【元学习】Meta Learning 介绍
目录
元学习(Meta-learning)
智能的一个关键方面是多功能性——做许多不同事情的能力。当前的AI系统可以做到精通于某一项技能,但是,如果我们要求AI系统执行各种看似简单的问题(用同一个模型去解决不同问题),它将会变得十分困难。相反,人类可以明智地利用以往经验并采取行动以适应各种新的情况。因此我们希望 agent 能够像人类一样利用以往经验来解决新的问题,而不是将解决新问题的方法从头学起。Learning to learn 或者 meta-larning 是朝这个方向发展的关键一步,它们可以在其生命周期内不断学习各种任务。
元学习被用在了哪些地方?
元学习通常被用在:优化超参数和神经网络、探索好的网络结构、小样本图像识别和快速强化学习等。

Few-Shot Learning(小样本学习)
2015年, Brendan Lake et al. 发表一篇论文,这对现代机器学习方法提出了挑战,他认为机器可以从一个或者几个实例中学习到新概念。后继的两篇论文 memory-augmented neural networks 和 sequential generative models 表明,对深度模型来说,其可以从少量实例中进行学习,尽管还没有达到人类水平。
最近的元学习方法如何工作
元学习系统要接受大量任务(tasks)的训练,并预测其学习新任务的能力。这种任务可能是对新图像分类(给定每个类别就只有一个示例),其中有5种可能类别;或者是这样一种任务,仅通过学习一个迷宫就可以有效地在新的迷宫中导航。这与许多标准的机器学习技术不同,后者涉及对单个任务地训练,并且保留了一些示例对该任务进行测试。下图是图像分类领域运用元学习的示例:

在元学习过程中,训练模型以学习 meta-training set 中的任务,这其中有两个优化在起作用:learner:学习新任务;meta-learner:训练 learner。元学习的方法通常分为三类:(1)recurrent models,(2)metric learning, (3)learning optimizers。
这里重点介绍第三种方法,即学习一个优化器。在这种方法里,有两个网络,分别是 meta-learner 和 learner。前者学习如何更新后者,使得后者能够有效学习新任务。这种方法已被用于研究更好的神经网络优化。meta-learner 通常是循环网络(recurrent network),这样才能记得之前是怎样更新 learner 模型。此外,meta-learner 可以使用强化学习或者监督学习进行训练。
Model-Agnostic Meta-Learning (MAML)
MAML 的思路就是直接针对初始表示进行优化,其中这种初始表示可以通过少量示例进行有效地调整。像其他 meta-learning 方法一样,MAML 也是通过许多 tasks 进行训练,训练所得表征可以通过很少梯度迭代就能适应新任务。MAML 试图寻找这样一种初始化,不仅有效适用不同任务,而且要快速适应(仅需要几步)和有效适应(只使用很少样例)。观看下图,假设我们正在寻找一组有很强适应性的参数 \(\theta\) 。在元学习过程中(实线部分),MAML 针对一组参数进行优化,以使得对特定任务 \(i\) (灰线部分)采取梯度步骤时,这些参数可以接近最佳参数 \(\theta_i^*\) 。
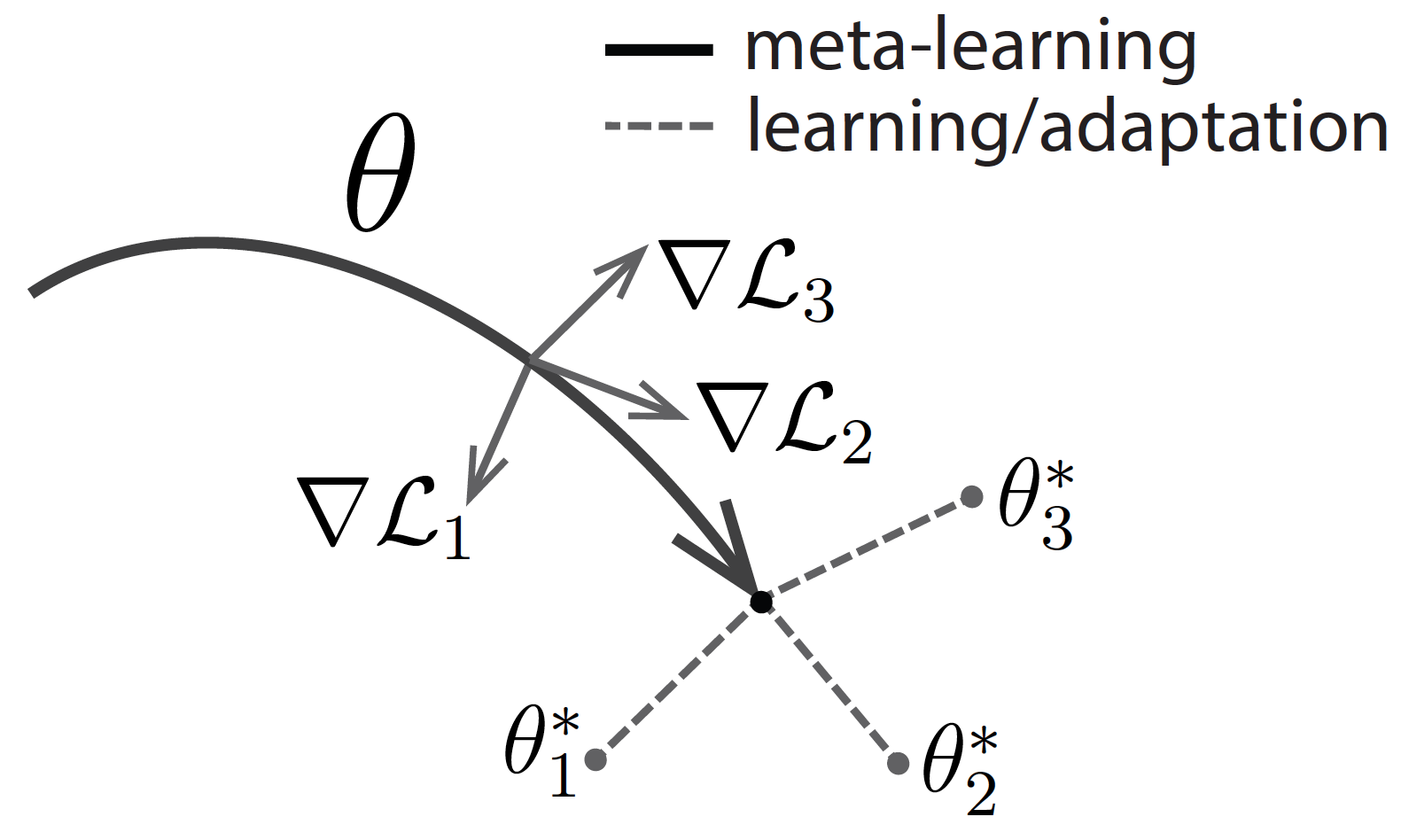
以 MAML 为例介绍元学习一些相关概念
1. N-way K-shot:这是 few-shot learning 中常见的实验设置,N-way 指训练数据中有 N 个类别,K-shot 指每个类别下有 K 个被标记数据。
2. model-agnostic:即指模型无关。MAML 相当于一个框架,提供一个 meta learner 用于训练 learner。meta-learner 是 MAML 的精髓所在,用于 learning to learn;而 learner 则是在目标数据集上被训练,并实际用于预测任务的真正数学模型。绝大多数深度学习模型都可以作为 learner 无缝嵌入 MAML 中,MAML 甚至也可以用于强化学习中,这就是 MAML 中模型无关的含义。
3. task:这在 MAML 中是一个很重要的概念。我们首先需要了解的概念:\(D_{meta-train}, D_{meta-test}\),support set,query set,meta-train classes,meta-test classes等等。假设一个这样的场景:我们需要利用 MAML 训练一个数学模型 \(M_{fine-tune}\),目的是对未知标签图片做分类,类别包括\(P_1 \sim P_5\)(每类有 5 个已标注样本用于训练,另外 15 个已标注样本用于测试)。我们的训练数据除了 \(P_1 \sim P_5\) 中已标注的样本外,还包括另外 10 个类别的图片 \(C_1 \sim C_{10}\)(每类有 30 个已标注样本),用于帮助训练元学习模型 \(M_{meta}\)。
此时, \(C_1 \sim C_{10}\) 即为 meta-train classes, \(C_1 \sim C_{10}\) 包含的 300 个样本即为 \(D_{meta-train}\),作为训练 \(M_{meta}\) 的数据集。与此相对, \(P_1 \sim P_{5}\) 即为 meta-test classes, \(P_1 \sim P_{5}\) 包含的 100 个样本即为 \(D_{meta-test}\),作为训练和测试 $M_{fine-tune} $ 的数据集。
我们的实验设置为5-way 5-shot,因此在 \(M_{meta}\) 阶段,我们从 \(C_1 \sim C_{10}\) 中随机选取 5 个类别,每个类别再随机选取 20 个已标注样本,组成一个 Task \(\text{T}\),其中的 5 个已标注样本称为 \(\text{T}\) 的 support set,另外 15 个样本称为 \(\text{T}\) 的 query set。这个 Task \(\text{T}\) 相当于普通深度学习模型训练过程的一个数据,因此我们需要反复在训练数据分布中抽取若干个 \(\text{T}\) 组成 batch ,才能使用随机梯度下降 SGD。
MAML 算法流程
这里内容主要来自知乎:https://zhuanlan.zhihu.com/p/57864886

以上是 MAML 预训练阶段的算法,目的是得到模型 \(M_{meta}\) 。下面是逐行分析:
首先是前两个 Require。第一个 Require 指的是 \(D_{meta-train}\) 中 task 的分布,我们可以反复随机抽取 task,形成一个由若干个 \(\text{T}\) 组成的 task 池,作为 MAML 的训练集。第二个 Require 就是学习率,MAML 是基于二重梯度的,每次迭代包含两次参数更新的过程,所以有两个学习率可以调整。
步骤1:随机初始化模型参数;
步骤2:是一个循环,可以理解为一轮迭代过程或一个 Epoch,当然,预训练过程也可以有多个 Epoch,相当于设置 Epoch;
步骤3:随机对若干个(e.g., 4 个)task 进行采样,形成一个 batch;
步骤4 \(\sim\) 步骤7:第一次梯度更新过程。注意这里我们可以理解为copy了一个原模型,计算出新的参数,用在第二轮梯度的计算过程中。 我们说过,MAML是gradient by gradient的,有两次梯度更新的过程。步骤4~7中,利用batch中的每一个task,我们分别对模型的参数进行更新(4个task即更新4次)。 注意这个过程在算法中是可以反复执行多次的,但是伪代码没有体现这一层循环 。
步骤5: 利用 batch 中的某一个 task 中的 support set( 在 N-way K-shot 的设置下,这里的support set 应该有 NK 个 ),计算每个参数的梯度。 注意: 这里的loss计算方法,在回归问题中,就是MSE;在分类问题中,就是cross-entropy。
步骤6:第一次梯度的更新。
步骤4 \(\sim\) 步骤7: 结束后,MAML完成了第一次梯度更新。接下来我们要做的,是根据第一次梯度更新得到的参数,通过gradient by gradient,计算第二次梯度更新。第二次梯度更新时计算出的梯度,直接通过SGD作用于原模型上,也就是我们的模型真正用于更新其参数的梯度。
步骤8:这里对应第二次梯度更新的过程。这里的loss计算方法,大致与步骤5相同,但是不同点有两处:第一处是我们不再分别利用每个task的loss更新梯度,而是像常见的模型训练过程一样,计算一个batch的loss总和,对梯度进行随机梯度下降SGD;第一处是这里参与计算的样本,是task中的 query set,在我们的例子中,即5-way*15=75个样本,目的是增强模型在task上的泛化能力,避免过拟合 support set。步骤8结束后,模型结束在该batch中的训练,开始回到步骤3,继续采样下一个batch。
以上便是 MAML 预训练得到 \(M_{meta}\) 的全部过程。
接下来,在面对新的 task 时,我们将在 \(M_{meta}\) 的基础上,精调(fine-tune)得到 \(M_{fine-tune}\) 。
精调过程于预训练过程大致相同,不同之处有以下几点:
- 步骤 1 中,fine-tune 不用再随机初始化参数,而是利用训练好的 \(M_{meta}\) 初始化参数;
- 步骤 3 中,fine-tune只需要抽取一个task进行学习,自然也不用形成batch。fine-tune利用这个task的support set训练模型,利用query set测试模型。 实际操作中,我们会在 \(D_{meta-test}\) 上随机抽取多个 task(e.g., 500 个),分别微调模型 \(M_{meta}\),并对最后测试结果进行平均,避免极端情况;
- fine-tune 没有步骤 8, 因为task的query set是用来测试模型的,标签对模型是未知的。因此fine-tune过程没有第二次梯度更新,而是直接利用第一次梯度计算的结果更新参数。
References:
[1] 深度学习小站——知乎
[2] From zero to research — An introduction to Meta-learning
[3] BAIR——MAML作者的 bolg
【元学习】Meta Learning 介绍的更多相关文章
- 机器学习——深度学习(Deep Learning)
Deep Learning是机器学习中一个非常接近AI的领域,其动机在于建立.模拟人脑进行分析学习的神经网络,近期研究了机器学习中一些深度学习的相关知识,本文给出一些非常实用的资料和心得. Key W ...
- (转)机器学习——深度学习(Deep Learning)
from:http://blog.csdn.net/abcjennifer/article/details/7826917 Deep Learning是机器学习中一个非常接近AI的领域,其动机在于建立 ...
- 小样本学习Few-shot learning
One-shot learning Zero-shot learning Multi-shot learning Sparse Fine-grained Fine-tune 背景:CVPR 2018收 ...
- python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍
目录 python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍 一丶元祖 1.元祖简介 2.元祖变量的定义 3.元祖变量的常用操作. 4.元祖的遍历 5.元祖的应用场景 p ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 【模型压缩】MetaPruning:基于元学习和AutoML的模型压缩新方法
论文名称:MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning 论文地址:https://arxiv.org/ ...
- 【MetaPruning】2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning-论文阅读
MetaPruning 2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning Zechun ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
随机推荐
- Spring Boot2 系列教程(三)理解 Spring Boot 项目中的 parent
前面和大伙聊了 Spring Boot 项目的三种创建方式,这三种创建方式,无论是哪一种,创建成功后,pom.xml 坐标文件中都有如下一段引用: <parent> <groupId ...
- Nacos配置服务原理
Nacos Client配置机制 spring加载远程配置 在了解NACOS客户端配置之前,我们先看看spring怎么样加载远程配置的.spring 提供了加载远程配置的扩展接口 PropertySo ...
- Mysql优化总结(一)
一,前言 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库. MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司.My ...
- py-faster-rcnn的常见错误
在py-faster-rcnn配置运行faster-rcnn-end2end-VGG-CNN_M_1024的过程中, 执行命令:./experiments/scripts/faster_rcnn_en ...
- jmeter linux分布式压测Server failed to start: java.rmi.server.ExportException: Listen failed on port: 0; nested exception is: java.io.FileNotFoundException: rmi_keystore.jks
在路径\apache-jmeter-5.0\bin下启动jmeter-server.bat时抛出了如下异常: 1.jmeter 1099端口 被占用,修改端口号 使用netstat -lntp|gre ...
- Jmeter接口压力测试,Java.net.BindException: Address already in use: connect
Java.net.BindException: Address already in use: connect 问题原因: 操作系统会为TCP/IP服务预留临时端口,Jmeter在跑并发测试的时候每开 ...
- 字符串之————图文讲解字符串排序(LSD、MSD)
本篇文章围绕字符串排序的核心思想,通过图示例子和代码分析的方式讲解了两个经典的字符串排序方法,内容很详细,完整代码放在文章的最后. 一.键索引计数法 在一般排序中,都要用里面的元素不断比较,而字符串这 ...
- Channel使用技巧
前言 Go协程一般使用channel(通道)通信从而协调/同步他们的工作.合理利用Go协程和channel能帮助我们大大提高程序的性能.本文将介绍一些使用channel的场景及技巧 场景一,使用cha ...
- 采用redis生成唯一且随机的订单号
项目描述 最近做的一个项目有这么一个需求:需要生成一个唯一的11位的就餐码(类似于订单号的概念),就餐码的规则是:一共是11位的数字,前面6位是日期比如2019年07月20就是190720,后面五位是 ...
- WordPress 文章目录插件 Easy Table of Contents 配置教程
今天介绍一款目录插件,本站已经使用一段时间,感觉不错,实现效果可以看文章页右侧边栏有目录,点击目录内容会快速定位.推荐给大家. 一.安装Easy Table of Contents 插件主页搜索Eas ...