hadoop 学习笔记:mapreduce框架详解(转)
原文:http://www.cnblogs.com/sharpxiajun/p/3151395.html(有删减)
Mapreduce运行机制
下面我贴出几张图,这些图都是我在百度图片里找到的比较好的图片:
图片一:

图片二:
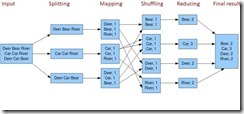
图片三:
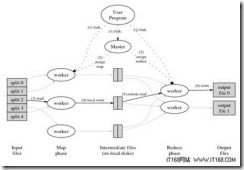
图片四:
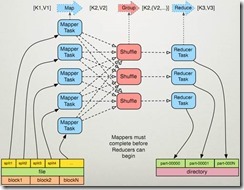
图片五:
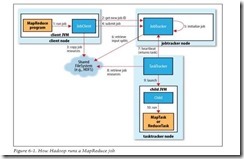
图片六:

谈mapreduce运行机制,可以从很多不同的角度来描述,比如说从mapreduce运行流程来讲解,也可以从计算模型的逻辑流程来进行讲解,也许有些深入理解了mapreduce运行机制还会从更好的角度来描述,但是将mapreduce运行机制有些东西是避免不了的,就是一个个参入的实例对象,一个就是计算模型的逻辑定义阶段,我这里讲解不从什么流程出发,就从这些一个个牵涉的对象,不管是物理实体还是逻辑实体。
首先讲讲物理实体,参入mapreduce作业执行涉及4个独立的实体:
1. 客户端(client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
2. JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行;
3. TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障,我会在后面的mapreduce的相关问题里讲到这个问题的)
4. Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
那么mapreduce到底是如何运行的呢?
首先是客户端要编写好mapreduce程序,配置好mapreduce的作业也就是job,接下来就是提交job了,提交job是提交到JobTracker上的,这个时候JobTracker就会构建这个job,具体就是分配一个新的job任务的ID值,接下来它会做检查操作,这个检查就是确定输出目录是否存在,如果存在那么job就不能正常运行下去,JobTracker会抛出错误给客户端,接下来还要检查输入目录是否存在,如果不存在同样抛出错误,如果存在JobTracker会根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误,至于输入分片我后面会做讲解的,这些都做好了JobTracker就会配置Job需要的资源了。分配好资源后,JobTracker就会初始化作业,初始化主要做的是将Job放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个job,初始化就是创建一个正在运行的job对象(封装任务和记录信息),以便JobTracker跟踪job的状态和进程。初始化完毕后,作业调度器会获取输入分片信息(input split),每个分片创建一个map任务。接下来就是任务分配了,这个时候tasktracker会运行一个简单的循环机制定期发送心跳给jobtracker,心跳间隔是5秒,程序员可以配置这个时间,心跳就是jobtracker和tasktracker沟通的桥梁,通过心跳,jobtracker可以监控tasktracker是否存活,也可以获取tasktracker处理的状态和问题,同时tasktracker也可以通过心跳里的返回值获取jobtracker给它的操作指令。任务分配好后就是执行任务了。在任务执行时候jobtracker可以通过心跳机制监控tasktracker的状态和进度,同时也能计算出整个job的状态和进度,而tasktracker也可以本地监控自己的状态和进度。当jobtracker获得了最后一个完成指定任务的tasktracker操作成功的通知时候,jobtracker会把整个job状态置为成功,然后当客户端查询job运行状态时候(注意:这个是异步操作),客户端会查到job完成的通知的。如果job中途失败,mapreduce也会有相应机制处理,一般而言如果不是程序员程序本身有bug,mapreduce错误处理机制都能保证提交的job能正常完成。
下面我从逻辑实体的角度讲解mapreduce运行机制,这些按照时间顺序包括:输入分片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。
1. 输入分片(input split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件,那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
2. map阶段:就是程序员编写好的map函数了,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行;
3. combiner阶段:combiner阶段是程序员可以选择的,combiner其实也是一种reduce操作,因此我们看见WordCount类里是用reduce进行加载的。Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,例如我们对文件里的单词频率做统计,map计算时候如果碰到一个hadoop的单词就会记录为1,但是这篇文章里hadoop可能会出现n多次,那么map输出文件冗余就会很多,因此在reduce计算前对相同的key做一个合并操作,那么文件会变小,这样就提高了宽带的传输效率,毕竟hadoop计算力宽带资源往往是计算的瓶颈也是最为宝贵的资源,但是combiner操作是有风险的,使用它的原则是combiner的输入不会影响到reduce计算的最终输入,例如:如果计算只是求总数,最大值,最小值可以使用combiner,但是做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
4. shuffle阶段:将map的输出作为reduce的输入的过程就是shuffle了,这个是mapreduce优化的重点地方。这里我不讲怎么优化shuffle阶段,讲讲shuffle阶段的原理,因为大部分的书籍里都没讲清楚shuffle阶段。Shuffle一开始就是map阶段做输出操作,一般mapreduce计算的都是海量数据,map输出时候不可能把所有文件都放到内存操作,因此map写入磁盘的过程十分的复杂,更何况map输出时候要对结果进行排序,内存开销是很大的,map在做输出时候会在内存里开启一个环形内存缓冲区,这个缓冲区专门用来输出的,默认大小是100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80(这个大小和阀值都是可以在配置文件里进行配置的),同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作,前面我讲到写入磁盘前会有个排序操作,这个是在写入磁盘操作时候进行,不是在写入内存时候进行的,如果我们定义了combiner函数,那么排序前还会执行combiner操作。每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件。这个过程里还会有一个Partitioner操作,对于这个操作很多人都很迷糊,其实Partitioner操作和map阶段的输入分片(Input split)很像,一个Partitioner对应一个reduce作业,如果我们mapreduce操作只有一个reduce操作,那么Partitioner就只有一个,如果我们有多个reduce操作,那么Partitioner对应的就会有多个,Partitioner因此就是reduce的输入分片,这个程序员可以编程控制,主要是根据实际key和value的值,根据实际业务类型或者为了更好的reduce负载均衡要求进行,这是提高reduce效率的一个关键所在。到了reduce阶段就是合并map输出文件了,Partitioner会找到对应的map输出文件,然后进行复制操作,复制操作时reduce会开启几个复制线程,这些线程默认个数是5个,程序员也可以在配置文件更改复制线程的个数,这个复制过程和map写入磁盘过程类似,也有阀值和内存大小,阀值一样可以在配置文件里配置,而内存大小是直接使用reduce的tasktracker的内存大小,复制时候reduce还会进行排序操作和合并文件操作,这些操作完了就会进行reduce计算了。
5. reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。
Mapreduce的相关问题
这里我要谈谈我学习mapreduce思考的一些问题,都是我自己想出解释的问题,但是某些问题到底对不对,就要广大童鞋帮我确认了。
1. jobtracker的单点故障:jobtracker和hdfs的namenode一样也存在单点故障,单点故障一直是hadoop被人诟病的大问题,为什么hadoop的做的文件系统和mapreduce计算框架都是高容错的,但是最重要的管理节点的故障机制却如此不好,我认为主要是namenode和jobtracker在实际运行中都是在内存操作,而做到内存的容错就比较复杂了,只有当内存数据被持久化后容错才好做,namenode和jobtracker都可以备份自己持久化的文件,但是这个持久化都会有延迟,因此真的出故障,任然不能整体恢复,另外hadoop框架里包含zookeeper框架,zookeeper可以结合jobtracker,用几台机器同时部署jobtracker,保证一台出故障,有一台马上能补充上,不过这种方式也没法恢复正在跑的mapreduce任务。
2. 做mapreduce计算时候,输出一般是一个文件夹,而且该文件夹是不能存在,我在出面试题时候提到了这个问题,而且这个检查做的很早,当我们提交job时候就会进行,mapreduce之所以这么设计是保证数据可靠性,如果输出目录存在reduce就搞不清楚你到底是要追加还是覆盖,不管是追加和覆盖操作都会有可能导致最终结果出问题,mapreduce是做海量数据计算,一个生产计算的成本很高,例如一个job完全执行完可能要几个小时,因此一切影响错误的情况mapreduce是零容忍的。
3. Mapreduce还有一个InputFormat和OutputFormat,我们在编写map函数时候发现map方法的参数是之间操作行数据,没有牵涉到InputFormat,这些事情在我们new Path时候mapreduce计算框架帮我们做好了,而OutputFormat也是reduce帮我们做好了,我们使用什么样的输入文件,就要调用什么样的InputFormat,InputFormat是和我们输入的文件类型相关的,mapreduce里常用的InputFormat有FileInputFormat普通文本文件,SequenceFileInputFormat是指hadoop的序列化文件,另外还有KeyValueTextInputFormat。OutputFormat就是我们想最终存储到hdfs系统上的文件格式了,这个根据你需要定义了,hadoop有支持很多文件格式,这里不一一列举,想知道百度下就看到了。
hadoop 学习笔记:mapreduce框架详解(转)的更多相关文章
- Hadoop学习笔记2---配置详解
配置系统是复杂软件必不可少的一部分,而Hadoop配置信息处理是学习Hadoop源代码的一个很好的起点.现在就从Hadoop的配置文件谈起. 一.Hadoop配置格式 Hadoop配置文件格式如下所示 ...
- mapreduce框架详解
hadoop 学习笔记:mapreduce框架详解 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感 ...
- expect学习笔记及实例详解【转】
1. expect是基于tcl演变而来的,所以很多语法和tcl类似,基本的语法如下所示:1.1 首行加上/usr/bin/expect1.2 spawn: 后面加上需要执行的shell命令,比如说sp ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- mapreduce框架详解【转载】
[本文转载自:http://www.cnblogs.com/sharpxiajun/p/3151395.html] 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoo ...
- Struts2学习笔记(二)——配置详解
1.Struts2配置文件加载顺序: default.properties(默认常量配置) struts-default.xml(默认配置文件,主要配置bean和拦截器) struts-plugin. ...
- Struts2学习笔记二 配置详解
Struts2执行流程 1.简单执行流程,如下所示: 在浏览器输入请求地址,首先会被过滤器处理,然后查找主配置文件,然后根据地址栏中输入的/hello去每个package中查找为/hello的name ...
- Docker技术入门与实战 第二版-学习笔记-3-Dockerfile 指令详解
前面已经讲解了FROM.RUN指令,还提及了COPY.ADD,接下来学习其他的指令 5.Dockerfile 指令详解 1> COPY 复制文件 格式: COPY <源路径> .. ...
随机推荐
- 设置VisualSVN在提交修改时必须输入一定数量的备注信息
我发现在使用SVN中,提交时,很多人不习惯填写备注信息,虽然在培训中.平时使用时多次提醒备注信息的好处,但是效果不大,每次提交时还是不写,或者随便写两字. 所以很有必要通过系统设置强制填写足够数量的备 ...
- 利用NIO的Selector处理服务器-客户端模型
package NIOTEST; import java.io.IOException; import java.net.InetAddress; import java.net.InetSocket ...
- ulimit的坑
linux ulimit的若干坑 - ulimit真不是乱设的 原创 2016年11月16日 22:15:05 标签: linux 1997 soft和hard一起设置才好使 * soft nofil ...
- 昂贵的聘礼 - poj 1062 (Dijkstra+枚举)
Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 39976 Accepted: 11596 Description 年 ...
- COM线程单元
节选自C#高级编程 不管是单线程单元还是多线程单元,一个线程只能属于一个单元. 1) 单线程单元(apartment, 寓所,套间) 单线程单元与它拥有的线程是一对一的关系.COM对象在编写时不是线程 ...
- mxnet编译问题手记
MXNet在64位Win7下的编译安装:https://www.cnblogs.com/noahzn/p/5506086.html http://blog.csdn.net/Jarvis_wxy/ar ...
- 浅谈<持续集成、持续交付、持续部署>(一)
谈谈持续集成,持续交付,持续部署之间的区别 经常会听到持续集成,持续交付,持续部署,三者究竟是什么,有何联系和区别呢? 假如把开发工作流程分为以下几个阶段: 编码 -> 构建 -> 集 ...
- ArcGIS API for JavaScript Bookmarks(书签)
说明:本篇博文介绍的是ArcGIS API for JavaScript中的 Bookmarks(书签) ,书签的作用是,把地图放大到一个地方 添加书签,书签名称可以和地图名称一直,单击标签 地图会定 ...
- Image Recognition
https://www.tensorflow.org/tutorials/image_recognition
- Android代码绘制虚线、圆角、渐变效果图
drawable文件夹放置动画/形状/选择器等属性文件,唯一的drawable文件名,不允许写错和拼错,否则运行报错.drawable文件夹底下的xml文件可以包括的标签共18个:animation- ...