Sqoop架构
Sqoop 架构
Sqoop 架构是非常简单的,它主要由三个部分组成:Sqoop client、HDFS/HBase/Hive、Database。下面我们来看一下 Sqoop 的架构图。
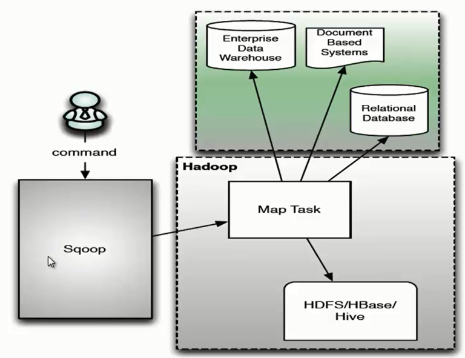
用户向 Sqoop 发起一个命令之后,这个命令会转换为一个基于 Map Task 的 MapReduce 作业。Map Task 会访问数据库的元数据信息,通过并行的 Map Task 将数据库的数据读取出来,然后导入 Hadoop 中。 当然也可以将 Hadoop 中的数据,导入传统的关系型数据库中。它的核心思想就是通过基于 Map Task (只有 map)的 MapReduce 作业,实现数据的并发拷贝和传输,这样可以大大提高效率。
Sqoop与HDFS结合
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出。
Sqoop import
它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示。

我们来分析一下 Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
下面我们看一下 Sqoop 如何使用命令行来导入数据的,其命令行语法如下所示。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--target-dir /junior/sqoop/ \ //可选,不指定目录,数据默认导入到/user下
--where "sex='female'" \ //可选
--as-sequencefile \ //可选,不指定格式,数据格式默认为 Text 文本格式
--num-mappers \ //可选,这个数值不宜太大
--null-string '\\N' \ //可选
--null-non-string '\\N' \ //可选
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名。
--table:要读取的数据库表。
--target-dir:将数据导入到指定的 HDFS 目录下,文件名称如果不指定的话,会默认数据库的表名称。
--where:过滤从数据库中要导入的数据。
--as-sequencefile:指定数据导入数据格式。
--num-mappers:指定 Map 任务的并发度。
--null-string,--null-non-string:同时使用可以将数据库中的空字段转化为'\N',因为数据库中字段为 null,会占用很大的空间。
下面我们介绍几种 Sqoop 数据导入的特殊应用。
1、Sqoop 每次导入数据的时候,不需要把以往的所有数据重新导入 HDFS,只需要把新增的数据导入 HDFS 即可,下面我们来看看如何导入新增数据。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--incremental append \ //代表只导入增量数据
--check-column id \ //以主键id作为判断条件
--last-value //导入id大于999的新增数据
上述三个组合使用,可以实现数据的增量导入。
2、Sqoop 数据导入过程中,直接输入明码存在安全隐患,我们可以通过下面两种方式规避这种风险。
1)-P:sqoop 命令行最后使用 -P,此时提示用户输入密码,而且用户输入的密码是看不见的,起到安全保护作用。密码输入正确后,才会执行 sqoop 命令。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--table user \
-P
2)--password-file:指定一个密码保存文件,读取密码。我们可以将这个文件设置为只有自己可读的文件,防止密码泄露。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--table user \
--password-file my-sqoop-password
Sqoop export
它的功能是将数据从 HDFS 导入关系型数据库表中,其流程图如下所示。
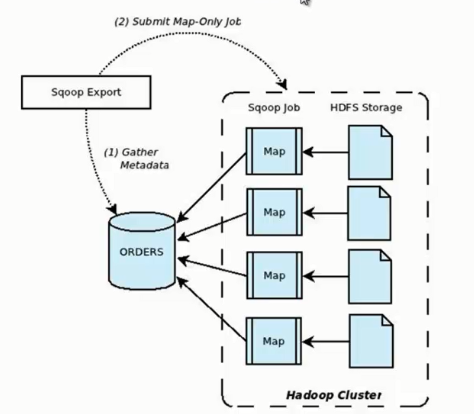
我们来分析一下 Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。
下面我们看一下 Sqoop 如何使用命令行来导出数据的,其命令行语法如下所示。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名和密码。
--table:要导入的数据库表。
--export-dir:数据在 HDFS 上的存放目录。
下面我们介绍几种 Sqoop 数据导出的特殊应用。
1、Sqoop export 将数据导入数据库,一般情况下是一条一条导入的,这样导入的效率非常低。这时我们可以使用 Sqoop export 的批量导入提高效率,其具体语法如下。
sqoop export \
--Dsqoop.export.records.per.statement= \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--export-dir user \
--batch
--Dsqoop.export.records.per.statement:指定每次导入10条数据,--batch:指定是批量导入。
2、在实际应用中还存在这样一个问题,比如导入数据的时候,Map Task 执行失败, 那么该 Map 任务会转移到另外一个节点执行重新运行,这时候之前导入的数据又要重新导入一份,造成数据重复导入。 因为 Map Task 没有回滚策略,一旦运行失败,已经导入数据库中的数据就无法恢复。Sqoop export 提供了一种机制能保证原子性, 使用--staging-table 选项指定临时导入的表。Sqoop export 导出数据的时候会分为两步:第一步,将数据导入数据库中的临时表,如果导入期间 Map Task 失败,会删除临时表数据重新导入;第二步,确认所有 Map Task 任务成功后,会将临时表名称为指定的表名称。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--staging-table staging_user
3、在 Sqoop 导出数据过程中,如果我们想更新已有数据,可以采取以下两种方式。
1)通过 --update-key id 更新已有数据。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--update-key id
2)使用 --update-key id和--update-mode allowinsert 两个选项的情况下,如果数据已经存在,则更新数据,如果数据不存在,则插入新数据记录。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--update-key id \
--update-mode allowinsert
4、如果 HDFS 中的数据量比较大,很多字段并不需要,我们可以使用 --columns 来指定插入某几列数据。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--column username,sex
5、当导入的字段数据不存在或者为null的时候,我们使用--input-null-string和--input-null-non-string 来处理。
sqoop export \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--input-null-string '\\N' \
--input-null-non-string '\\N'
Sqoop与其它系统结合
Sqoop 也可以与Hive、HBase等系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME、HIVE_HOME等环境变量。
1、Sqoop与Hive结合比较简单,使用 --hive-import 选项就可以实现。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--hive-import
2、Sqoop与HBase结合稍微麻烦一些,需要使用 --hbase-table 指定表名称,使用 --column-family 指定列名称。
sqoop import \
--connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
--username sqoop \
--password sqoop \
--table user \
--hbase-table user \
--column-family city
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Sqoop架构的更多相关文章
- Sqoop架构以及应用介绍
本篇文章在具体介绍Sqoop之前,先给大家用一个流程图介绍Hadoop业务的开发流程以及Sqoop在业务当中的实际地位. 如上图所示:在实际的业务当中,我们首先对原始数据集通过MapReduce进行 ...
- Sqoop架构(四)
Sqoop 架构是非常简单的,它主要由三个部分组成:Sqoop client.HDFS/HBase/Hive.Database. 下面是Sqoop 的架构图 (1)用户向 Sqoop 发起一个命令之后 ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- 初识sqoop
Sqoop 产生背景 Sqoop 的产生主要源于以下几种需求: 1.多数使用 Hadoop 技术处理大数据业务的企业,有大量的数据存储在传统的关系型数据库(RDBMS)中. 2.由于缺乏工具的支持,对 ...
- sqoop笔记
adoop学习笔记—18.Sqoop框架学习 一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数 ...
- sqoop学习
最近学习了下这个导数据的工具,但是在export命令这里卡住了,暂时排不了错误.先记录学习的这一点吧 sqoop是什么 sqoop(sql-on-hadoop):是用来实现结构型数据(如关系型数据库) ...
- Hadoop数据传输工具:Sqoop
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流.用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Had ...
- sqoop关系型数据迁移原理以及map端内存为何不会爆掉窥探
序:map客户端使用jdbc向数据库发送查询语句,将会拿到所有数据到map的客户端,安装jdbc的原理,数据全部缓存在内存中,但是内存没有出现爆掉情况,这是因为1.3以后,对jdbc进行了优化,改进j ...
- Sqoop简介及安装
Hadoop业务的大致开发流程以及Sqoop在业务中的地位: Sqoop概念 Sqoop可以理解为[SQL–to–Hadoop],正如名字所示,Sqoop是一个用来将关系型数据库和Hadoop中的数据 ...
随机推荐
- loadrunner的四个主要部件
1.VUser Generator :性能脚本开发 2.Controller :提供多线程并发操作 3.Analysis :结果分析 4.Load Generator :负载生成器 ***负载生成器完 ...
- div中嵌套的多个div使用了浮动后居中的办法
今天做网页的时候遇到了标题中的问题,网上查到了解决办法,记录一下一放以后忘记 <div class="wai"> <div style="float:l ...
- 初始String
--------------siwuxie095 使用频繁操作繁琐的数据有哪些? 对于基本数据类型:int.ch ...
- 面试题: Spring 框架 Bean的生命周期
[Java面试五]Spring总结以及在面试中的一些问题. 1.谈谈你对spring IOC和DI的理解,它们有什么区别? IoC Inverse of Control 反转控制的概念,就是将原本 ...
- PCLVisualizer可视化类(1)
PCLVisualizer可视化类是PCL中功能最全的可视化类,与CloudViewer可视化类相比,PCLVisualizer使用起来更为复杂,但该类具有更全面的功能,如显示法线.绘制多种形状和多个 ...
- Struts2学习第八课 声明式异常处理
异常处理:exception-mapping元素 exception-mapping元素:配置当前的action的声明式异常处理 exception-mapping元素有两个属性: --excepti ...
- Umbraco Examine Search (Lucene.net) french accent
在项目中使用Umbraco examine search 来search 法语网站时,客户有一个需求,就是 当search expérience 和 experience 时,需要返回一样的结果. ...
- 高考是最后一次拼智商的事了。(beacuse 大多数人的努力程度之低根本轮不到拼天赋!)
高考是最后一次拼智商的事. —因为大多数人的努力程度之低 根本轮不到拼天赋 在这个不起眼的小公司实习也有两周了,周四经理说说为了增加IOS开发小组和安卓开发小组之间的交流,准备每周开一次这种报告会. ...
- .net动态代理-EMIT,AOP实现
动态代理实现原理: 通过动态基础目标类,重写目标虚方法,.net中实现手段-il Emit.Proxy项目源码,https://github.com/1448376744/Emit.Proxy 以下是 ...
- HTML5学习笔记(六)web worker
当在 HTML 页面中执行脚本时,页面的状态是不可响应的,直到脚本已完成.web worker 是运行在后台的 JavaScript,不会影响页面的性能,页面可以响应. 在创建 web worker ...