NLP(九) 文本相似度问题
原文链接:http://www.one2know.cn/nlp9/
- 多个维度判别文本之间相似度
- 情感维度 Sentiment/Emotion
- 感官维度 Sense
- 特定词的出现
- 词频 TF
逆文本频率 IDF
构建N个M维向量,N是文档总数,M是所有文档的去重词汇量 - 余弦相似度:
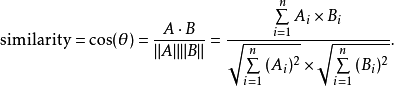
A,B分别是两个词的向量
import nltk
import math
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class TextSimilarityExample:
def __init__(self):
self.statements = [ # 例句
'ruled india',
'Chalukyas ruled Badami',
'So many kingdoms ruled India',
'Lalbagh is a botanical garden in India',
]
def TF(self,sentence):
words = nltk.word_tokenize(sentence.lower()) # 分词,都化成小写
freq = nltk.FreqDist(words) # 计算词频分布,词和词频组成的字典
dictionary = {}
for key in freq.keys():
norm = freq[key] / float(len(words)) # 把词频正则化
dictionary[key] = norm
return dictionary # 返回 词:词频
def IDF(self):
def idf(TotalNumberOfDocuments,NumberOfDocumentsWithThisWord):
return 1.0 + math.log(TotalNumberOfDocuments/NumberOfDocumentsWithThisWord)
# idf = 1 + log(总文件数/含该词的文件数)
numDocuments = len(self.statements) # 总文档数
uniqueWords = {} # 不重复的 字典
idfValues = {} # 词:IDF 字典
for sentence in self.statements: # 得到每个句子的 词:含该词文章数量 字典
for word in nltk.word_tokenize(sentence.lower()):
if word not in uniqueWords:
uniqueWords[word] = 1
else:
uniqueWords[word] += 1
for word in uniqueWords: # 词:含该词文章数量 字典 => 词:IDF 字典
idfValues[word] = idf(numDocuments,uniqueWords[word])
return idfValues
def TF_IDF(self,query): # 返回每句话的向量
words = nltk.word_tokenize(query.lower())
idf = self.IDF() # IDF 由所有文档求出
vectors = {}
for sentence in self.statements: # 遍历所有句子
tf = self.TF(sentence) # TF 由单个句子得出
for word in words:
tfv = tf[word] if word in tf else 0.0
idfv = idf[word] if word in idf else 0.0
mul = tfv * idfv
if word not in vectors:
vectors[word] = []
vectors[word].append(mul) # 字典里添加元素7
return vectors
def displayVectors(self,vectors): # 显示向量内容
print(self.statements)
for word in vectors:
print("{} -> {}".format(word,vectors[word]))
def cosineSimilarity(self):
vec = TfidfVectorizer() # 创建新的向量对象
matrix = vec.fit_transform(self.statements) # 计算所有文本的TF-IDF值矩阵
for j in range(1,5):
i = j - 1
print("\tsimilarity of document {} with others".format(j))
similarity = cosine_similarity(matrix[i:j],matrix) # scikit库的余弦相似度函数
print(similarity)
def demo(self):
inputQuery = self.statements[0] # 第一个句子作为输入查询
vectors = self.TF_IDF(inputQuery) # 建立第一句的向量
self.displayVectors(vectors) # 屏幕上显示所有句子的TF×IDF向量
self.cosineSimilarity() # 计算输入句子与所有句子的余弦相似度
if __name__ == "__main__":
similarity = TextSimilarityExample()
similarity.demo()
输出:
['ruled india', 'Chalukyas ruled Badami', 'So many kingdoms ruled India', 'Lalbagh is a botanical garden in India']
ruled -> [0.6438410362258904, 0.42922735748392693, 0.2575364144903562, 0.0]
india -> [0.6438410362258904, 0.0, 0.2575364144903562, 0.18395458177882582]
similarity of document 1 with others
[[1. 0.29088811 0.46216171 0.19409143]]
similarity of document 2 with others
[[0.29088811 1. 0.13443735 0. ]]
similarity of document 3 with others
[[0.46216171 0.13443735 1. 0.08970163]]
similarity of document 4 with others
[[0.19409143 0. 0.08970163 1. ]]
NLP(九) 文本相似度问题的更多相关文章
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 【NLP】文本相似度
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- NLP文本相似度
NLP文本相似度 相似度 相似度度量:计算个体间相似程度 相似度值越小,距离越大,相似度值越大,距离越小 最常用--余弦相似度: 一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小 余 ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- NLP文本相似度(TF-IDF)
本篇博文是数据挖掘部分的首篇,思路主要是先聊聊相似度的理论部分,下一篇是代码实战. 我们在比较事物时,往往会用到“不同”,“一样”,“相似”等词语,这些词语背后都涉及到一个动作——双方的比 ...
- Finding Similar Items 文本相似度计算的算法——机器学习、词向量空间cosine、NLTK、diff、Levenshtein距离
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf 汇总于此 还有这本书 http://www-nlp.stanford.edu/IR-book/ 里面有 ...
- TF-IDF 文本相似度分析
前阵子做了一些IT opreation analysis的research,从产线上取了一些J2EE server运行状态的数据(CPU,Menory...),打算通过训练JVM的数据来建立分类模型, ...
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
1.信息检索中的重要发明TF-IDF TF-IDF是一种统计方法,TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分 ...
- 【机器学习】使用gensim 的 doc2vec 实现文本相似度检测
环境 Python3, gensim,jieba,numpy ,pandas 原理:文章转成向量,然后在计算两个向量的余弦值. Gensim gensim是一个python的自然语言处理库,能够将文档 ...
随机推荐
- Python(简单图形和文件处理)编程
Python确实是一门很简洁而且功能有强大的语言,我觉得开始学习很容易理解,说到熟练和精通还是不容易的,还需不断学习. 从最基础的语法学习,有些部分各种语言是相同的,让人很好理解.编程也是从最简单语法 ...
- 思路重要or技术重要?
1,思路串通代码的重要性 前段时间,同事在工作上出现一点难题,在技术大佬中看起来算是微不足道的一点小事,由于没有思路,代码也无从下手,他在百度上条框上搜索自己想要的答案,却始终没有比较理想的,大部分的 ...
- JAVA-Spring AOP基础 - 代理设计模式
利用IOC DI实现软件分层,虽然解决了耦合问题,但是很多地方仍然存在非该层应该实现的功能,造成了无法“高内聚”的现象,同时存在大量重复的代码,开发效率低下. @Service public clas ...
- 用泛型写Redis缓存与数据库操作工具类
功能描述: 先从缓存获取数据,如果缓存没有,就从数据库获取数据,并设置到缓存中,返回数据. 如果数据库中没有数据,需要设置一个缓存标记flagKey,防止暴击访问数据库,用缓存保护数据库. 当删除缓存 ...
- 第三章 Linux基本命令操作
第三章 Linux基本命令操作 ¨ 本节所讲内容: ¨ 3.1 Linux终端介绍 Shell提示符 Bash Shell基本语法 ¨ 3.2 基本命令的使用:ls.pwd.cd.hist ...
- C#使用LitJson解析Json数据
//接受MQ服务器返回的值 private void jieshou(string zhiling, string can1, string can2, string can3, string can ...
- IPC机制2
1.使用Messenger Messenger可以翻译为信使,通过它可以在不同进程中传递messenge对象,在messenge中放入我们需要传递的数据,就可以轻松实现数据在进程中传递. 服务段进程: ...
- HTML加载FLASH(*.swf文件)详解
引言 在web项目中经常会遇到在线浏览word文档,通常解决方法将word转换成pdf,然后在线浏览,但是在实际实现过程中,由于阅读器的原因,用户可以直接下载该pdf,这显然不是我们想要的,通过网络搜 ...
- LSTM+CRF维特比解码过程
题目:给定长度为n的序列,标签数为m(标签值表示为1,2,....,m),发射概率矩阵E(n * m),其中E[i][j]表示第i个词预测为标签j的发射概率,转移概率矩阵T(m*m),其中T[i][j ...
- 安装Windows Server 2008
下面介绍一下,Windows Server操作系统安装,以及在企业中的应用,在小型企业中可以使用不同的版本搭建不同类型的服务,小型企业中可以搭建Web服务,FTP服务,以及DNS和DHCP服务等,在大 ...