大纲
简介
支持向量机(support vector machines)是一个二分类的分类模型(或者叫做分类器)。如图:
它分类的思想是,给定给一个包含正例和反例的样本集合,svm的目的是寻找一个超平面来对样本根据正例和反例进行分割。
各种资料对它评价甚高,说“ 它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中”
SVM之线性分类器
如果一个线性函数能够将样本完全正确的分开,就称这些数据是线性可分的,否则称为非线性可分的。
什么叫线性函数呢?在一维空间里就是一个点,在二维空间里就是一条直线,三维空间里就是一个平面,以此类推。
如果不关注空间的维数,这种线性函数就是前言中所说的那个统一的名称——超平面(Hyper Plane)!
在样本空间中,划分超平面可通过如下线性方程来描述:
假设它已经完成了对样本的分隔,且两种样本的标签分别是{+1,-1},那么对于一个分类器来说,g(x)>0和个g(x)<0就可以分别代表两个不同的类别,+1和-1。
但光是分开是不够的,SVM的核心思想是尽最大努力使分开的两个类别有最大间隔,这样才使得分隔具有更高的可信度。 而且对于未知的新样本才有很好的分类预测能力(在机器学习中叫泛化能力)
那么怎么描述这个间隔,并且让它最大呢?SVM的办法是:让离分隔面最近的数据点具有最大的距离。
为了描述离分隔超平面最近的数据点,需要找到两个和这个超平面平行和距离相等的超平面:
H1: y = wTx + b=+1 和 H2: y = wTx + b=-1
如图所示:
在这两个超平面上的样本点也就是理论上离分隔超平面最近的点,是它们的存在决定了H1和H2的位置,支撑起了分界线,它们就是所谓的支持向量,这就是支持向量机的由来
有了这两个超平面就可以顺理成章的定义上面提到的间隔(margin)了
二维情况下 ax+by=c1和ax+by=c2两条平行线的距离公式为:
可以推出H1和H2两个超平面的间隔为2/||w||,即现在的目的是要最大化这个间隔。
所以support vector machine又叫Maximum margin hyper plane classifier
等价于最小化||w||
为了之后的求导和计算方便,进一步等价于最小化
假设超平面能将样本正确分类,则可令:
两个式子综合一下有:
这就是目标函数的约束条件。现在这个问题就变成了一个最优化问题:
而且这是一个凸二次规划问题,一般的解决方法有两种1是用现成的优化工具包直接求解,2是使用Lagrange Duality找到一种更有效的方法求解。
其中方法2具有两个优点:
a、更好解
b、可以自然地引入核函数,推广到非线性分类
所以这里选用了第二种方法。
对偶优化问题
对于上述的最优化问题先需要构造拉格朗日函数:
分别对w和b求导得到:
然后再代入拉格朗日函数后得到原问题的对偶问题:
现在已经完成了对这个问题的建模过程。
当要对一个数据点分类时,只需要把待分类的数据点带入g(x)中,把结果和正负号对比。又由上面计算得到的w,带入g(x)得到:
这个式子表示:对x的预测只需要求它与训练点的内积,这是用kernal进行线性推广的基本前提。并且并不是每个训练点都要用到,只需要用到支持向量,非支持向量的系数a为0。
到这里剩下的是怎么解目前这个最优化问题。
但是目前这分类器还是比较弱的分类器,只适合线性的情况,而且没什么容错性。
所以现在先不急着求解,先讨论容错性和非线性情况的推广(泛化)。
核函数
前述方法对线性不可分的样本集无能为力。
但是一个低维的样本集映射到高维则可以变成线性可分(如图所示),那样才能使用SVM工作。

》》》》

设映射函数为Φ(•),则映射后的空间分类函数变成
但是,如果拿到低维数据直接映射到高维的话,维度的数目会呈现爆炸性增长。
所以这里需要引入核函数(kernal function)。
核函数的思想是寻找一个函数,这个函数使得在低维空间中进行计算的结果和映射到高维空间中计算内积<Φ(x1), Φ(x2)>的结果相同。
这样就避开直接在高维空间中进行计算,而最后的结果却是等价的。
现在,分类函数就变成了这样:
其中

就是核函数
由于对任意数据集找到它合适的映射是困难的且没有必要,所以通常会从常用核函数中选择。
常用核函数例如:
- 多项式核函数
- 高斯核核函数
- 线性核函数
- 字符串核函数
上述方法叫做核方法。事实上,任何将计算表示为数据点内积的方法都可以用核方法进行非线性扩展
容错性: Outliers
由于噪音的存在,有可能有偏离正常位置很远的数据点存在,甚至类别1出现杂了类别2的区域中这样的异常值叫outliers.
为处理这种情况,SVM允许数据点在一定程度上偏离超平面,约束就变成了
其中

,称为
松弛变量(slack variable)这就引入了容错性
如果任意大的话,那任意的超平面都是符合条件的了
所以需要在原目标函数中加入损失函数,可以用
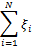
或者

用前者的话,叫一阶软间隔分类器;用后者的话就叫二阶软间隔分类器。
还需要一个惩罚因子C(cost),它代表了对离群点带来的损失的重视程度,它的值越大,对目标函数的损失越大,意味着你非常不愿意放弃这些点。
它是由使用者指定的一个值(libsvm中的参数C),是参数调优的重点所在。
原来的优化问题就变成了下面这样:
同样用Lagrange方法得到对偶问题:
这才是一个可以处理线性和非线性情况并能容忍噪音和outlier的SVM!
SVM用于多类分类
svm本身是一种典型的二分类器,那如何处理现实中的多分类问题呢?
常用的有三种方法:
一、一对多
也就是“一对其余”(One-against-All) 的方式, 就是每次仍然解一个两类分类的问题。
这样对于n个类别会得到n个分类器。
但是这种方式可能会出现分类重叠现象或者不可分类现象
而且由于“其余”的数据集过大,这样其实就人为造成了“数据偏斜”的问题
二、一对一
每次选择一个类作为正样本,负样本只用选其余的一个类,这样就避免了数据偏斜的问题。
很明显可以看出这种方法训练出的分类个数是k*(k-1)/2,虽然分类器的个数比上面多了,但是训练阶段 所用的总时间却比“一类对其余”方法少很多。
这种方法可能使多个分类器指向同一个类别,所以可以采用“投票”的方式确定哪个类别:哪个分类器获得的票数多就是哪个分类器。
这种方式也会有分类重叠的现象,但是不会有不可分类的情况,因为不可能所有类别的票数都是0。
但是也很容易发现这种方法使分类器的数目呈平方级上升。
三、DAG SVM
假设有1、2、3、4、5五个类,那么可以按照如下方式训练分类器( 这是一个有向无环图,因此这种方法也叫做DAG SVM)
这种方式减少了分类器的数量,分类速度飞快,而且也没有分类重叠和不可分类现象。
但是假如一开始的分类器回答错误,那么后面的分类器没有办法纠正,错误会一直向下累积。
为了减少这种错误累积,根节点的选取至关重要。
小结
本文从整个流程上理清了SVM是个什么东西
首先,支持向量机是一个十分流行的针对二分类线性分类器,分类的方式是找到一个最优的超平面把两个类别分开。定义“最优”的方式是使离分隔面最近的数据点到分隔面的距离最大,从而把这个问题转化成了一个二次优化问题
然后,我们选择了拉格朗日方法来对这个二次优化问题进行简化,即转化成它的对偶问题。虽然我们没有进一步讨论这个优化问题的解法,但这已经形成了SVM的初步模型
随后我们对这个简单的分类器进行泛华,用核方法把这个线性模型扩展到非线性的情况,具体方法是把低维数据集映射到高维特征空间。以及,讨论了怎么增强分类器的容错性能。
最后讨论了怎么把这个二分类器用于多分类问题。
参考文献
【4】《机器学习 》,周志华著
【5】《统计学习方法》,李航著
【6】《机器学习实战》Peter Harrington著
- Svm算法原理及实现
Svm(support Vector Mac)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性核非线性两大类.其主要思想为找到空间中的一个 ...
- SVM 支持向量机算法-原理篇
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机. ...
- 支持向量机原理(四)SMO算法原理
支持向量机原理(一) 线性支持向量机 支持向量机原理(二) 线性支持向量机的软间隔最大化模型 支持向量机原理(三)线性不可分支持向量机与核函数 支持向量机原理(四)SMO算法原理 支持向量机原理(五) ...
- 支持向量机 (SVM)分类器原理分析与基本应用
前言 支持向量机,也即SVM,号称分类算法,甚至机器学习界老大哥.其理论优美,发展相对完善,是非常受到推崇的算法. 本文将讲解的SVM基于一种最流行的实现 - 序列最小优化,也即SMO. 另外还将讲解 ...
- 【转】 SVM算法入门
课程文本分类project SVM算法入门 转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Supp ...
- SVM算法入门
转自:http://blog.csdn.net/yangliuy/article/details/7316496SVM入门(一)至(三)Refresh 按:之前的文章重新汇编一下,修改了一些错误和不当 ...
- SVM算法实现(一)
关键字(keywords):SVM 支持向量机 SMO算法 实现 机器学习 假设对SVM原理不是非常懂的,能够先看一下入门的视频,对帮助理解非常实用的,然后再深入一点能够看看这几篇入门文章,作者写得挺 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
随机推荐
- C#开发可播放摄像头及任意格式视频的播放器
前言 本文主要讲述,在WPF中,借助Vlc.DotNet调用VLC类库,实现视频播功能,下面我们先来做开发前的准备工作. 准备工作 首先,我们创建一个项目WpfVLC,然后,进入Neget搜索Vlc. ...
- Unity学习--捕鱼达人笔记
1.2D模式和3D模式的区别,2D模式默认的摄像机的模式是Orthographic(正交摄像机),3D模式默认的摄像机的模式是Perspective(透视摄像机).3D会额外给你一个平衡光.3D模式修 ...
- Educational Codeforces Round 70 (Rated for Div. 2)
这次真的好难...... 我这个绿名蒟蒻真的要崩溃了555... 我第二题就不会写...... 暴力搜索MLE得飞起. 好像用到最短路?然而我并没有学过,看来这个知识点又要学. 后面的题目赛中都没看, ...
- ASP.NET Core MVC 之控制器(Controller)
操作(action)和操作结果(action result)是 ASP.NET MVC 构建应用程序的一个基础部分. 在 ASP.NET MVC 中,控制器用于定义和聚合一组操作.操作是控制器中处理传 ...
- Go中sync包学习
前面刚讲到goroutine和channel,通过goroutine启动一个协程,通过channel的方式在多个goroutine中传递消息来保证并发安全.今天我们来学习sync包,这个包是Go提供的 ...
- Python 命令行之旅 —— 深入 argparse (一)
作者:HelloGitHub-Prodesire HelloGitHub 的<讲解开源项目>系列,项目地址:https://github.com/HelloGitHub-Team/Arti ...
- 新手学习selenium路线图(老司机亲手绘制)
前言: 最近群里有不少小白,想入手selenium,但是一直没找到学习路线,还没入门就迷路了,于是小编亲手绘制了一幅学习路线图.希望能帮助小白快速入门,帮助已经入门的,尽快提升! 学习selenium ...
- 逻辑回归(Logistic Regression)详解,公式推导及代码实现
逻辑回归(Logistic Regression) 什么是逻辑回归: 逻辑回归(Logistic Regression)是一种基于概率的模式识别算法,虽然名字中带"回归",但实际上 ...
- 【雕爷学编程】Arduino动手做(16)---数字触摸传感器
37款传感器和模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器与模块,依照实践出真知(动手试试)的理念,以学习和交流为目的,这里准备 ...
- docker安装到基本使用
记录docker概念,安装及入门日常使用 Docker安装(Linux / Debian) 查看官方文档,在Debian上安装Docker,其他平台在这里查阅,以下均在root用户下操作,省去sudo ...

















