基于开源中文分词工具pkuseg-python,我用张小龙的3万字演讲做了测试
做过搜索的同学都知道,分词的好坏直接决定了搜索的质量,在英文中分词比中文要简单,因为英文是一个个单词通过空格来划分每个词的,而中文都一个个句子,单独一个汉字没有任何意义,必须联系前后文字才能正确表达它的意思。
因此,中文分词技术一直是nlp领域中的一大挑战。Python 中有个比较著名的分词库是结巴分词,从易用性来说对用户是非常友好的,但是准确度不怎么好。这几天发现另外一个库,pkuseg-python,看起来应该是北大的某个学生团队弄出来的,因为这方面没看到过多的介绍,pkuseg-python 的亮点是领域细分的中文分词工具,简单易用,跟现有开源工具相比提高了分词的准确率。
于是我想起用张小龙的3万字演讲做下测试,前几天在朋友圈流传了一张图,采铜统计出张小龙演讲中各个词出现的频率,不知他是怎么统计的,不过作为技术人,我们用更专业的工具来试试会是什么效果。
安装 pkuseg
pip3 install pkuseg
第一步是将演讲内容下载下来,保存到一个txt文件中,然后将内容加载到内存
content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read()
我统计了一下,文字总数是32546个。
接下来我们用pkuseg对内容进行分词处理,并统计出现频率最高的前20个词语是哪些。
import pkuseg
from collections import Counter
import pprint content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read() seg = pkuseg.pkuseg()
text = seg.cut(content)
counter = Counter(text)
pprint.pprint(counter.most_common(20))
输出结果:
[(',', 1445),
('的', 1378),
('。', 755),
('是', 707),
('一', 706),
('个', 591),
('我', 337),
('我们', 335),
('不', 279),
('你', 231),
('在', 230),
('会', 220),
('了', 214),
('有', 197),
('人', 190),
('就', 178),
('这', 172),
('它', 170),
('微信', 163),
('做', 149)]
什么鬼,这都是些啥玩意,别急,其实啊,分词领域还有一个概念叫做停用词,所谓停用词就是在语境中没有具体含义的文字,例如这个、那个,你我他,的得地,以及标点符合等等。因为没人在搜索的时候去用这些没意义的停用词搜索,为了使得分词效果更好,我们就要把这些停用词过去掉,我们去网上找个停用词库。
第二版代码:
import pkuseg
from collections import Counter
import pprint content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read() seg = pkuseg.pkuseg()
text = seg.cut(content) stopwords = [] with open("stopword.txt", encoding="utf-8") as f:
stopwords = f.read() new_text = [] for w in text:
if w not in stopwords:
new_text.append(w) counter = Counter(new_text)
pprint.pprint(counter.most_common(20))
打印的结果:
[('微信', 163),
('用户', 112),
('产品', 89),
('朋友', 81),
('工具', 56),
('程序', 55),
('社交', 55),
('圈', 47),
('视频', 40),
('希望', 39),
('时间', 39),
('游戏', 36),
('阅读', 33),
('内容', 32),
('平台', 31),
('文章', 30),
('信息', 29),
('团队', 27),
('AI', 27),
('APP', 26)]
看起来比第一次好多了,因为停用词都过滤掉了,跟采铜那张图片有点像了,不过他挑出来的词可能是从另外一个维度来的,毕竟人家是搞心理学的。但是我们选出来的前20个高频词还是不准确,有些不应该分词的也被拆分了,例如朋友圈,公众号,小程序等词,我们认为这是一个整体。
对于这些专有名词,我们只需要指定一个用户词典, 分词时用户词典中的词固定不分开,重新进行分词。
lexicon = ['小程序', '朋友圈', '公众号'] #
seg = pkuseg.pkuseg(user_dict=lexicon) # 加载模型,给定用户词典
text = seg.cut(content)
最后的出来的结果前50个高频词是这样的
163 微信
112 用户
89 产品
72 朋友圈
56 工具
55 社交
53 小程序
40 视频
39 希望
39 时间
36 游戏
33 阅读
32 内容
31 朋友
31 平台
30 文章
29 信息
27 团队
27 AI
26 APP
25 公众号
25 服务
24 好友
22 照片
21 时代
21 记录
20 手机
20 推荐
20 企业
19 原动力
18 功能
18 真实
18 生活
17 流量
16 电脑
15 空间
15 发现
15 创意
15 体现
15 公司
15 价值
14 版本
14 分享
14 未来
13 互联网
13 发布
13 能力
13 讨论
13 动态
12 设计
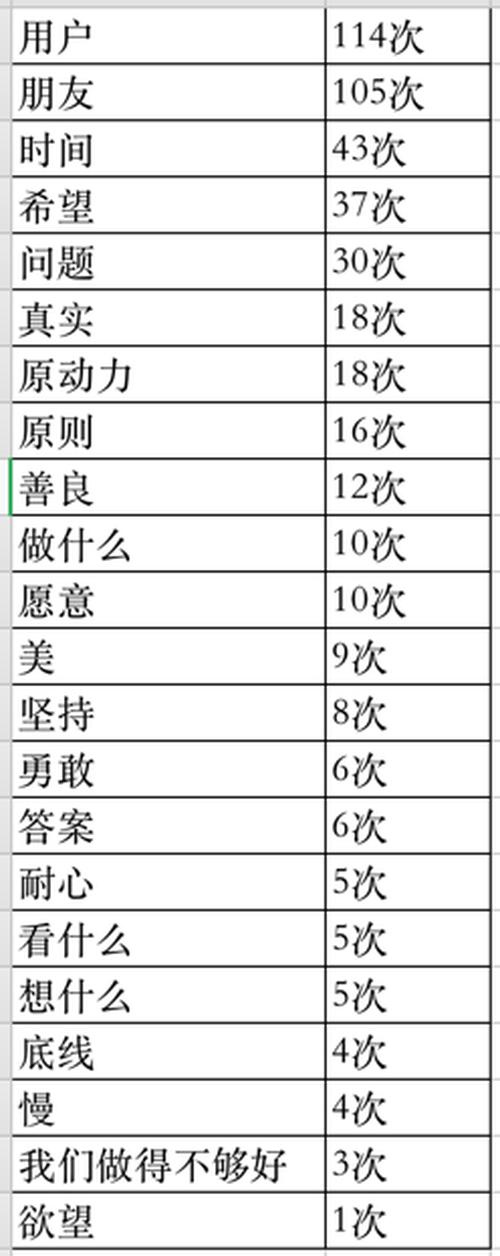
张小龙讲得最多的词就是用户、朋友、原动力、价值、分享、创意、发现等这些词,这些词正是互联网的精神,如果我们把这些做成词云的话,可能效果会更好

代码传送门:https://github.com/lzjun567/crawler_html2pdf/tree/master/fencitongji
基于开源中文分词工具pkuseg-python,我用张小龙的3万字演讲做了测试的更多相关文章
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
- 开源中文分词工具探析(六):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
随机推荐
- SpringBoot快速入门01--环境搭建
SpringBoot快速入门--环境搭建 1.创建web工程 1.1 创建新的工程. 1.2 选择maven工程,点击下一步. 1.3 填写groupid(maven的项目名称)和artifacti ...
- 从0系统学Android--1.2 手把手带你搭建开发环境
要想进行程序开发,首先我们需要搭建开发环境,下面就开始搭建环境. 1.2.1 所需的工具 首先 Android 开发是基于 Java 的,因此你需要掌握简单的 Java 语法.会基础的 Java 语法 ...
- 个人永久性免费-Excel催化剂功能第59波-快速调用Windows内部常用工具命令
Windows里一些常用的工具.命令,许多存放得很深的位置,不容易找到,每次还要百度半天才能调用成功,Excel催化剂现将常用的操作,提取至插件中完成,一键即可调出相应功能,无需苦苦找寻. 使用场景 ...
- python迭代器-迭代器取值-for循环-生成器-yield-生成器表达式-常用内置方法-面向过程编程-05
迭代器 迭代器 迭代: # 更新换代(其实也是重复)的过程,每一次的迭代都必须基于上一次的结果(上一次与这一次之间必须是有关系的) 迭代器: # 迭代取值的工具 为什么用迭代器: # 迭代器提供了一种 ...
- TP框架基础 (二) ---空控制器和空操作
通过之前的学习我们知道了index.php是一个入口文件,如果没有这个入口文件的话,我们需要自己创建! [视图模板文件创建] 视图模板文件存放发位置在: 里面没有模板文件 如果我们想要访问Login控 ...
- linux初学者-DDNS配置篇
linux初学者-DDNS配置篇 如果DNS服务器要记录多台主机的IP,且这些主机的IP都是通过DHCPD服务自动获取的,那么将会造成很大的困难,因为在DNS设置时无法得知主机具体的IP.如果DHCP ...
- MYSQL A、B表数组关联查询
最终结果: 数据库表 A表: B表: 操作步骤 主要关键字:FIND_IN_SET.GROUP_CONCAT.LEFT JOIN.GROUP BY 第一步:left join 连接AB表并通过 fin ...
- 配置没有问题,虚拟机Ubuntu系统ifconfig没有网卡信息
如果没有问题,前几天都好好的,突然出现这个问题 sudo ifconfig etho up 其中eth0是我的网卡名称
- ASP.NET Core Web Api之JWT刷新Token(三)
前言 如题,本节我们进入JWT最后一节内容,JWT本质上就是从身份认证服务器获取访问令牌,继而对于用户后续可访问受保护资源,但是关键问题是:访问令牌的生命周期到底设置成多久呢?见过一些使用JWT的童鞋 ...
- 自定义SWT控件三之搜索功能下拉框
3.搜索功能下拉弹出框 package com.view.control.select; import java.util.ArrayList; import java.util.LinkedList ...