[Flink]Flink1.6三种运行模式安装部署以及实现WordCount
前言
Flink三种运行方式:Local、Standalone、On Yarn。成功部署后分别用Scala和Java实现wordcount
环境
版本:Flink 1.6.2
集群环境:Hadoop2.6
开发工具: IntelliJ IDEA
一.Local模式
解压:tar -zxvf flink-1.6.2-bin-hadoop26-scala_2.11.tgz
cd flink-1.6.2
启动:./bin/start-cluster.sh
停止:./bin/stop-cluster.sh
可以通过master:8081监控集群状态
二.Standalone模式
集群安装
1:修改conf/flink-conf.yaml
jobmanager.rpc.address: hadoop100
2:修改conf/slaves
hadoop101
hadoop102
3:拷贝到其他节点
scp -rq /usr/local/flink-1.6.2 hadoop101:/usr/local
scp -rq /usr/local/flink-1.6.2 hadoop102:/usr/local
4:在hadoop100(master)节点启动
bin/start-cluster.sh
5:访问http://hadoop100:8081
三.Flink On Yarn模式
On Yarn实现逻辑
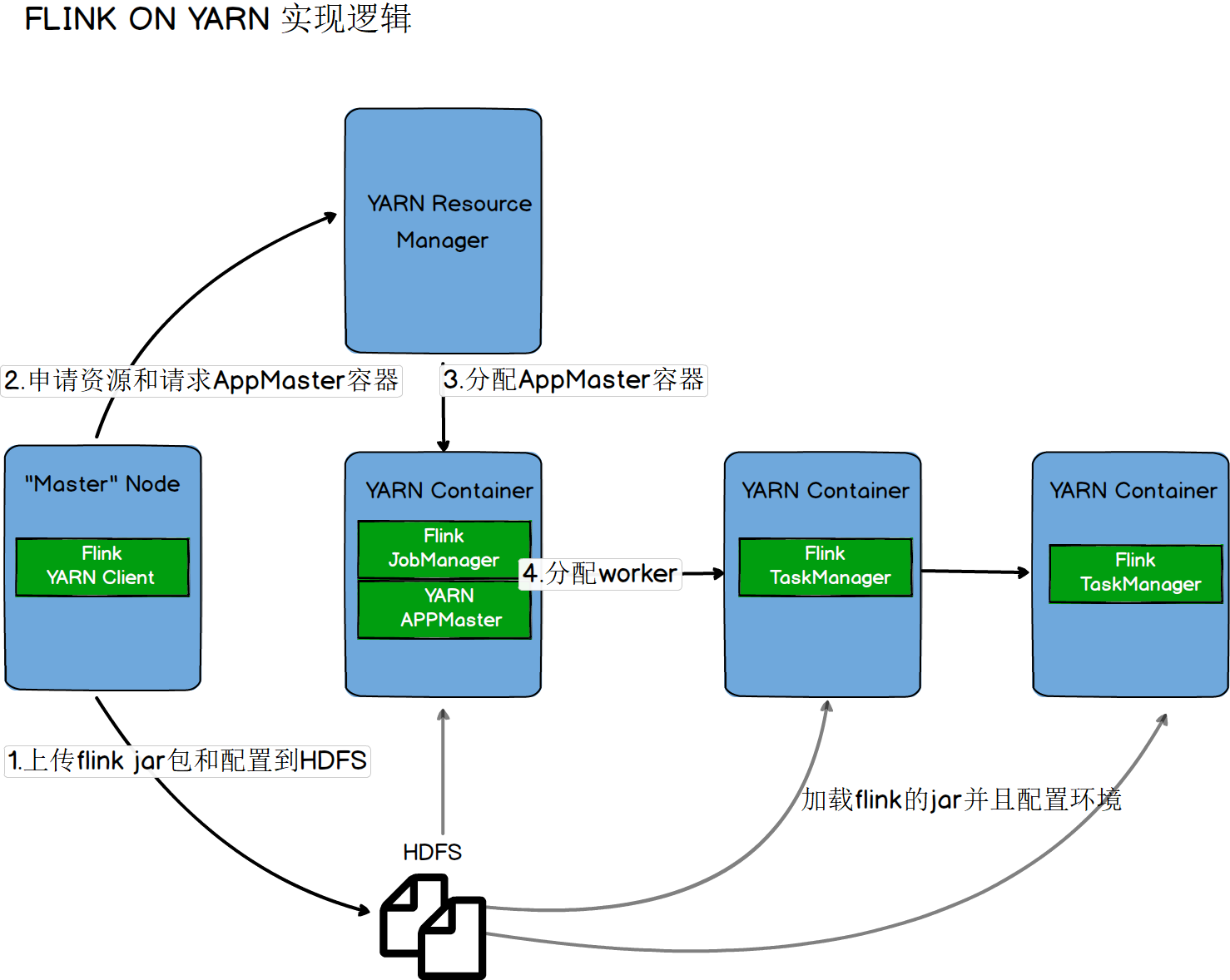
##### 第一种【yarn-session.sh(开辟资源)+flink run(提交任务)】
启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 [-d]
附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0029
执行任务
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hadoop100:9000/LICENSE -output hdfs://hadoop100:9000/wordcount-result.txt
停止任务 【web界面或者命令行执行cancel命令】
##### 第二种【flink run -m yarn-cluster(开辟资源+提交任务)】
启动集群,执行任务
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
注意:client端必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_HOME环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败
四.WordCount
代码
Scala实现代码
package com.skyell
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 滑动窗口计算
*
* 每隔1秒统计最近2秒数据,打印到控制台
*/
object SocketWindowWordCountScala {
def main(args: Array[String]): Unit = {
// 获取socket端口号
val port: Int = try{
ParameterTool.fromArgs(args).getInt("port")
}catch {
case e: Exception => {
System.err.println("No port set use default port 9002--scala")
}
9002
}
// 获取运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 连接socket获取数据
val text = env.socketTextStream("master", port, '\n')
//添加隐式转换,否则会报错
import org.apache.flink.api.scala._
// 解析数据(把数据打平),分组,窗口计算,并且聚合求sum
val windowCount = text.flatMap(line => line.split("\\s"))
.map(w => WordWithCount(w, 1))
.keyBy("word") // 针对相同word进行分组
.timeWindow(Time.seconds(2), Time.seconds(1))// 窗口时间函数
.sum("count")
windowCount.print().setParallelism(1) // 设置并行度为1
env.execute("Socket window count")
}
// case 定义的类可以直接调用,不用new
case class WordWithCount(word:String,count: Long)
}
Java实现代码
package com.skyell;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCountJava {
public static void main(String[] args) throws Exception{
String inputPath = "D:\\DATA\\file";
String outPath = "D:\\DATA\\result";
// 获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 读取本地文件中内容
DataSource<String> text = env.readTextFile(inputPath);
// groupBy(0):从0聚合 sum(1):以第二个字段加和计算
DataSet<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).groupBy(0).sum(1);
counts.writeAsCsv(outPath, "\n", " ").setParallelism(1);
env.execute("batch word count");
}
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String,Integer>>{
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token: tokens
) {
if(token.length()>0){
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
pom依赖配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
[Flink]Flink1.6三种运行模式安装部署以及实现WordCount的更多相关文章
- hadoop记录-[Flink]Flink三种运行模式安装部署以及实现WordCount(转载)
[Flink]Flink三种运行模式安装部署以及实现WordCount 前言 Flink三种运行方式:Local.Standalone.On Yarn.成功部署后分别用Scala和Java实现word ...
- ubuntu上Hadoop三种运行模式的部署
Hadoop集群支持三种运行模式:单机模式.伪分布式模式,全分布式模式,下面介绍下在Ubuntu下的部署 (1)单机模式 默认情况下,Hadoop被配置成一个以非分布式模式运行的独立JAVA进程,适合 ...
- Tomcat Connector的三种运行模式
详情参考: http://tomcat.apache.org/tomcat-7.0-doc/apr.html http://www.365mini.com/page/tomcat-connector- ...
- 【Tomcat】Tomcat Connector的三种运行模式【bio、nio、apr】
Tomcat Connector(Tomcat连接器)有bio.nio.apr三种运行模式 bio bio(blocking I/O,阻塞式I/O操作),表示Tomcat使用的是传统的Java I/O ...
- PHP语言学习之php-fpm 三种运行模式
本文主要向大家介绍了PHP语言学习之php-fpm 三种运行模式,通过具体的内容向大家展示,希望对大家学习php语言有所帮助. php-fpm配置 配置文件:php-fpm.conf 开启慢日志功能的 ...
- Tomcat Connector三种运行模式(BIO, NIO, APR)的比较和优化
Tomcat Connector的三种不同的运行模式性能相差很大,有人测试过的结果如下: 这三种模式的不同之处如下: BIO: 一个线程处理一个请求.缺点:并发量高时,线程数较多,浪费资源. Tomc ...
- Tomcat Connector(BIO, NIO, APR)三种运行模式(转)
Tomcat支持三种接收请求的处理方式:BIO.NIO.APR . BIO 阻塞式I/O操作即使用的是传统 I/O操作,Tomcat7以下版本默认情况下是以BIO模式运行的,由于每个请求都要创建一个线 ...
- php-fpm 三种运行模式
php-fpm配置 配置文件:php-fpm.conf 开启慢日志功能的: slowlog = /usr/local/var/log/php-fpm.log.slowrequest_slowlog_t ...
- python编程(python开发的三种运行模式)【转】
转自:http://blog.csdn.net/feixiaoxing/article/details/53980886 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 单循环 ...
随机推荐
- 关于CSS书写规范、顺序
关于CSS的书写规范和顺序,是大部分前端er都必须要攻克的一门关卡,如果没有按照良好的CSS书写规范来写CSS代码,会影响代码的阅读体验.这里总结了一个CSS书写规范.CSS书写顺序供大家参考,这些是 ...
- jquery复习日记(1)
jquery封装了JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作.事件处理.动画设计和Ajax交互. 核心关键字: 链式.多功能.高效灵活 1 ...
- C语言I博客作业03
这个作业属于那个课程 C语言程序设计II 这个作业要求在哪里 https://edu.cnblogs.com/campus/zswxy/CST2019-2/homework/8717 我在这个课程的目 ...
- SpringBoot源码分析之---SpringBoot项目启动类SpringApplication浅析
源码版本说明 本文源码采用版本为SpringBoot 2.1.0BUILD,对应的SpringFramework 5.1.0.RC1 注意:本文只是从整体上梳理流程,不做具体深入分析 SpringBo ...
- SDN网络IPv6组播机制支持实时视频业务海量用户扩展
以 OpenFlow 技术为核心的软件定义网络(SDN)框架具有集中控制的功能能够自己感知网络拓扑的变化,在细粒度的路径选择.接入控制.负载均衡方面有着天然的优势,为 IPv6 组播功能的实现提供了好 ...
- python编程基础之十八
字符串的查找和替换常用函数: str.count(sub,start = 0,end = len(str)) 计算sub 在str中出现的次数,[start,end)寻找区间 str.find(str ...
- css父元素透明度(opacity)对子元素的影响
首先子元素会继承父元素的透明度: 设置父元素opacity:0.5,子元素不设置opacity,子元素会受到父元素opacity的影响,也会有0.5的透明度. 其次子元素的透明度是基于父元素的透明度计 ...
- How to Get What You Want 如何得到你想要的
[1]If you want something, give it away. [2]When a farmer wants more seeds, he takes his seeds and gi ...
- VMware workstation Windows 10虚拟机安装步骤
1. 在首页点击创建新的虚拟机 2. 选择典型,下一步 3.选择稍后安装操做系统,下一步. 4. 选择第一个Microsoft Windows,版本选择如图. 5. 选择安装位置,我放在D盘. 7. ...
- .net core gRPC与IdentityServer4集成认证授权
前言 随着.net core3.0的正式发布,gRPC服务被集成到了VS2019.本文主要演示如何对gRPC的服务进行认证授权. 分析 目前.net core使用最广的认证授权组件是基于OAuth2. ...