三大文本处理工具grep、sed及awk
一、 用grep在文件中搜索文本
grep能够接受正则表达式,生成各种格式的输出。除此之外,它还有大量有趣的选项。
1、 搜索包含特定模式的文本行:
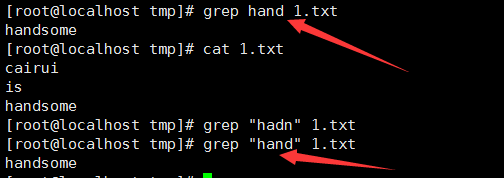
2、 从stdin中读取:

3、 单个grep命令可以对多个文件进行搜索:

4、 --color选项在输出行中着重标记出匹配到的单词:

5、 grep中使用正则表达式时使用(grep -E或者egrep)

6、 只输出文件中匹配到的文本部分,可以使用-o:

7、 要显示除匹配行外的所有行用-v选项:

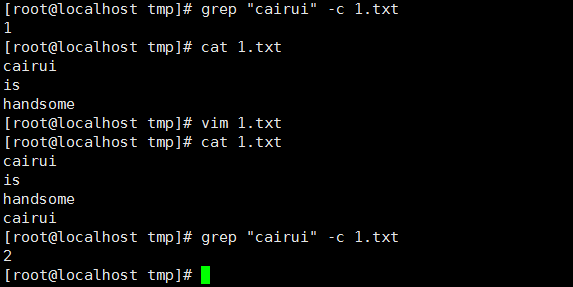
8、 统计文件或文本中包含匹配字符串的行数,-c(在单行出现多个匹配,只匹配一次):
9、 打印出包含匹配字符串的行号,-n:

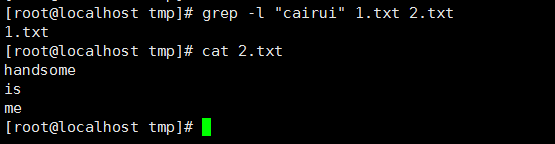
10、 搜索多个文件并找出匹配文本位于哪一个文件,-l(-L与之作用相反):
11、 递归搜素文件,-r(-R与之作用相同):

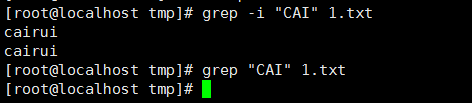
12、 忽略样式中的大小写,-i:
13、 用grep匹配多个样式,-e:

14、 在grep搜索中指定(--include)或排除(--exclude)文件:
目录中递归搜索所有的.c和.cpp文件

在搜索中排除所有的README文件

如果需要排除目录,使用--exclude-dir选项
15、 grep静默输出,-q:
不输出任何内容,如果成功匹配返回0,如果失败返回非0值。
16、 打印出匹配文本之前或之后的行:
[root@localhost tmp]# seq [root@localhost tmp]# seq | grep -A 3 #打印匹配的后指定行数 [root@localhost tmp]# seq | grep -B 3 #打印匹配前指定行数 [root@localhost tmp]# seq | grep -C 3 #打印匹配前后指定行数
二、 使用sed进行文本替换
sed是流编辑器(stream editor)的缩写。sed一个用法为文本替换。
[root@cairui ~]# sed --help
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]... -n, --quiet, --silent
suppress automatic printing of pattern space #取消自动打印模式空间
-e script, --expression=script
add the script to the commands to be executed #添加“脚本”到程序的运行列表
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed #添加“脚本文件”到程序的运行列表
--follow-symlinks
follow symlinks when processing in place; hard links
will still be broken.
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if extension supplied).
The default operation mode is to break symbolic and hard links.
This can be changed with --follow-symlinks and --copy.
-c, --copy
use copy instead of rename when shuffling files in -i mode.
While this will avoid breaking links (symbolic or hard), the
resulting editing operation is not atomic. This is rarely
the desired mode; --follow-symlinks is usually enough, and
it is both faster and more secure.
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
--help display this help and exit
--version output version information and exit If no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read. GNU sed home page: <http://www.gnu.org/software/sed/>.
General help using GNU software: <http://www.gnu.org/gethelp/>.
E-mail bug reports to: <bug-gnu-utils@gnu.org>.
Be sure to include the word ``sed'' somewhere in the ``Subject:'' field.
1、 sed可以替换给定文本的字符串:



该使用从stdin中读取输入,不影响原本的内容
2、默认情况下sed命令打印替换后的文本,如果想连原文本一起修改加-i命令,-i:
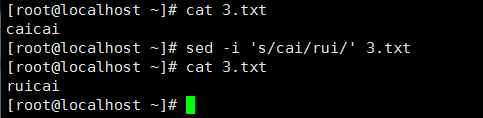
3、 之前的sed都是替换第一个匹配到的内容,想要全部替换就要在末尾加g:
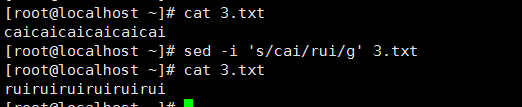
从第N个匹配开始替换

sed中的/为定界符,使用任何其他符号都可以替代

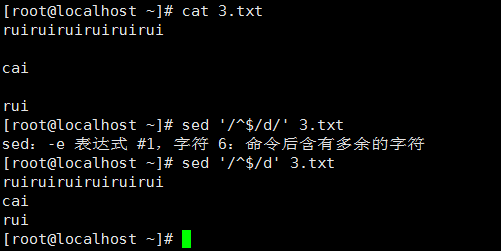
4、 移除空白行
三、 使用awk进行高级文本处理
awk是一款设计用于数据流的工具。它对列和行进行操作。awk有很多内建的功能,比如数组、函数等,和C有很多相同之处。awk最大的优势是灵活性。
[root@cairui ~]# awk --help
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options:
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
-m[fr] val
-O --optimize
-W compat --compat
-W copyleft --copyleft
-W copyright --copyright
-W dump-variables[=file] --dump-variables[=file]
-W exec=file --exec=file
-W gen-po --gen-po
-W help --help
-W lint[=fatal] --lint[=fatal]
-W lint-old --lint-old
-W non-decimal-data --non-decimal-data
-W profile[=file] --profile[=file]
-W posix --posix
-W re-interval --re-interval
-W source=program-text --source=program-text
-W traditional --traditional
-W usage --usage
-W use-lc-numeric --use-lc-numeric
-W version --version To report bugs, see node `Bugs' in `gawk.info', which is
section `Reporting Problems and Bugs' in the printed version. gawk is a pattern scanning and processing language.
By default it reads standard input and writes standard output. Examples:
gawk '{ sum += $1 }; END { print sum }' file
gawk -F: '{ print $1 }' /etc/passwd
awk脚本的结构基本如下所示:
awk ' BEGIN{ print "start" } pattern { commands } END { print "end" }' file
awk脚本通常由3部分组成。BEGIN,END和带模式匹配选项的常见语句块。这3个部分都是可选的。
1、工作原理
(1)执行BEGIN { commands }语句块中的语句。
(2)从文件或stdin中读取一行,然后执行pattern { commands }。重复这个过程,直到文件全部被读取完毕。
(3)当读至输入流末尾时,执行END { commands }语句块。
其中最重要的部分就是pattern语句块中的通用命令。这个语句块同样是可选的。如果不提供该语句块,则默认执行{ print },即打印所读取到的每一行。awk对于每一行,都会执行这个语句块。这就像一个用来读取行的while循环,在循环中提供了相应的语句。


三大文本处理工具grep、sed及awk的更多相关文章
- 【Linux】 字符串和文本处理工具 grep & sed & awk
Linux字符串&文本处理工具 因为用linux的时候主要用到的还是字符交互界面,所以对字符串的处理变得十分重要.这篇介绍三个常用的字符串处理工具,包括grep,sed和awk ■ grep ...
- 三大文本处理工具grep、sed及awk的简单介绍
grep.sed和awk都是文本处理工具,虽然都是文本处理工具单却都有各自的优缺点,一种文本处理命令是不能被另一个完全替换的,否则也不会出现三个文本处理命令了.只不过,相比较而言,sed和awk功能更 ...
- shell之三大文本处理工具grep、sed及awk
grep.sed和awk都是文本处理工具,虽然都是文本处理工具单却都有各自的优缺点,一种文本处理命令是不能被另一个完全替换的,否则也不会出现三个文本处理命令了.只不过,相比较而言,sed和awk功能更 ...
- 【OS_Linux】三大文本处理工具之sed命令
1.sed命令的简介及用法 sed:即为流编辑器,“stream editor”的缩写.他先将源文件读取到临时缓存区(也叫模式空间)中,再对满足匹配条件的各行执行sed命令.sed命令只针对缓存区中的 ...
- linux(5)--补充(管道| / 重定向> / xargs)/find 与xargs结合使用/vi,grep,sed,awk(支持正则表达式的工具程序)
本节中正则表达式的工具程序 grep,sed和awk是重点,也是难点!!! 先补充一下一. 管道| / 重定向> / xargs 如:1. 管道和重定向的区别:具体可以见 http://www. ...
- grep, sed 与 awk 补补课,到底怎么用!
grep, sed 与 awk 相当有用 ! gerp 查找, sed 编辑, awk 根据内容分析并处理. awk(关键字:分析&处理) 一行一行的分析处理 awk '条件类型1{动作1}条 ...
- 日志分析查看——grep,sed,sort,awk运用
概述 我们日常应用中都离不开日志.可以说日志是我们在排查问题的一个重要依据.但是日志并不是写了就好了,当你想查看日志的时候,你会发现线上日志堆积的长度已经超越了你一行行浏览的耐性的极限了.于是,很有必 ...
- Linux 文本处理工具grep,sed,awk
grep.sed和awk都是文本处理工具,虽然都是文本处理工具单却都有各自的优缺点,一种文本处理命令是不能被另一个完全替换的,否则也不会出现三个文本处理命令了.只不过,相比较而言,sed和awk功能更 ...
- 正则表达式学习之grep,sed和awk
正则表达式是用于描述字符排列和匹配模式的一种语法,它主要用于字符串的模式分割.匹配.查找以及替换操作. 描述一个正则表达式需要字符类.数量限定符.位置限定符.规定一些特殊语法表示字符类,数量限定符和位 ...
随机推荐
- Unreal Engine 4的常见Tips
转自:http://www.unrealchina.net/portal.php?mod=view&aid=66 退出游戏: UKismetSystemLibrary::QuitGame(th ...
- 发任务找不到test-unit报错
发任务的时候因找不到gem包test-unit报错, 出错行: require 'test/unit' require 'test/unit/testresult' 解决办法如下 1.通过命令查看ge ...
- TS封装格式
ts流最早应用于数字电视领域,其格式非常复杂包含的配置信息表多达十几个,视频格式主要是mpeg2.苹果公司发明的http live stream流媒体是基于ts文件的,不过他大大简化了传统的ts流,只 ...
- Qt opencv开发环境
在.pro文件中添加 INCLUDEPATH += C:\opencv\build\include\ #头文件路径 C:\opencv\build\include\opencv\ C:\opencv\ ...
- 使用Ping命令解析主机名解析出来的是IPv6
如果你经常使用ping命令,并身处局域网,那么你肯定会有这样一个疑问:Ping计算机名为何是IPv6地址? 问这个问题的人很少见,大多都是对网络知识稍有了解的人,所以才会闻到关于ping的问题,而且在 ...
- java获取多个汉字的拼音首字母
本文属于http://java.chinaitlab.com/base/803353.html原创!!! public class PinYin2Abbreviation { // 简体中文的编码范围 ...
- hibernate学习笔记(1)基础配置与jar包
下载hibernate基础jar包,并解压hibernate-core-4.2.4.final 在myeclipse中添加hibernate的dtd支持: location为D:\学习\imooc-h ...
- Android Studio 搭配 Tortoise SVN 安装问题汇总
(1)Android studio 中想要使用SVN,但是在安装 1.9版本的SVN,会报SVN is too old(实际是太新了)的错误.所以只能下载1.8以下版本 (2)安装svn时,需要手动选 ...
- scp命令 跨服务器传输
scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的.可能会稍微影响一下速度.当你服务器硬盘变为只读read onl ...
- day17-jdbc 8.ResultSet介绍
但是这些东西在mysql那里有问题.mysql的驱动不是很完善.getClob().getBlob()不好使不是因为程序的问题,而是因为mysql驱动的问题,oracle驱动就没有这个问题,证明ora ...