Storm 学习之路(九)—— Storm集成Kafka
一、整合说明
Storm官方对Kafka的整合分为两个版本,官方说明文档分别如下:
- Storm Kafka Integration : 主要是针对0.8.x版本的Kafka提供整合支持;
- Storm Kafka Integration (0.10.x+) : 包含Kafka 新版本的 consumer API,主要对Kafka 0.10.x +提供整合支持。
这里我服务端安装的Kafka版本为2.2.0(Released Mar 22, 2019) ,按照官方0.10.x+的整合文档进行整合,不适用于0.8.x版本的Kafka。
二、写入数据到Kafka
2.1 项目结构
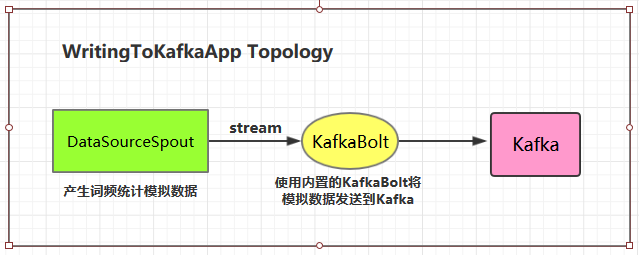
2.2 项目主要依赖
<properties>
<storm.version>1.2.2</storm.version>
<kafka.version>2.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>
2.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}
产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
2.4 WritingToKafkaApp
/**
* 写入数据到Kafka中
*/
public class WritingToKafkaApp {
private static final String BOOTSTRAP_SERVERS = "hadoop001:9092";
private static final String TOPIC_NAME = "storm-topic";
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
// 定义Kafka生产者属性
Properties props = new Properties();
/*
* 指定broker的地址清单,清单里不需要包含所有的broker地址,生产者会从给定的broker里查找其他broker的信息。
* 不过建议至少要提供两个broker的信息作为容错。
*/
props.put("bootstrap.servers", BOOTSTRAP_SERVERS);
/*
* acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。
* acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
* acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
* acks=all : 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
*/
props.put("acks", "1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaBolt bolt = new KafkaBolt<String, String>()
.withProducerProperties(props)
.withTopicSelector(new DefaultTopicSelector(TOPIC_NAME))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper<>());
builder.setSpout("sourceSpout", new DataSourceSpout(), 1);
builder.setBolt("kafkaBolt", bolt, 1).shuffleGrouping("sourceSpout");
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterWritingToKafkaApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWritingToKafkaApp",
new Config(), builder.createTopology());
}
}
}
2.5 测试准备工作
进行测试前需要启动Kakfa:
1. 启动Kakfa
Kafka的运行依赖于zookeeper,需要预先启动,可以启动Kafka内置的zookeeper,也可以启动自己安装的:
# zookeeper启动命令
bin/zkServer.sh start
# 内置zookeeper启动命令
bin/zookeeper-server-start.sh config/zookeeper.properties
启动单节点kafka用于测试:
# bin/kafka-server-start.sh config/server.properties
2. 创建topic
# 创建用于测试主题
bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 --replication-factor 1 --partitions 1 --topic storm-topic
# 查看所有主题
bin/kafka-topics.sh --list --bootstrap-server hadoop001:9092
3. 启动消费者
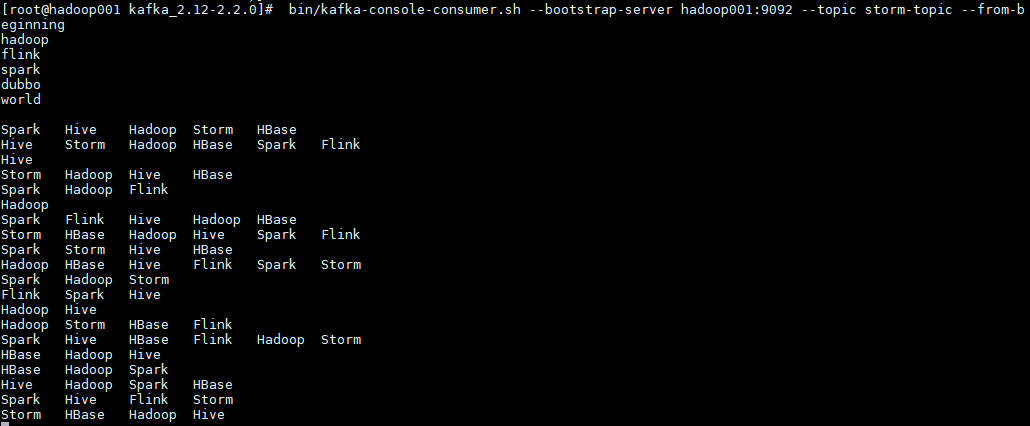
启动一个消费者用于观察写入情况,启动命令如下:
# bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic storm-topic --from-beginning
2.6 测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用maven-shade-plugin进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true
启动后,消费者监听情况如下:
三、从Kafka中读取数据
3.1 项目结构
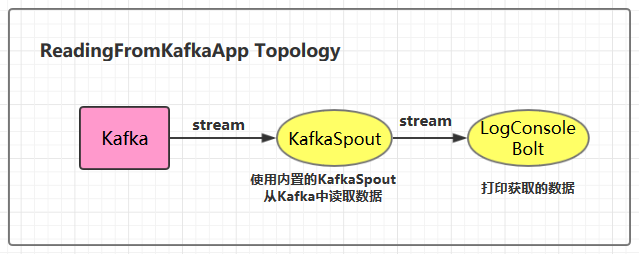
3.2 ReadingFromKafkaApp
/**
* 从Kafka中读取数据
*/
public class ReadingFromKafkaApp {
private static final String BOOTSTRAP_SERVERS = "hadoop001:9092";
private static final String TOPIC_NAME = "storm-topic";
public static void main(String[] args) {
final TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka_spout", new KafkaSpout<>(getKafkaSpoutConfig(BOOTSTRAP_SERVERS, TOPIC_NAME)), 1);
builder.setBolt("bolt", new LogConsoleBolt()).shuffleGrouping("kafka_spout");
// 如果外部传参cluster则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterReadingFromKafkaApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalReadingFromKafkaApp",
new Config(), builder.createTopology());
}
}
private static KafkaSpoutConfig<String, String> getKafkaSpoutConfig(String bootstrapServers, String topic) {
return KafkaSpoutConfig.builder(bootstrapServers, topic)
// 除了分组ID,以下配置都是可选的。分组ID必须指定,否则会抛出InvalidGroupIdException异常
.setProp(ConsumerConfig.GROUP_ID_CONFIG, "kafkaSpoutTestGroup")
// 定义重试策略
.setRetry(getRetryService())
// 定时提交偏移量的时间间隔,默认是15s
.setOffsetCommitPeriodMs(10_000)
.build();
}
// 定义重试策略
private static KafkaSpoutRetryService getRetryService() {
return new KafkaSpoutRetryExponentialBackoff(TimeInterval.microSeconds(500),
TimeInterval.milliSeconds(2), Integer.MAX_VALUE, TimeInterval.seconds(10));
}
}
3.3 LogConsoleBolt
/**
* 打印从Kafka中获取的数据
*/
public class LogConsoleBolt extends BaseRichBolt {
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
try {
String value = input.getStringByField("value");
System.out.println("received from kafka : "+ value);
// 必须ack,否则会重复消费kafka中的消息
collector.ack(input);
}catch (Exception e){
e.printStackTrace();
collector.fail(input);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
这里从value字段中获取kafka输出的值数据。
在开发中,我们可以通过继承RecordTranslator接口定义了Kafka中Record与输出流之间的映射关系,可以在构建KafkaSpoutConfig的时候通过构造器或者setRecordTranslator()方法传入,并最后传递给具体的KafkaSpout。
默认情况下使用内置的DefaultRecordTranslator,其源码如下,FIELDS中 定义了tuple中所有可用的字段:主题,分区,偏移量,消息键,值。
public class DefaultRecordTranslator<K, V> implements RecordTranslator<K, V> {
private static final long serialVersionUID = -5782462870112305750L;
public static final Fields FIELDS = new Fields("topic", "partition", "offset", "key", "value");
@Override
public List<Object> apply(ConsumerRecord<K, V> record) {
return new Values(record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
@Override
public Fields getFieldsFor(String stream) {
return FIELDS;
}
@Override
public List<String> streams() {
return DEFAULT_STREAM;
}
}
3.4 启动测试
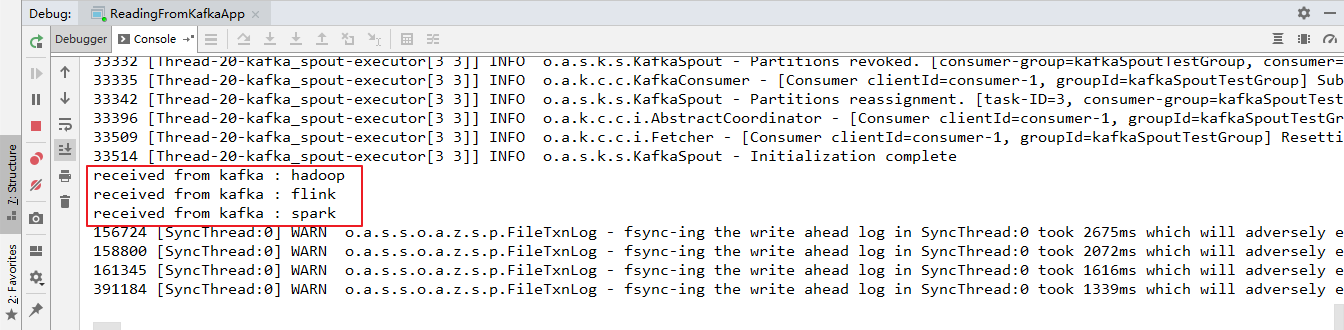
这里启动一个生产者用于发送测试数据,启动命令如下:
# bin/kafka-console-producer.sh --broker-list hadoop001:9092 --topic storm-topic

本地运行的项目接收到从Kafka发送过来的数据:
用例源码下载地址:storm-kafka-integration
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Storm 学习之路(九)—— Storm集成Kafka的更多相关文章
- springboot 学习之路 3( 集成mybatis )
目录:[持续更新.....] spring 部分常用注解 spring boot 学习之路1(简单入门) spring boot 学习之路2(注解介绍) spring boot 学习之路3( 集成my ...
- springboot 学习之路 6(集成durid连接池)
目录:[持续更新.....] spring 部分常用注解 spring boot 学习之路1(简单入门) spring boot 学习之路2(注解介绍) spring boot 学习之路3( 集成my ...
- Storm 学习之路(八)—— Storm集成HDFS和HBase
一.Storm集成HDFS 1.1 项目结构 本用例源码下载地址:storm-hdfs-integration 1.2 项目主要依赖 项目主要依赖如下,有两个地方需要注意: 这里由于我服务器上安装的是 ...
- Storm 学习之路(七)—— Storm集成 Redis 详解
一.简介 Storm-Redis提供了Storm与Redis的集成支持,你只需要引入对应的依赖即可使用: <dependency> <groupId>org.apache.st ...
- Storm 学习之路(五)—— Storm编程模型详解
一.简介 下图为Strom的运行流程图,在开发Storm流处理程序时,我们需要采用内置或自定义实现spout(数据源)和bolt(处理单元),并通过TopologyBuilder将它们之间进行关联,形 ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- Storm 学习之路(六)—— Storm项目三种打包方式对比分析
一.简介 在将Storm Topology提交到服务器集群运行时,需要先将项目进行打包.本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明.主要打包方式有以下三种: 第一种:不加任何插 ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 学习之路(三)—— Storm单机版本环境搭建
1. 安装环境要求 you need to install Storm’s dependencies on Nimbus and the worker machines. These are: Jav ...
随机推荐
- ASP.NET Core Identity 框架 - ASP.NET Core 基础教程 - 简单教程,简单编程
原文:ASP.NET Core Identity 框架 - ASP.NET Core 基础教程 - 简单教程,简单编程 ASP.NET Core Identity 框架 前面我们使用了 N 多个章节, ...
- poj 2763 Housewife Wind(树链拆分)
id=2763" target="_blank" style="">题目链接:poj 2763 Housewife Wind 题目大意:给定一棵 ...
- matlab进行离散点的曲线拟合
原文:matlab进行离散点的曲线拟合 ployfit是matlab中基于最小二乘法的多项式拟合函数.最基础的用法如下: C=polyfit(X,Y,N) 其中: X : 需要拟合的点的横坐标 Y:需 ...
- Xamarin 设置可接受的版本
一共分三个版本,编译版本.最小版本.目标版本(最适应) 一般编译使用最新的版本,目标版本选择最主流的 参考资料 https://docs.microsoft.com/en-us/xamarin/and ...
- 测试WPF绑定bug
1.低级错误:有没有绑错2.去属性那里打断点,get.set有没有进3.xaml加上twoway,UpdateSourceTrigger=PropertyChanged
- WPF x:Array的使用
<Window x:Class="XamlTest.Window1" xmlns="http://schemas.microsoft.com/winf ...
- EF 两种删除方式的比较
UserInfo user = from u in context.UserInfo where u.Id=343 select u; context.UserInfo.Remove(user); 用 ...
- Installshield 在安装或者卸载过程中,判断某一程序是否正在运行
1.在操作时,首先引入类库ShutDownRunningApp.rul,其中ShutDownRunningApp.rul代码如下 /////////////////////////////////// ...
- swagger-editor
前言 上一篇文章我们有提到Swagger做接口的定义是采用yaml语言的,当然,yaml是个啥,大家自行百度.阿福在此不做赘述了.但是,今天我们要来讲的是yaml支持比较好的Swagger-Edito ...
- LOCK_TIMEOUT
SET LOCK_TIMEOUT 1000 begin tran TranNameA select * from tablenameA WITH (updlock) where... waitfor ...