实验:用Unity抓取指定url网页中的所有图片并下载保存
突发奇想,觉得有时保存网页上的资源非常麻烦,有没有办法输入一个网址就批量抓取对应资源的办法呢。
需要思考的问题:
1.如何得到网页url的html源码呢?
2.如何在浩瀚如海的html中匹配出需要的资源地址呢?
3.如何按照得到的资源地址集合批量下载资源呢?
4.下载的资源一般为文件流,如何生成指定的资源类型并保存呢?
需要掌握的知识:
1.网络爬虫的基础知识,发送Http请求的方法
2.C# 正则表达式运用,主要是识别html中需要的rul网址
3.UnityWebRequest类文件流下载
4.C# File类和Stream类等基础文件操作
下面分项来进行实现:
关于爬虫这里就不进行介绍了,网上其他的地方有很多资料,简而言之就是采集网页信息和数据的程序。
第一步,就是要发送一个Web请求,也可以说是Http请求。
这跟你打开浏览器输入一个url地址然后回车产生的效果基本是类似的,网页上之所以能显示出正确的信息和数据,是因为每一个网页有对应的html源码,像很多浏览器例如谷歌浏览器都是支持查看网页源码的功能,例如下面是我经常去的喵窝的主页的html的<head>部分:

html源码中可以查看到网页当前的很多隐藏信息和数据,其中还有大量的资源链接和样式表等。值得注意的是,html源码只有在网页全部加载完成之后很可以显示和查看,这意味着一个url地址的Web请求响应成功;有成功的情况当然就会有各种各样失败的情况,例如我们经常输入一个rul地址后出现404的提示,这种就是一个Http请求出现错误的情况,404表示服务器未找到请求的网页。其他的错误类型还有很多。为什么要了解这一点呢,因为之后在发送Http请求时要想办法对错误进行处理或跳过执行下一任务。
我们可以有很多方式来发送Http请求,Unity也更新了Web请求的方式:(以后代码我就直接截图了,这个插入代码功能都不能自动排整齐真的难受)
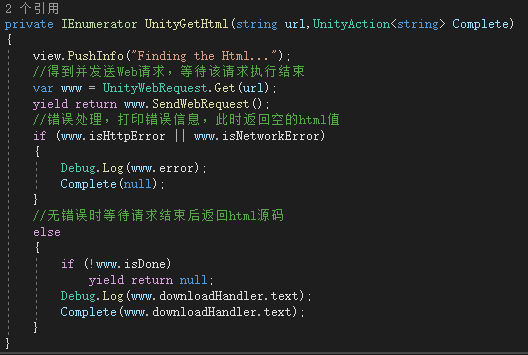
主要用到的类就是UnityWebRequest,和Unity中以前的类WWW有些类似,主要用于文件的下载与上传。
要引入以下命名空间:

UnityAction作为参数主要是用于请求结束后可以自动返回一个html源码。它本质上就是个泛型委托:

泛型的参数可以从没有到多个,是一个非常好用的类(尤其是在协程的回调中,可以很方便的延时参数传递)
当然了,除了Unity内置的发送Web请求的方法,C#也封装了好几个类,你可以随便挑一个使用,例如 HttpWebRequest,WebClient,HttpClient等:
比如这样:
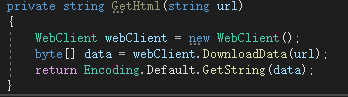
如果成功通过Web请求得到了指定url地址的html源码,那就可以执行下一步了。
第二步,收集html中所需要的数据信息,本例中就是要从这些源码中找出图片的链接地址。
例如可能会有下面这几种情况:
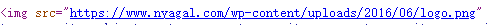
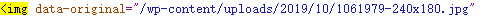

总结一下,首先利用html的常用标签<img>来找可以找到大部分的图片,但还是有部分图片并不在这些标签之内。而且有时候,即使是在<img>标签之内的图片地址,还是有可能出现内链或是外链的区别,外链的话直接作为合法的url地址执行即可,但如果是内链的话就还要补全域名地址,所以我们还需要想办法识别一个url的正确域名。
关于如何识别匹配以上所说的字符串内容,目前最有效的方法就是正则表达式,下面就列举在本例中需要使用到的正则表达式:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://(www.)?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(:[0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html中<img>标签内的url地址:(不区分大小写,其中分组<imgUrl>中为所需的url地址)
private const string imgLableCheck = @"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>";
4.匹配html中<a>标签内href属性的url地址:(不区分大小写,主要用于深度检索,其中分组<url>中为所需的url地址)
private const string hrefLinkCheck = @"(?i)<a\s[^>]*?href=(['""]?)(?!javascript|__doPostBack)(?<url>[^'""\s*#<>]+)[^>]*>";
5.指定图片类型的匹配:(主要用于外链)
private const string jpg = @"\.jpg";
private const string png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不说了。
给定一个html源码,下面从两个方向对图片进行匹配,先匹配外链,这里指定了匹配的文件类型:

下面是内链的匹配,先要匹配出域名地址:
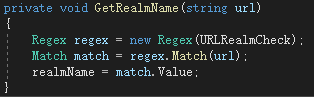
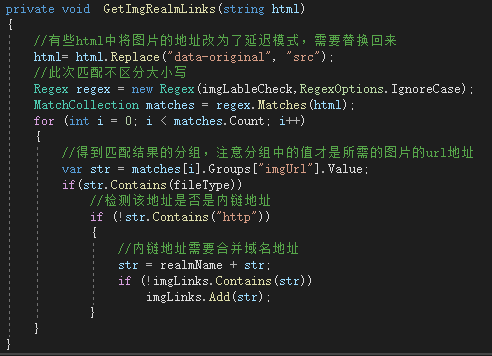
有了域名地址之后就可以轻松匹配内链地址了:
使用正则表达式需要引入以下命名空间:

利用正则表达式匹配出所有的imgLinks后就可以对其中的图片进行依次下载了。
第三步,对有效的图片url进行下载传输:
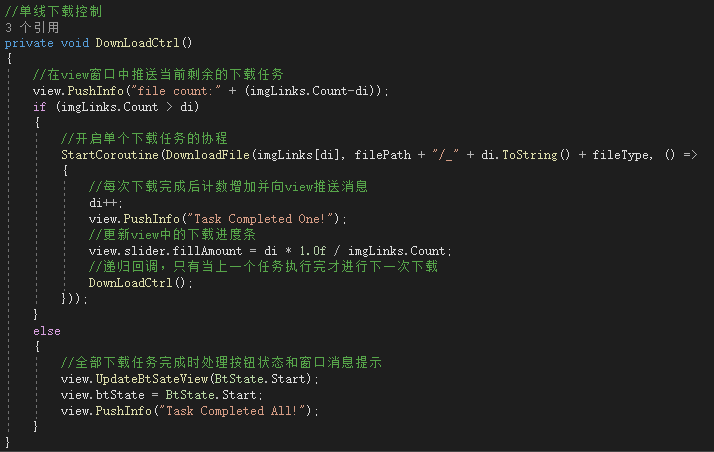
你也可以对这些url进行同步下载传输,但这样可能需要增加额外的最大线程数,而且比较难控制整体的下载进度。
具体的传输协程如下:
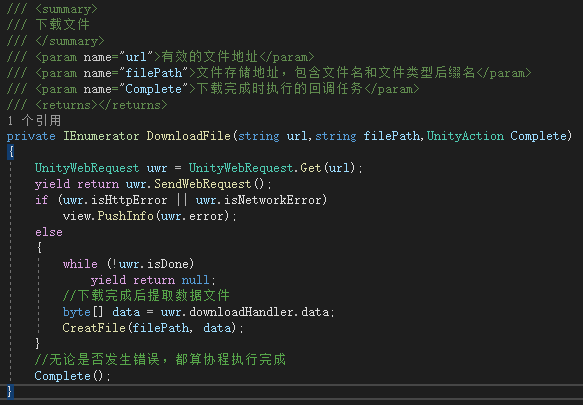
值得注意的是,并非只有成功下载时才调用Complete方法,即使发生了错误,也需要调用,这样避免了一发生错误,自动下载就自行终止的情况。正常情况下是即使发生了错误,也要跳过执行下一文件的下载任务。
最后一步就是将下载的数据文件流转化为指定类型的文件并保存,这里方法有很多,下面提供一种:

扩展:
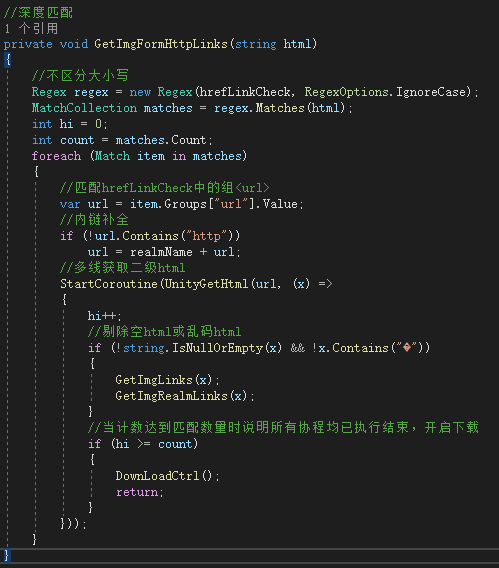
有时单个html中的所有图片链接不能完全满足我们的需求,因为html中的子链接中可能也会有需要的url资源地址,这时我们可以考虑增加更深层次的遍历。那就需要先匹配出html中的link地址,然后再得到该link地址的子html源码,如此进行关于深度匹配的循环。
匹配html中的子链接可以通过查找<a>标签的属性href,上面已经给出过该属性的正则匹配表达式,这里只深度匹配了一层以供参考:
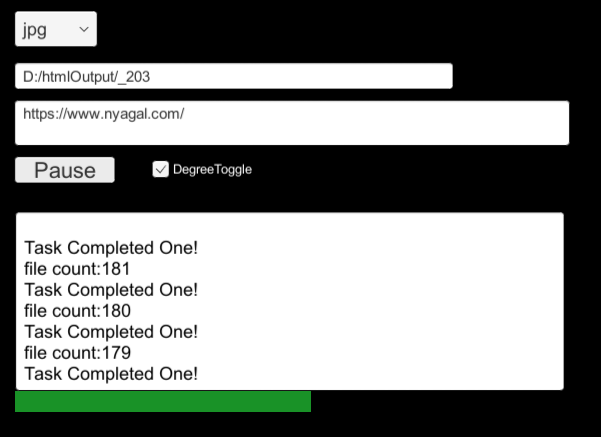
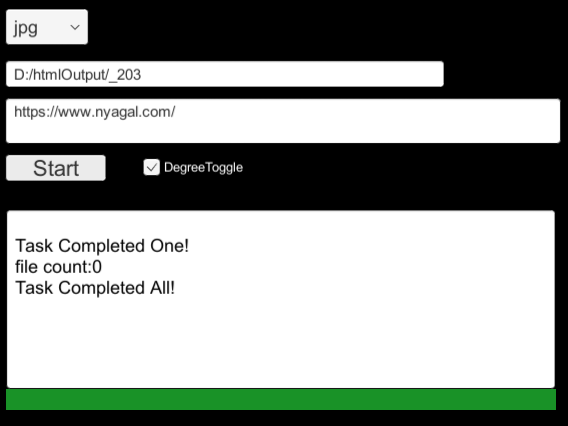
测试:这里用深度匹配抓取喵窝主页为jpg格式的图片链接并下载,存到D盘中。(UI就随便做的不用在意)
实验:用Unity抓取指定url网页中的所有图片并下载保存的更多相关文章
- javascript怎么获取指定url网页中的内容
javascript怎么获取指定url网页中的内容 一.总结 一句话总结:推荐jquery中ajax,简单方便. 1.js能跨域操作么? javascript出于安全机制不允许跨域操作的. 二.用ph ...
- Python3 urllib抓取指定URL的内容
最近在研究Python,熟悉了一些基本语法和模块的使用:现在打算研究一下Python爬虫.学习主要是通过别人的博客和自己下载的一下文档进行的,自己也写一下博客作为记录学习自己过程吧.Python代码写 ...
- Python 爬虫-抓取中小企业股份转让系统公司公告的链接并下载
系统运行系统:MAC 用到的python库:selenium.phantomjs等 由于中小企业股份转让系统网页使用了javasvript,无法用传统的requests.BeautifulSoup库获 ...
- PHP抓取及分析网页的方法详解
本文实例讲述了PHP抓取及分析网页的方法.分享给大家供大家参考,具体如下: 抓取和分析一个文件是非常简单的事.这个教程将通过一个例子带领你一步一步地去实现它.让我们开始吧! 首先,我首必须决定我们将抓 ...
- C#实现通过程序自动抓取远程Web网页信息的代码
http://www.jb51.net/article/9499.htm 通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在 ...
- C#抓取远程Web网页信息的代码
来自:http://www.jb51.net/article/9499.htm 通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析 ...
- php使用curl简单抓取远程url的方法
这篇文章主要介绍了php使用curl简单抓取远程url的方法,涉及php操作curl的技巧,具有一定参考借鉴价值,需要的朋友可以参考下 本文实例讲述了php使用curl抓取远程url的方法.分 ...
- 使用Python中的urlparse、urllib抓取和解析网页(一)(转)
对搜索引擎.文件索引.文档转换.数据检索.站点备份或迁移等应用程序来说,经常用到对网页(即HTML文件)的解析处理.事实上,通过Python 语言提供的各种模块,我们无需借助Web服务器或者Web浏览 ...
- C#抓取和分析网页的类
抓取和分析网页的类. 主要功能有: Ontology 1.提取网页的纯文本,去所有html标签和javascript代码 2.提取网页的链接,包括href和frame及iframe 3.提取网页的ti ...
随机推荐
- Oracle ASM无法识别扩展分区的磁盘设备
在linux 环境下,我们一般通过udev或者asmlib来绑定磁盘分区作为ASM的候选存储单元.在使用udev的情况下,一般只要我们可以看到被绑定的磁盘的设备,并且这些设备的属主和权限没有问题,AS ...
- make:yacc/lex:command not be found
1.使用./build编译boa-0.94.13时出现make:yacc:command not be found 解决方法:apt-get install -y byacc 2.出现make:lex ...
- C#语法基础----变量 符号 数据转换
变量的作用:为了更好的管理内存数据,不同类型的数据存放在不同的内存块中. 变量的特点:不同数据类型占用的存储空间大小不一样. 变量的意义:内存地址是一串十六进制数,非常不好记忆,通过变量可以快速找到数 ...
- Mybatis----resultMap类型详解
Mybatis----resultMap类型详解 这篇文章主要给大家介绍了关于Mybatis中强大的resultMap功能的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用Mybatis具 ...
- 新版Notepad++加十六进制查看的插件HexEditor
Notepad++新版虽然去掉了在线插件商店功能,但是依然可以使用自定义插件 Notepad++下载地址 腾讯(请务必点普通下载):https://pc.qq.com/detail/0/detail_ ...
- SpringBoot打包为war包,并在tomcat中运行
先看一下我创建的最简单的项目吧. controller类 @RestController public class TestController { @RequestMapping("ind ...
- 以太坊智能合约开发 Solidity学习
1. pragma solidity >=0.4.22 <0.6.0;//版本号,头文件 contract BooleanTest { bool _a;//默认返回false int nu ...
- iOS的常用类库
target 'NewCompass' do #UI通用 pod 'SVProgressHUD' pod 'MJRefresh' pod 'SnapKit' #pod 'RTRootNavigatio ...
- 爬虫selenium中截图
一.整个页面截图 driver = webdriver.Chrome() driver.get(url) diver.save_screenshot('保存路径') 二.局部截图 driver = w ...
- Spring Boot 2.2.2.RELEASE 版本中文参考文档【3.2 - 3.10】
Spring Boot 2.2.2.RELEASE版本中文文档持续更新中~如有需要获取参考文档文件,关注公众号JavaSo,回复“参考文档”即可. 3.2 结构化代码 Spring Boot不需要任何 ...