Classification of text documents: using a MLComp dataset
注:原文代码链接http://scikit-learn.org/stable/auto_examples/text/mlcomp_sparse_document_classification.html
运行结果为:
Loading 20 newsgroups training set...
20 newsgroups dataset for document classification (http://people.csail.mit.edu/jrennie/20Newsgroups)
13180 documents
20 categories
Extracting features from the dataset using a sparse vectorizer
done in 139.231000s
n_samples: 13180, n_features: 130274
Loading 20 newsgroups test set...
done in 0.000000s
Predicting the labels of the test set...
5648 documents
20 categories
Extracting features from the dataset using the same vectorizer
done in 7.082000s
n_samples: 5648, n_features: 130274
Testbenching a linear classifier...
parameters: {'penalty': 'l2', 'loss': 'hinge', 'alpha': 1e-05, 'fit_intercept': True, 'n_iter': 50}
done in 22.012000s
Percentage of non zeros coef: 30.074190
Predicting the outcomes of the testing set
done in 0.172000s
Classification report on test set for classifier:
SGDClassifier(alpha=1e-05, average=False, class_weight=None, epsilon=0.1,
eta0=0.0, fit_intercept=True, l1_ratio=0.15,
learning_rate='optimal', loss='hinge', n_iter=50, n_jobs=1,
penalty='l2', power_t=0.5, random_state=None, shuffle=True,
verbose=0, warm_start=False) precision recall f1-score support alt.atheism 0.95 0.93 0.94 245
comp.graphics 0.85 0.91 0.88 298
comp.os.ms-windows.misc 0.88 0.88 0.88 292
comp.sys.ibm.pc.hardware 0.82 0.80 0.81 301
comp.sys.mac.hardware 0.90 0.92 0.91 256
comp.windows.x 0.92 0.88 0.90 297
misc.forsale 0.87 0.89 0.88 290
rec.autos 0.93 0.94 0.94 324
rec.motorcycles 0.97 0.97 0.97 294
rec.sport.baseball 0.97 0.97 0.97 315
rec.sport.hockey 0.98 0.99 0.99 302
sci.crypt 0.97 0.96 0.96 297
sci.electronics 0.87 0.89 0.88 313
sci.med 0.97 0.97 0.97 277
sci.space 0.97 0.97 0.97 305
soc.religion.christian 0.95 0.96 0.95 293
talk.politics.guns 0.94 0.94 0.94 246
talk.politics.mideast 0.97 0.99 0.98 296
talk.politics.misc 0.96 0.92 0.94 236
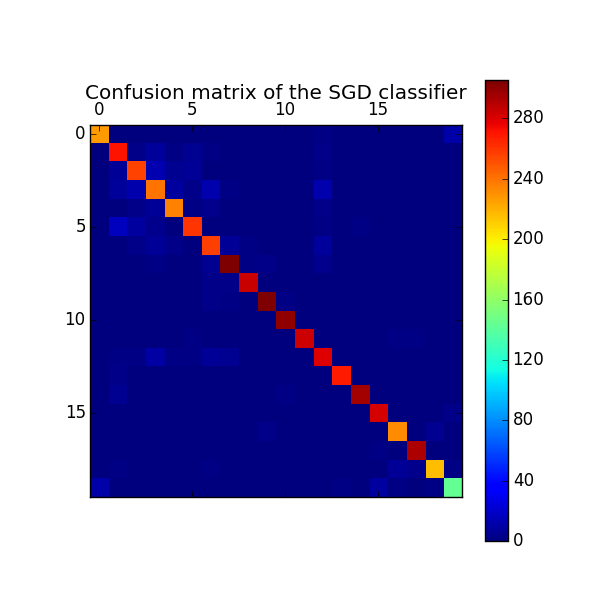
talk.religion.misc 0.89 0.84 0.86 171 avg / total 0.93 0.93 0.93 5648 Confusion matrix:
[[227 0 0 0 0 0 0 0 0 0 0 1 2 1 1 1 0 1
0 11]
[ 0 271 3 8 2 5 2 0 0 1 0 0 3 1 1 0 0 1
0 0]
[ 0 7 256 14 5 6 1 0 0 0 0 0 2 0 1 0 0 0
0 0]
[ 1 8 12 240 9 3 12 2 0 0 0 1 12 0 0 1 0 0
0 0]
[ 0 1 3 6 235 2 4 0 0 0 0 1 3 0 1 0 0 0
0 0]
[ 0 17 9 4 0 260 0 0 1 1 0 0 2 0 2 0 1 0
0 0]
[ 0 1 3 7 3 0 257 7 2 0 0 1 8 0 1 0 0 0
0 0]
[ 0 0 0 2 1 0 5 305 2 3 0 0 4 1 0 0 1 0
0 0]
[ 0 0 0 0 1 0 3 3 285 0 0 0 1 0 0 1 0 0
0 0]
[ 0 0 0 0 0 0 3 2 0 305 2 1 1 0 0 0 0 0
1 0]
[ 0 0 0 0 0 0 1 0 1 0 300 0 0 0 0 0 0 0
0 0]
[ 0 0 1 1 0 2 0 1 0 0 0 284 0 1 1 0 2 2
1 1]
[ 0 2 2 10 2 2 6 5 1 0 1 1 279 1 1 0 0 0
0 0]
[ 0 3 0 0 1 1 1 0 0 0 0 0 0 269 0 1 1 0
0 0]
[ 0 5 0 0 1 0 0 0 0 0 2 0 1 0 295 0 0 0
1 0]
[ 1 1 1 0 0 1 0 1 0 0 0 0 0 1 1 282 1 0
0 3]
[ 0 0 1 0 0 0 0 0 1 3 0 0 1 0 0 1 232 1
5 1]
[ 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 2 0 293
0 0]
[ 0 2 0 0 0 0 2 0 0 1 0 1 0 1 0 0 7 4
216 2]
[ 11 0 0 0 0 0 0 0 0 0 0 1 0 2 0 9 2 1
2 143]]
Testbenching a MultinomialNB classifier...
parameters: {'alpha': 0.01}
done in 0.608000s
Percentage of non zeros coef: 100.000000
Predicting the outcomes of the testing set
done in 0.203000s
Classification report on test set for classifier:
MultinomialNB(alpha=0.01, class_prior=None, fit_prior=True) precision recall f1-score support alt.atheism 0.90 0.92 0.91 245
comp.graphics 0.81 0.89 0.85 298
comp.os.ms-windows.misc 0.87 0.83 0.85 292
comp.sys.ibm.pc.hardware 0.82 0.83 0.83 301
comp.sys.mac.hardware 0.90 0.92 0.91 256
comp.windows.x 0.90 0.89 0.89 297
misc.forsale 0.90 0.84 0.87 290
rec.autos 0.93 0.94 0.93 324
rec.motorcycles 0.98 0.97 0.97 294
rec.sport.baseball 0.97 0.97 0.97 315
rec.sport.hockey 0.97 0.99 0.98 302
sci.crypt 0.95 0.95 0.95 297
sci.electronics 0.90 0.86 0.88 313
sci.med 0.97 0.96 0.97 277
sci.space 0.95 0.97 0.96 305
soc.religion.christian 0.91 0.97 0.94 293
talk.politics.guns 0.89 0.96 0.93 246
talk.politics.mideast 0.95 0.98 0.97 296
talk.politics.misc 0.93 0.87 0.90 236
talk.religion.misc 0.92 0.74 0.82 171 avg / total 0.92 0.92 0.92 5648 Confusion matrix:
[[226 0 0 0 0 0 0 0 0 1 0 0 0 0 2 7 0 0
0 9]
[ 1 266 7 4 1 6 2 2 0 0 0 3 4 1 1 0 0 0
0 0]
[ 0 11 243 22 4 7 1 0 0 0 0 1 2 0 0 0 0 0
1 0]
[ 0 7 12 250 8 4 9 0 0 1 1 0 9 0 0 0 0 0
0 0]
[ 0 3 3 5 235 2 3 1 0 0 0 2 1 0 1 0 0 0
0 0]
[ 0 19 5 3 2 263 0 0 0 0 0 1 0 1 1 0 2 0
0 0]
[ 0 1 4 9 3 1 243 9 2 3 1 0 8 0 0 0 2 2
2 0]
[ 0 0 0 1 1 0 5 304 1 2 0 0 3 2 3 1 1 0
0 0]
[ 0 0 0 0 0 2 2 3 285 0 0 0 1 0 0 0 0 0
0 1]
[ 0 1 0 0 0 1 1 3 0 304 5 0 0 0 0 0 0 0
0 0]
[ 0 0 0 0 0 0 0 0 1 2 299 0 0 0 0 0 0 0
0 0]
[ 0 2 2 1 0 1 2 0 0 0 0 283 1 0 0 0 2 1
2 0]
[ 0 11 1 9 3 1 3 5 1 0 1 4 270 1 3 0 0 0
0 0]
[ 0 2 0 1 1 1 0 0 0 0 0 1 0 266 2 1 0 0
2 0]
[ 0 2 0 0 1 0 0 0 0 0 0 2 1 1 296 0 1 1
0 0]
[ 3 1 0 0 0 0 0 0 0 0 1 0 0 2 0 283 0 1
2 0]
[ 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 237 1
3 1]
[ 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 3 0 291
0 0]
[ 1 1 0 0 1 1 0 1 0 0 0 0 0 0 1 1 17 6
206 0]
[ 18 1 0 0 0 0 0 0 0 1 0 0 0 0 0 14 4 2
4 127]]
步骤为:
一、preprocessing
1.加载训练集(training set)
2.训练集特征提取,用TfidfVectorizer,得到训练集上的x_train和y_train
3.加载测试集(test set)
4.测试集特征提取,用TfidfVectorizer,得到测试集上的x_train和y_train
二、定义Benchmark classifiers
5.训练,clf = clf_class(**params).fit(X_train, y_train)
6.测试,pred = clf.predict(X_test)
7.测试集上分类报告,print(classification_report(y_test, pred,target_names=news_test.target_names))
8.confusion matrix,cm = confusion_matrix(y_test, pred)
三、训练
9.调用两个分类器,SGDClassifier和MultinomialNB

Classification of text documents: using a MLComp dataset的更多相关文章
- Clustering text documents using k-means
源代码的链接为http://scikit-learn.org/stable/auto_examples/text/document_clustering.html Loading 20 newsgro ...
- scikit-learn:4.2.3. Text feature extraction
http://scikit-learn.org/stable/modules/feature_extraction.html 4.2节内容太多,因此将文本特征提取单独作为一块. 1.the bag o ...
- Python scikit-learn机器学习工具包学习笔记
feature_selection模块 Univariate feature selection:单变量的特征选择 单变量特征选择的原理是分别单独的计算每个变量的某个统计指标,根据该指标来判断哪些指标 ...
- 特征选择 (feature_selection)
目录 特征选择 (feature_selection) Filter 1. 移除低方差的特征 (Removing features with low variance) 2. 单变量特征选择 (Uni ...
- sklearn—特征工程
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- scikit-learn:3.3. Model evaluation: quantifying the quality of predictions
參考:http://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter 三种方法评估模型的预測质量: Est ...
- [Scikit-learn] 1.1 Generalized Linear Models - Comparing various online solvers
数据集分割 一.Online learning for 手写识别 From: Comparing various online solvers An example showing how diffe ...
- [Scikit-learn] Yield miniBatch for online learning.
From: Out-of-core classification of text documents Code: """ ======================= ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
随机推荐
- c printf()详解[转载]
ref : http://www.cnblogs.com/yuaqua/archive/2011/10/21/2219856.html #include <cstdio> #include ...
- eclipse提升注解提示速度
preference--输入content--java--editor--content Assist--aoto delay 选项 改为100或者更低 提示速度 --ao ...
- VS2010+PCL+openni配置
PCL中文论坛:http://www.pclcn.org/bbs/forum.php 1.安装 pcl 的完全安装包可以到: http://pointclouds.org/downloads/wind ...
- C语言EOF
验证表达式getchar()!=EOF的值是1还是0 编写一个打印EOF值的程序 windows下是ctrl-z 就是ctrl和z一起按了,就是结束符linux下是ctrl-d是结束符.这个是一个 ...
- HDU1874 最短路 SPFA
最短路 Time Limit: 1 Sec Memory Limit: 128 MB Submit: 24 Solved: 17 [Submit][Status][Web Board] Descr ...
- UVALive 2147 Push!!(队列实现DP)
就我的理解来说这个题,本质上是一个DP题,不应该说是搜索,因为我的做法是把表格中所有的数据都找到,使用队列暴力来遍历出所有状态,因为题目中的数据范围小,所有耗时也小. 首先分析箱子是一个被动物体,人是 ...
- poj 2594 Treasure Exploration(最小路径覆盖,可重点)
题意:选出最小路径覆盖图中所有点,路径可以交叉,也就是允许路径有重复的点. 分析:这个题的难点在于如何解决有重复点的问题-方法就是使用Floyd求闭包,就是把间接相连的点直接连上边,然后就是求最小路径 ...
- html5 之本地数据存储
HTML5 提供了两种在客户端存储数据的新方法: localStorage - 没有时间限制的数据存储 sessionStorage - 针对一个 session 的数据存储 cookie与webSt ...
- c++ 显示调用dll
首先需要引入:#include<windows.h> 否则会出现 HINSTANCE 未定义的错误
- string转化为int方法
int intA = 0; 1.intA =int.Parse(str); 2.int.TryParse(str, out intA); 3.intA = Convert.ToInt32(str);以 ...