2018-1-29 17:36:14 星期一 header('Access-Control-Allow-Origin:*'); header('Access-Control-Allow-Methods ...
- Python2018-字符串中字符个数统计
1 编写程序,完成以下要求: 统计字符串中,各个字符的个数 比如:"hello world" 字符串统计的结果为: h:1 e:1 l:3 o:2 d:1 r:1 w:1 prin ...
- 如何:配置 ClickOnce 信任提示行为
转载链接:https://technet.microsoft.com/zh-cn/magazine/ee308453 可以配置 ClickOnce 信任提示以控制是否允许最终用户选择安装 ClickO ...
- linux /proc目录
1. /proc目录Linux 内核提供了一种通过 /proc 文件系统,在运行时访问内核内部数据结构.改变内核设置的机制.proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间.它以文 ...
- [C][代码实例]整型数组二分排序
#include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include <string.h& ...
- Day6------------软连接和硬链接
一.块 1.操作系统分四大类块 super block 掌管全局 inode block directory block block 2.删文件 普通删除只是删除链接,数据还在硬盘 彻底删除:覆盖操作 ...
- ORA-00257: archiver error. Connect internal only, until freed.| Oracle数据库归档日志满导致应用系统反应缓慢的问题处理
一:查看原因 查看了下V$FLASH_RECOVERY_AREA_USAGE,看看归档目录使用的情况.果然是归档满了. Disconnected from Oracle Database 11g En ...