用python解析word文件(二):table
(二)表格篇(table)(本篇)
选你所需即可。下面开始正文。
docx.tables
cell.text

for t in docx.tables:
# todo
_table_list = []
for i, row in enumerate(table.rows): # 读每行
row_content = []
for cell in row.cells: # 读一行中的所有单元格
c = cell.text
if c not in row_content:
row_content.append(c)
# print(row_content)
_table_list.append(row_content)
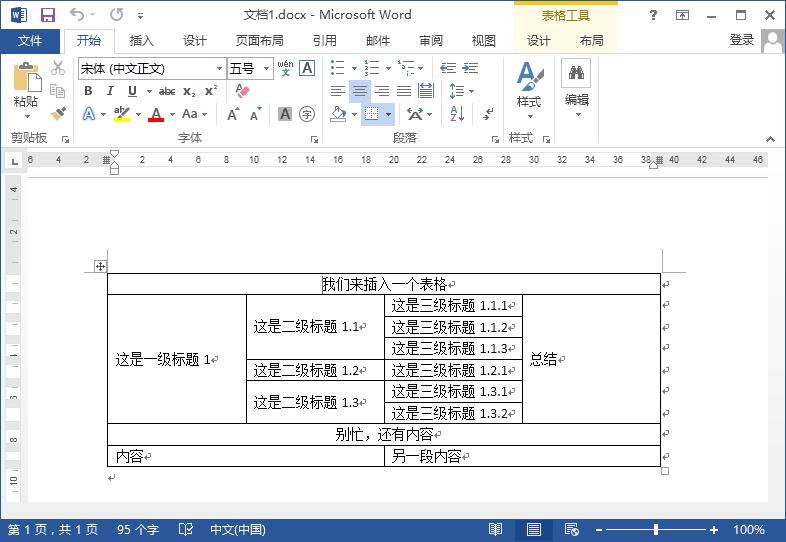
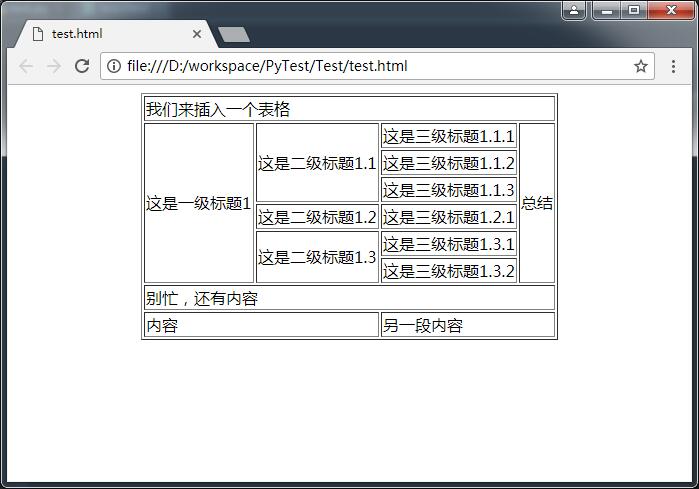
['我们来插入一个表格']
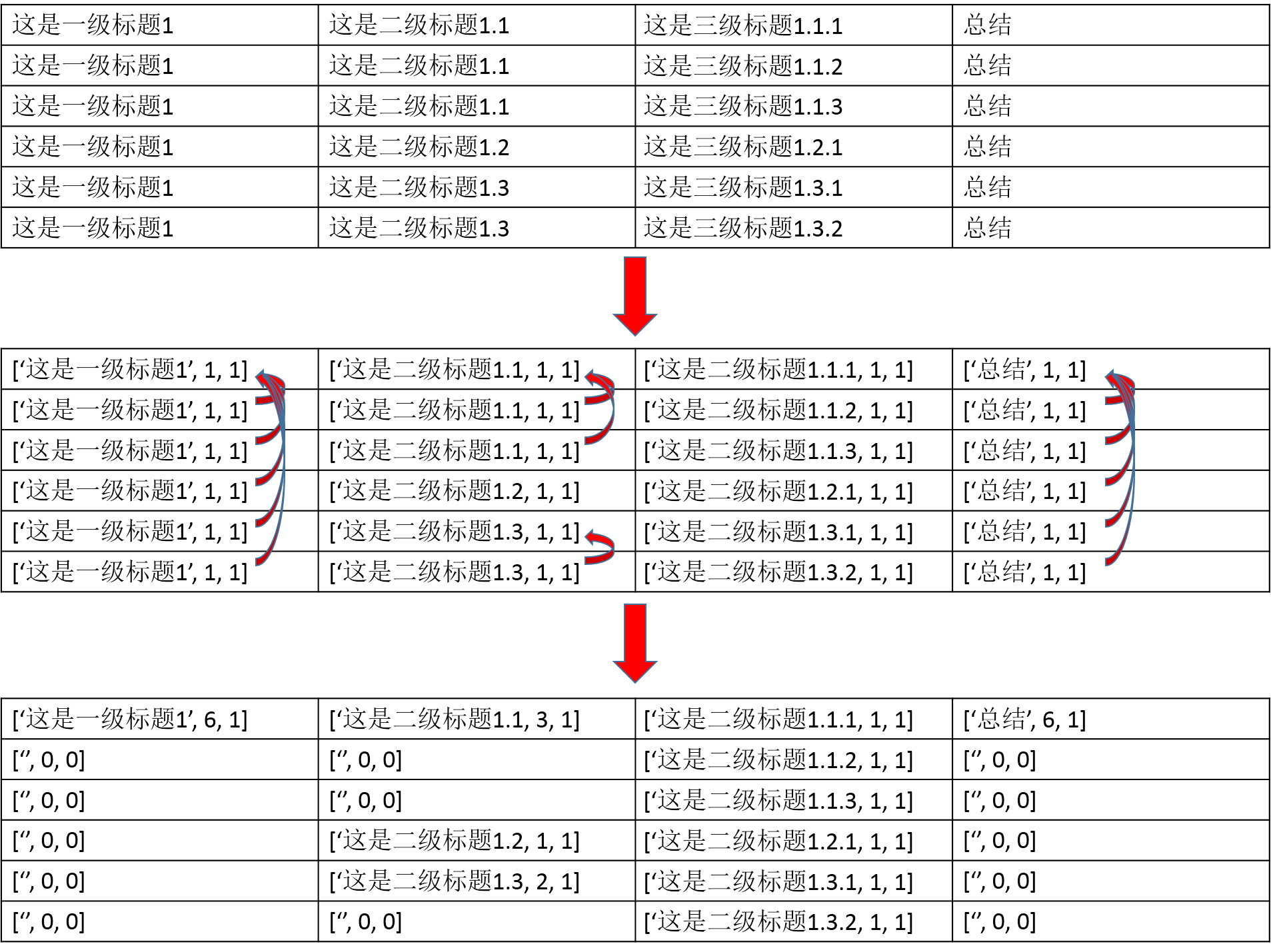
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结']
['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结']
['别忙,还有内容']
['内容', '另一段内容']
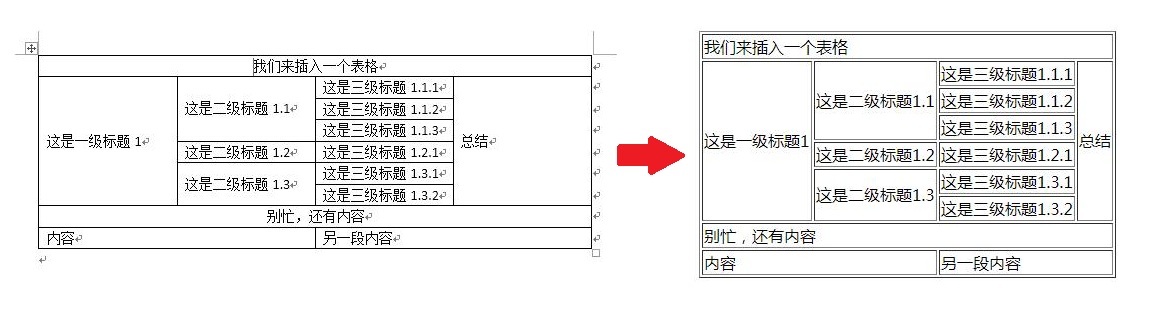
def _fill_blank(table):
cols = max([len(i) for i in table]) new_table = []
for i, row in enumerate(table):
new_row = []
[new_row.extend([i] * int(cols / len(row))) for i in row]
print(new_row)
new_table.append(new_row) return new_table
['我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结']
['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结']
['别忙,还有内容', '别忙,还有内容', '别忙,还有内容', '别忙,还有内容']
['内容', '内容', '另一段内容', '另一段内容']
<table border="1" align="center">
<tr align="center"><td colspan="4">Row One</td></tr>
<tr align="center"><td>Row Two</td><td>Row Two</td><td>Row Two</td><td>Row Two</td></tr>
</table>

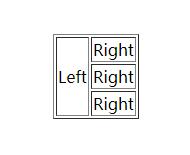
<table border="1" align="center">
<tr><td rowspan="3">Left</td><td>Right</td></tr>
<tr><td>Right</td></tr>
<tr><td>Right</td></tr>
</table>
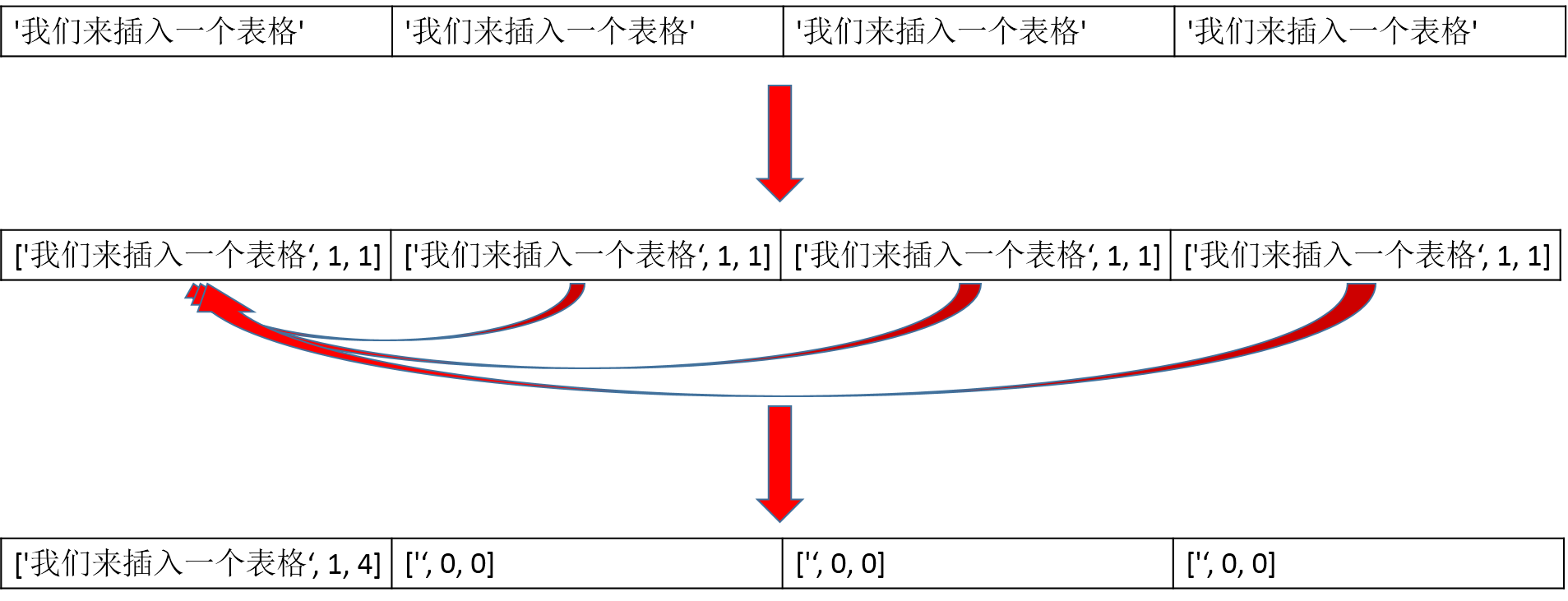
def _table_matrix():
if not table:
return "" # 处理同一行的各列
temp_matrix = []
for row in table:
if not row:
continue col_last = [row[0], 1, 1]
line = [col_last]
for i, j in enumerate(row):
if i == 0:
continue if j == col_last[0]:
col_last[2] += 1
line.append(["", 0, 0])
else:
col_last = [j, 1, 1]
line.append(col_last) temp_matrix.append(line) # 处理不同行
matrix = [temp_matrix[0]]
last_row = []
for i, row in enumerate(temp_matrix):
if i == 0:
last_row.extend(row)
continue new_row = []
for p, r in enumerate(row):
if p >= len(last_row):
break last_pos = last_row[p] if r[0] == last_pos[0] and last_pos[0] != "":
last_row[p][1] += 1
new_row.append(["", 0, 0])
else:
last_row[p] = row[p]
new_row.append(r) matrix.append(new_row) return matrix
def table2html(t):
table = _fill_blank(t)
matrix = _table_matrix(table) html = ""
for row in matrix:
tr = "<tr>"
for col in row:
if col[1] == 0 and col[2] == 0:
continue td = ["<td"]
if col[1] > 1:
td.append(" rowspan=\"%s\"" % col[1])
if col[2] > 1:
td.append(" colspan=\"%s\"" % col[2])
td.append(">%s</td>" % col[0]) tr += "".join(td)
tr += "</tr>"
html += tr return html
{{ table|safe }}
用python解析word文件(二):table的更多相关文章
- 用python解析word文件(一):paragraph
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph)(本篇) (二)表格篇(table) (三)样式篇(style) 选你所需即可.下面开始正文. 最近公司的项目,需要在页面上显示w ...
- 用python解析word文件(三):style
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph) (二)表格篇(table) (三)样式篇(style)(本篇) 选你所需即可.下面开始正文. 在前两篇中,我们已经解析出了par ...
- 用python解析word文件(段落篇(paragraph) 表格篇(table) 样式篇(style))
首先需要安装相应的支持库: 直接在命令行执行pip install python-docx 示例代码如下: import docxfrom docx import Document #导入库 path ...
- 用python读取word文件里的表格信息【华为云技术分享】
在企查查查询企业信息的时候,得到了一些word文件,里面有些控股企业的数据放在表格里,需要我们将其提取出来. word文件看起来很复杂,不方便进行结构化.实际上,一个word文档中大概有这么几种类型的 ...
- Python解析excel文件并存入sqlite数据库
最近由于工作上的需求 需要使用Python解析excel文件并存入sqlite 就此做个总结 功能:1.数据库设计 建立数据库2.Python解析excel文件3.Python读取文件名并解析4.将解 ...
- C#仪器数据文件解析-Word文件(doc、docx)
不少仪器数据报告输出为Word格式文件,同Excel文件,Word文件doc和docx的存储格式是不同的,相应的解析Word文件的方式也类似,主要有以下方式: 1.通过MS Word应用程序的DCOM ...
- Python处理word文件
python对word文件进行读写和复制 import win32conimport win32com.clientimport os #读取word文件def readWoldFile(path): ...
- Python解析Wav文件并绘制波形的方法
资源下载 #本文PDF版下载 Python解析Wav文件并绘制波形的方法 #本文代码下载 Wav波形绘图代码 #本文实例音频文件night.wav下载 音频文件下载 (石进-夜的钢琴曲) 前言 在现在 ...
- 用Python将word文件转换成html(转)
用Python将word文件转换成html 序 最近公司一个客户大大购买了一堆医疗健康方面的科普文章,希望能放到我们正在开发的健康档案管理软件上.客户大大说,要智能推送!要掌握节奏!要深度学习!要 ...
随机推荐
- Deep Q-Network 学习笔记(五)—— 改进③:Prioritized Replay 算法
也就是优先采样,这里的推导部分完全没看懂 Orz,这里也只是记录实现代码. 也就是看了以下两篇文章对应做了实现. 莫烦老师的教程: https://morvanzhou.github.io/tutor ...
- 为什么有int 和integer
1.Integer 是对象类型 int是原始类型 适用场合有很大的不同 之所以要把int封装成Integer 型 是因为 很多方法参数就只接收对象类型(Object) 还比如 范型 就只支持 对象类型 ...
- C# 小软件部分(二)
此次又新增了一些新的功能,直接接着上次的介绍吧 上次博客介绍地址:http://www.cnblogs.com/Liyuting/p/8540592.html 这次新增了三个功能,具体如下: 一.网 ...
- JS 重写alert,使之能输出多个参数
windows._alert = windows.alert; windows.alert = function(){ _alert = (Array.prototype.slice(argument ...
- CSS3选择器:nth-child和:nth-of-type之间的差异——张鑫旭
一.深呼吸,直接内容 :nth-child和:nth-of-type都是CSS3中的伪类选择器,其作用近似却又不完全一样,对于不熟悉的人对其可能不是很区分,本文就将介绍两者的不同,以便于大家正确灵活使 ...
- HTTPS 常见部署问题及解决方案
在最近几年里,我写了很多有关 HTTPS 和 HTTP/2 的文章,涵盖了证书申请.Nginx 编译及配置.性能优化等方方面面.在这些文章的评论中,不少读者提出了各种各样的问题,我的邮箱也经常收到类似 ...
- Hello world &博客客户端试用
第一篇博客,使用 open live writer客户端进行测试,下载地址见http://openlivewriter.org/,软件为英文,但配置比较简单,选择“其他博客类型”就ok. 同时安装了语 ...
- Oracle数据库进行撤销
第一步:在v$sqlarea 这视图里面找到你操作那条SQL的时间;select r.FIRST_LOAD_TIME,r. from v$sqlarea r order by r.FIRST_LOAD ...
- css之背景(background)家族
背景(background)是css中很重要的一部分,也是css的基础知道之一,现在来回顾css2中5个属性与css3中新增的3个属性和2个功能. CSS2_背景(background)前传 家族成员 ...
- 菜鸟的HTML学习之路
开发网站流程 确定风格.功能(论坛.留言板.支付.用户登录等). 美工制作网页效果图(首页.列表页.内容页). 制作人员切图排版,排成网页形式. 后台程序开始写程序. 前台与后台结合. HTML注释 ...