[Flink]Flink1.6三种运行模式安装部署以及实现WordCount
前言
Flink三种运行方式:Local、Standalone、On Yarn。成功部署后分别用Scala和Java实现wordcount
环境
版本:Flink 1.6.2
集群环境:Hadoop2.6
开发工具: IntelliJ IDEA
一.Local模式
解压:tar -zxvf flink-1.6.2-bin-hadoop26-scala_2.11.tgz
cd flink-1.6.2
启动:./bin/start-cluster.sh
停止:./bin/stop-cluster.sh
可以通过master:8081监控集群状态
二.Standalone模式
集群安装
1:修改conf/flink-conf.yaml
jobmanager.rpc.address: hadoop100
2:修改conf/slaves
hadoop101
hadoop102
3:拷贝到其他节点
scp -rq /usr/local/flink-1.6.2 hadoop101:/usr/local
scp -rq /usr/local/flink-1.6.2 hadoop102:/usr/local
4:在hadoop100(master)节点启动
bin/start-cluster.sh
5:访问http://hadoop100:8081
三.Flink On Yarn模式
On Yarn实现逻辑
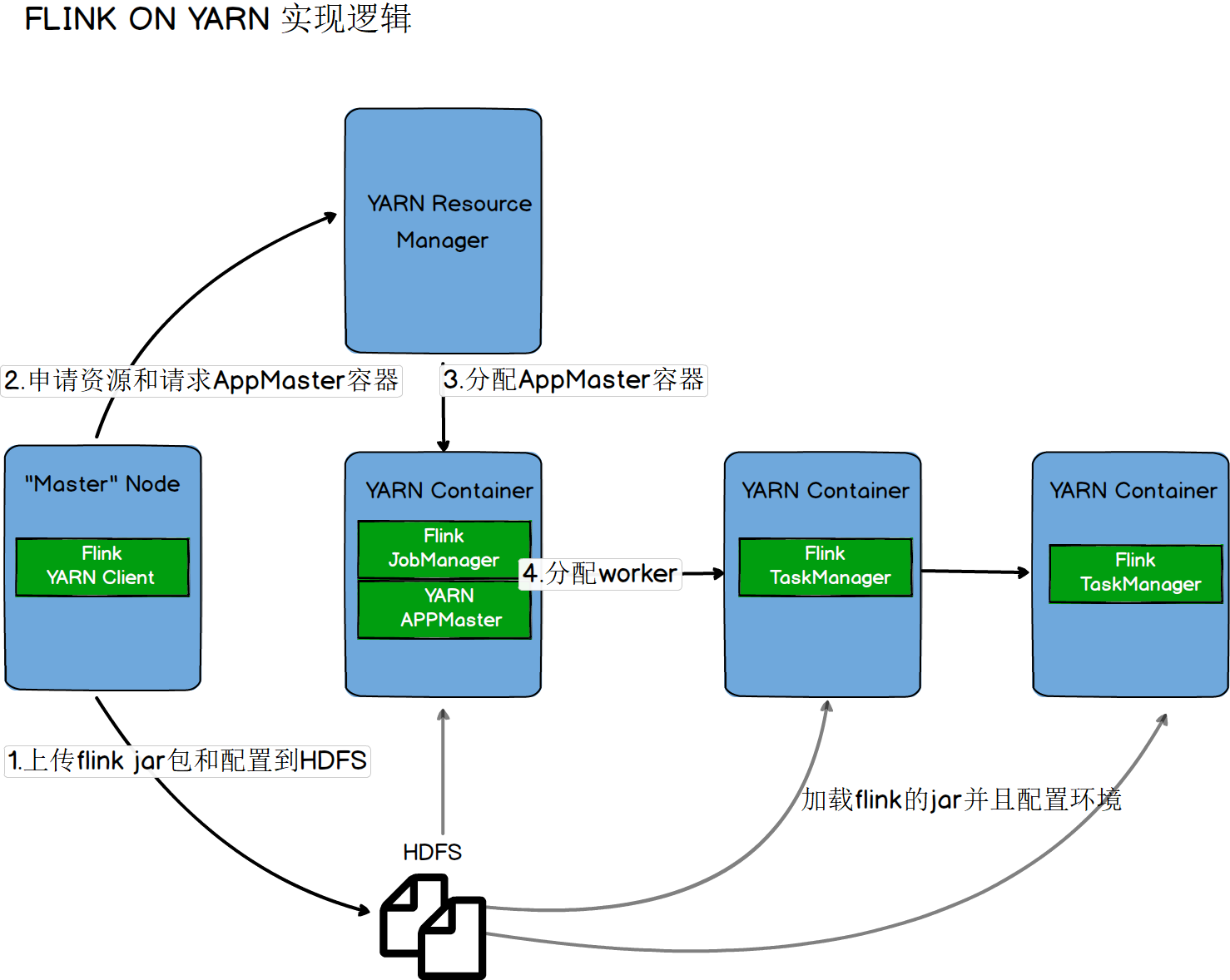
##### 第一种【yarn-session.sh(开辟资源)+flink run(提交任务)】
启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 [-d]
附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0029
执行任务
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hadoop100:9000/LICENSE -output hdfs://hadoop100:9000/wordcount-result.txt
停止任务 【web界面或者命令行执行cancel命令】
##### 第二种【flink run -m yarn-cluster(开辟资源+提交任务)】
启动集群,执行任务
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
注意:client端必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_HOME环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败
四.WordCount
代码
Scala实现代码
package com.skyell
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 滑动窗口计算
*
* 每隔1秒统计最近2秒数据,打印到控制台
*/
object SocketWindowWordCountScala {
def main(args: Array[String]): Unit = {
// 获取socket端口号
val port: Int = try{
ParameterTool.fromArgs(args).getInt("port")
}catch {
case e: Exception => {
System.err.println("No port set use default port 9002--scala")
}
9002
}
// 获取运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 连接socket获取数据
val text = env.socketTextStream("master", port, '\n')
//添加隐式转换,否则会报错
import org.apache.flink.api.scala._
// 解析数据(把数据打平),分组,窗口计算,并且聚合求sum
val windowCount = text.flatMap(line => line.split("\\s"))
.map(w => WordWithCount(w, 1))
.keyBy("word") // 针对相同word进行分组
.timeWindow(Time.seconds(2), Time.seconds(1))// 窗口时间函数
.sum("count")
windowCount.print().setParallelism(1) // 设置并行度为1
env.execute("Socket window count")
}
// case 定义的类可以直接调用,不用new
case class WordWithCount(word:String,count: Long)
}
Java实现代码
package com.skyell;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCountJava {
public static void main(String[] args) throws Exception{
String inputPath = "D:\\DATA\\file";
String outPath = "D:\\DATA\\result";
// 获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 读取本地文件中内容
DataSource<String> text = env.readTextFile(inputPath);
// groupBy(0):从0聚合 sum(1):以第二个字段加和计算
DataSet<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).groupBy(0).sum(1);
counts.writeAsCsv(outPath, "\n", " ").setParallelism(1);
env.execute("batch word count");
}
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String,Integer>>{
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token: tokens
) {
if(token.length()>0){
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
pom依赖配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
[Flink]Flink1.6三种运行模式安装部署以及实现WordCount的更多相关文章
- hadoop记录-[Flink]Flink三种运行模式安装部署以及实现WordCount(转载)
[Flink]Flink三种运行模式安装部署以及实现WordCount 前言 Flink三种运行方式:Local.Standalone.On Yarn.成功部署后分别用Scala和Java实现word ...
- ubuntu上Hadoop三种运行模式的部署
Hadoop集群支持三种运行模式:单机模式.伪分布式模式,全分布式模式,下面介绍下在Ubuntu下的部署 (1)单机模式 默认情况下,Hadoop被配置成一个以非分布式模式运行的独立JAVA进程,适合 ...
- Tomcat Connector的三种运行模式
详情参考: http://tomcat.apache.org/tomcat-7.0-doc/apr.html http://www.365mini.com/page/tomcat-connector- ...
- 【Tomcat】Tomcat Connector的三种运行模式【bio、nio、apr】
Tomcat Connector(Tomcat连接器)有bio.nio.apr三种运行模式 bio bio(blocking I/O,阻塞式I/O操作),表示Tomcat使用的是传统的Java I/O ...
- PHP语言学习之php-fpm 三种运行模式
本文主要向大家介绍了PHP语言学习之php-fpm 三种运行模式,通过具体的内容向大家展示,希望对大家学习php语言有所帮助. php-fpm配置 配置文件:php-fpm.conf 开启慢日志功能的 ...
- Tomcat Connector三种运行模式(BIO, NIO, APR)的比较和优化
Tomcat Connector的三种不同的运行模式性能相差很大,有人测试过的结果如下: 这三种模式的不同之处如下: BIO: 一个线程处理一个请求.缺点:并发量高时,线程数较多,浪费资源. Tomc ...
- Tomcat Connector(BIO, NIO, APR)三种运行模式(转)
Tomcat支持三种接收请求的处理方式:BIO.NIO.APR . BIO 阻塞式I/O操作即使用的是传统 I/O操作,Tomcat7以下版本默认情况下是以BIO模式运行的,由于每个请求都要创建一个线 ...
- php-fpm 三种运行模式
php-fpm配置 配置文件:php-fpm.conf 开启慢日志功能的: slowlog = /usr/local/var/log/php-fpm.log.slowrequest_slowlog_t ...
- python编程(python开发的三种运行模式)【转】
转自:http://blog.csdn.net/feixiaoxing/article/details/53980886 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 单循环 ...
随机推荐
- ARP攻击原理简析及防御措施
0x1 简介 网络欺骗攻击作为一种非常专业化的攻击手段,给网络安全管理者,带来严峻的考验.网络安全的战场已经从互联网蔓延到用户内部的网络, 特别是局域网.目前利用ARP欺骗的木马病毒在局域网中广泛传 ...
- 【SQL】 收入支出求盈亏
求项目ID为1000的盈亏 表名为:T 字段:ID P_ID AMOUNT TYPE(1:收入 2:支出) '
- WebSocket协议与抓包
WebSocket协议 WebSocket并不是全新的协议,而是利用了HTTP协议来建立连接,它的目的是在浏览器和服务器之间建立一个不受限的双向通信的通道,比如说,服务器可以在任意时刻发送消息给浏览器 ...
- 索引的底层实现(B 树)
一.B 树 1.B-Tree介绍 B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点:重复,直到所对应的儿子指针为空,或已经是叶 ...
- [JLOI2014]天天酷跑
请允许我对记忆化搜索进行一个总结,我认为所有的搜索只要数据范围允许,都可以转化为记忆化搜索, 只是,用处的多与少的关系,其本身是求出设出状态之后,为求出当前状态进行递推(搜索),推到 已知状态,之后再 ...
- 设计模式常见面试知识点总结(Java版)
设计模式 这篇总结主要是基于我设计模式系列的文章而形成的的.主要是把重要的知识点用自己的话说了一遍,可能会有一些错误,还望见谅和指点.谢谢 更多详细内容可以到我的cdsn博客上查看: https:// ...
- NOIP_TG
本博客主要记录一些在刷题的途中遇到的一些巧妙的题目 砝码称重 一开始想到可以DP递推标记能凑成的数量 但发现同一种砝码可能有多个于是想多开一维状态存当前还剩多少砝码 真是愚蠢至极 直接把所有砝码单独看 ...
- 零基础转行web前端,如何高效的去学习web前端
web前端开发要学的知识内容涉及的会很宽泛,虽然说主要是HTML.CSS和JavaScript这些基础知识点,但学前端开发除了要学这些基础知识外,学员还要在这之上进行延伸和深入的去学,而且互联网时代不 ...
- USART_FLAG_TXE和USART_FLAG_TC
在串口数据发送操作中,代码一般是这样写的: void USART_SendByte(USART_TypeDef* USARTx, uint8_t Data) { while(USART_GetFlag ...
- Cobalt Strike之信息收集、木马钓鱼
System Profiler使用 System Profiler 模块,搜集目标的各类机器信息(操作系统版本,浏览器版本等) Attacks->web drive-by->System ...