损失函数———有关L1和L2正则项的理解
一、损失函:
模型的结构风险函数包括了 经验风险项 和 正则项,如下所示:
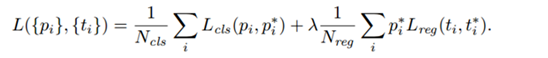
二、损失函数中的正则项
1.正则化的概念:
机器学习中都会看到损失函数之后会添加一个额外项,常用的额外项一般有2种,L1正则化和L2正则化。L1和L2可以看做是损失函数的惩罚项,所谓惩罚项是指对损失函数中某些参数做一些限制,以降低模型的复杂度。
L1正则化通过稀疏参数(特征稀疏化,降低权重参数的数量)来降低模型的复杂度;
L2正则化通过降低权重的数值大小来降低模型复杂度。
对于线性回归模型,使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
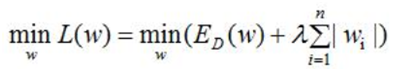
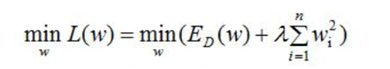
一般正则化项前面添加一个系数λ,数值大小需要用户自己指定,称权重衰减系数weight_decay,表示衰减的快慢。
2.L1正则化和L2正则化的作用:
·L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
·L2正则化可以减小参数大小,防止模型过拟合;一定程度上L1也可以防止过拟合
稀疏矩阵的概念:
·在矩阵中,若数值为0的元素数目远远超过非0元素的数目时,则该矩阵为稀疏矩阵。与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。
3、正则项的直观理解
引用文档链接:
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
分别从以下角度对L1和L2正则化进行解释:
1、 优化角度分析
2、 梯度角度分析
3、 图形角度分析
4、 PRML的图形角度分析
优化角度分析:
L2正则化的优化角度分析:

即在限定区域 找到使得ED(W)最小的权重W。
找到使得ED(W)最小的权重W。
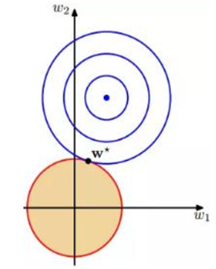
假设n=2,即只有2个参数w1和w2;作图如下:

图中红色的圆即是限定区域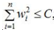 ,简化为2个参数就是w1和w2,限定区域w12+w22≤C即是以原点为圆心的圆。蓝色实线和虚线是等高线,外高内低,越靠里面的等高圆ED(W)越小。梯度下降的方向(梯度的反方向-▽ED(W)),即图上灰色箭头的方向,由外圆指向内圆的方向
,简化为2个参数就是w1和w2,限定区域w12+w22≤C即是以原点为圆心的圆。蓝色实线和虚线是等高线,外高内低,越靠里面的等高圆ED(W)越小。梯度下降的方向(梯度的反方向-▽ED(W)),即图上灰色箭头的方向,由外圆指向内圆的方向 表示;正则项边界上运动点P1和P2的切线用绿色箭头表示,法向量用实黑色箭头表示。切点P1上的切线在梯度下降方向有分量,仍有往负梯度方向运动的趋势;而切点P2上的法向量正好是梯度下降的方向,切线方向在梯度下降方向无分量,所以往梯度下降方向没有运动趋势,已是梯度最小的点。
表示;正则项边界上运动点P1和P2的切线用绿色箭头表示,法向量用实黑色箭头表示。切点P1上的切线在梯度下降方向有分量,仍有往负梯度方向运动的趋势;而切点P2上的法向量正好是梯度下降的方向,切线方向在梯度下降方向无分量,所以往梯度下降方向没有运动趋势,已是梯度最小的点。
结论:L2正则项使E最小时对应的参数W变小(离原点的距离更小)
L1正则化的优化角度分析:

在限定区域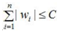 ,找到使ED(w)的最小值。
,找到使ED(w)的最小值。
同上,假设参数数量为2:w1和w2,限定区域为|w1|+|w2|≤C ,即为如下矩形限定区域,限定区域边界上的点的切向量的方向始终指向w2轴,使得w1=0,所以L1正则化容易使得参数为0,即使参数稀疏化。
梯度角度分析:
L1正则化:
L1正则化的损失函数为:
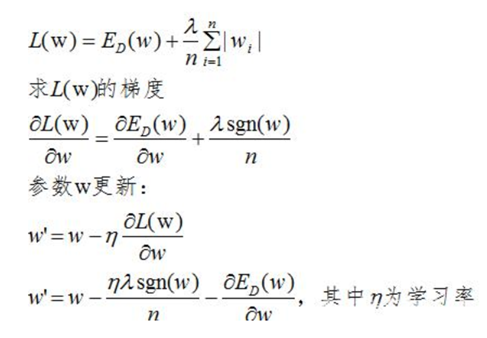
L1正则项的添加使参数w的更新增加了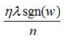 ,sgn(w)为阶跃函数,当w大于0,sgn(w)>0,参数w变小;当w小于0时,更新参数w变大,所以总体趋势使得参数变为0,即特征稀疏化。
,sgn(w)为阶跃函数,当w大于0,sgn(w)>0,参数w变小;当w小于0时,更新参数w变大,所以总体趋势使得参数变为0,即特征稀疏化。
L2正则化:
L2正则化的损失函数为:
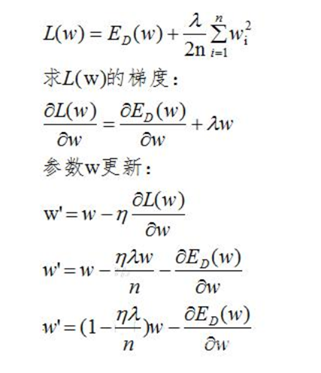
由上式可以看出,正则化的更新参数相比没有加正则项的更新参数多了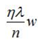 ,当w>0时,正则项使得参数增大变慢(减去一个数值,增大的没那么快),当w<0时,正则项使得参数减小变慢(加上一个数值,减小的没那么快),总体趋势变得很小,但不为0。
,当w>0时,正则项使得参数增大变慢(减去一个数值,增大的没那么快),当w<0时,正则项使得参数减小变慢(加上一个数值,减小的没那么快),总体趋势变得很小,但不为0。
PRML的图形角度分析
L1正则化在零点附近具有很明显的棱角,L2正则化则在零附近是比较光滑的曲线。所以L1正则化更容易使参数为零,L2正则化则减小参数值,如下图。
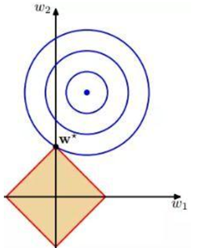
L1正则项
L2正则项
以上是根据阅读百度网友文章做的笔记(其中包括自己的理解),感谢该文档作者,引用链接:
https://baijiahao.baidu.com/s?id=1621054167310242353
损失函数———有关L1和L2正则项的理解的更多相关文章
- 『科学计算』L0、L1与L2范数_理解
『教程』L0.L1与L2范数 一.L0范数.L1范数.参数稀疏 L0范数是指向量中非0的元素的个数.如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,让参数W是稀 ...
- 回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss
回归损失函数:L1,L2,Huber,Log-Cosh,Quantile Loss 2019-06-04 20:09:34 clover_my 阅读数 430更多 分类专栏: 阅读笔记 版权声明: ...
- 机器学习中正则化项L1和L2的直观理解
正则化(Regularization) 概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. L0正则化 稀疏的参数可以防止 ...
- L1和L2:损失函数和正则化
作为损失函数 L1范数损失函数 L1范数损失函数,也被称之为最小绝对值误差.总的来说,它把目标值$Y_i$与估计值$f(x_i)$的绝对差值的总和最小化. $$S=\sum_{i=1}^n|Y_i-f ...
- L0、L1与L2范数
监督机器学习问题无非就是“minimize your error while regularizing your parameters”,也就是在正则化参数的同时最小化误差.最小化误差是为了让我们的模 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
- 《机器学习实战》学习笔记第八章 —— 线性回归、L1、L2范数正则项
相关笔记: 吴恩达机器学习笔记(一) —— 线性回归 吴恩达机器学习笔记(三) —— Regularization正则化 ( 问题遗留: 小可只知道引入正则项能降低参数的取值,但为什么能保证 Σθ2 ...
- L1与L2损失函数和正则化的区别
本文翻译自文章:Differences between L1 and L2 as Loss Function and Regularization,如有翻译不当之处,欢迎拍砖,谢谢~ 在机器学习实 ...
随机推荐
- 【解决】OCI runtime exec failed......executable file not found in $PATH": unknown
[问题]使用docker exec + sh进入容器时报错 [root@localhost home]# docker exec -it container-test bash OCI runtime ...
- BZOJ 2049洞穴探测
辉辉热衷于洞穴勘测.某天,他按照地图来到了一片被标记为JSZX的洞穴群地区.经过初步勘测,辉辉发现这片区域由n个洞穴(分别编号为1到n)以及若干通道组成,并且每条通道连接了恰好两个洞穴.假如两个洞穴可 ...
- CoderForces-375D
You have a rooted tree consisting of n vertices. Each vertex of the tree has some color. We will ass ...
- JSP+Servlet 实现:理财产品信息管理系统
一.接业务,作分析 1.大致业务要求 1.1 使用 JSP+Servlet 实现理财产品信息管理系统,MySQL5.5 作为后台数据库,实现查看理财 和增加理财功能 1.2 查询页面效果图 1.3 添 ...
- JAVA中SPI机制
之前研究dubbo的时候就很好奇,里面各种扩展机制,期间也看过很多关于SPI的机制,今日有缘再度看到有文章总结,故记录一下, 首先了解一下 JAVA中SPI简单的用法 可参考这篇文章,https:// ...
- elasticsearch-6.2.4 + kibana-6.2.4-windows-x86_64安装配置
1.es和kibana的版本都是6.2.4 elasticsearch-6.2.4 + kibana-6.2.4-windows-x86_64 2.先安装es,下载下来解压, config目录下修改 ...
- CSS——overflow的参数以及使用
学习网站:https://developer.mozilla.org/zh-CN/docs/Web/CSS/overflow
- Javascript 垃圾回收方法
Javascript 垃圾回收方法 标记清除(mark and sweep) 这是 JavaScript 最常见的垃圾回收方式,当变量进入执行环境的时候,比如函数中声明一个变量,垃圾回收器将其标记为& ...
- BBS项目知识点汇总
目录 bbs项目知识点汇总 一. JavaScript 1 替换头像 2 form表单拿数据 3 form组件error信息渲染 4 添加html代码 5 聚焦操作 二 . html在线编辑器 三 . ...
- 如何用Pact进行微服务集成测试
原文链接 https://codefresh.io/docker-tutorial/how-to-test-microservice-integration-with-pact/ 挑战:微服务集成测试 ...