用python解析word文件(二):table
(二)表格篇(table)(本篇)
选你所需即可。下面开始正文。
docx.tables
cell.text

for t in docx.tables:
# todo
_table_list = []
for i, row in enumerate(table.rows): # 读每行
row_content = []
for cell in row.cells: # 读一行中的所有单元格
c = cell.text
if c not in row_content:
row_content.append(c)
# print(row_content)
_table_list.append(row_content)
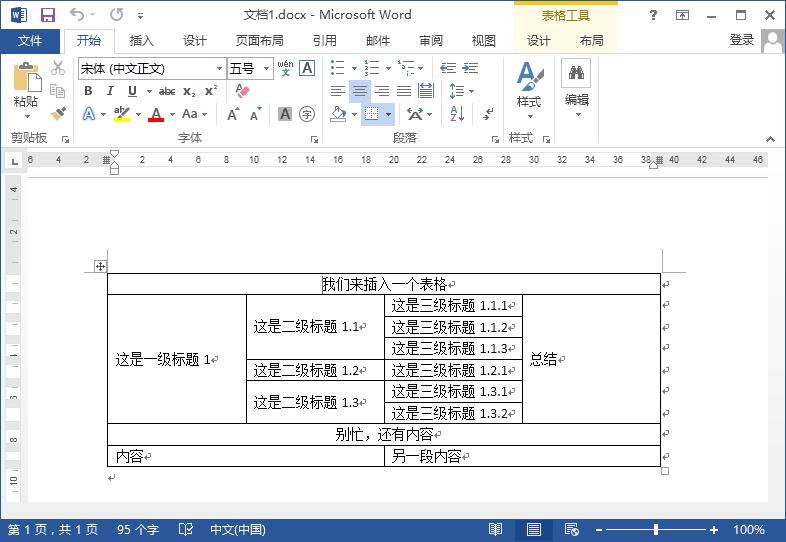
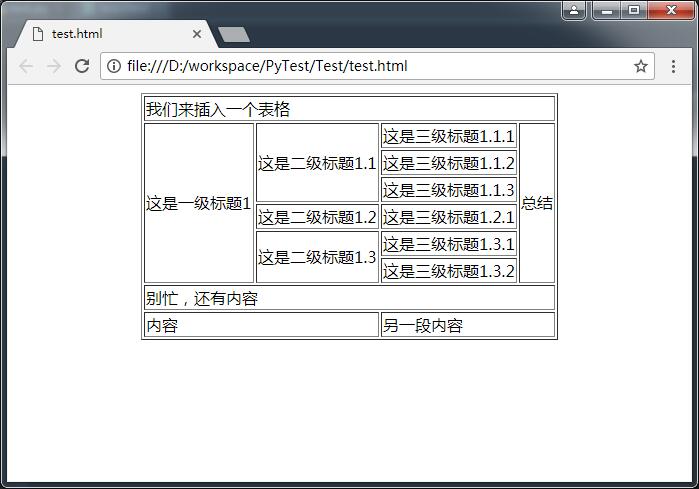
['我们来插入一个表格']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结']
['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结']
['别忙,还有内容']
['内容', '另一段内容']
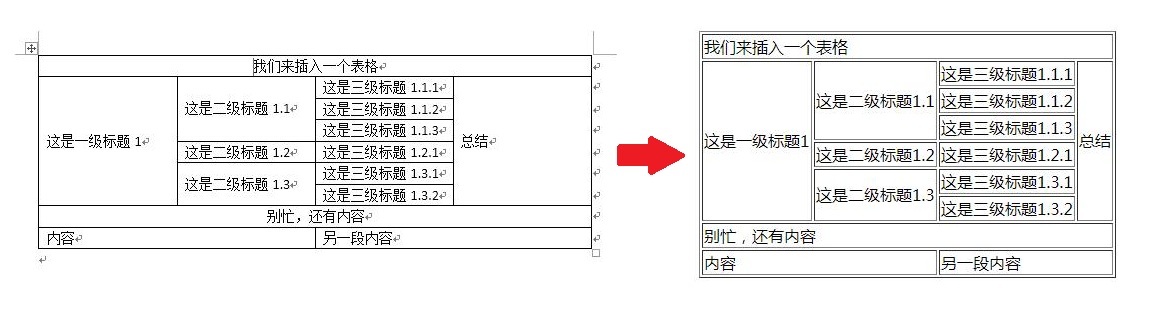
def _fill_blank(table):
cols = max([len(i) for i in table]) new_table = []
for i, row in enumerate(table):
new_row = []
[new_row.extend([i] * int(cols / len(row))) for i in row]
print(new_row)
new_table.append(new_row) return new_table
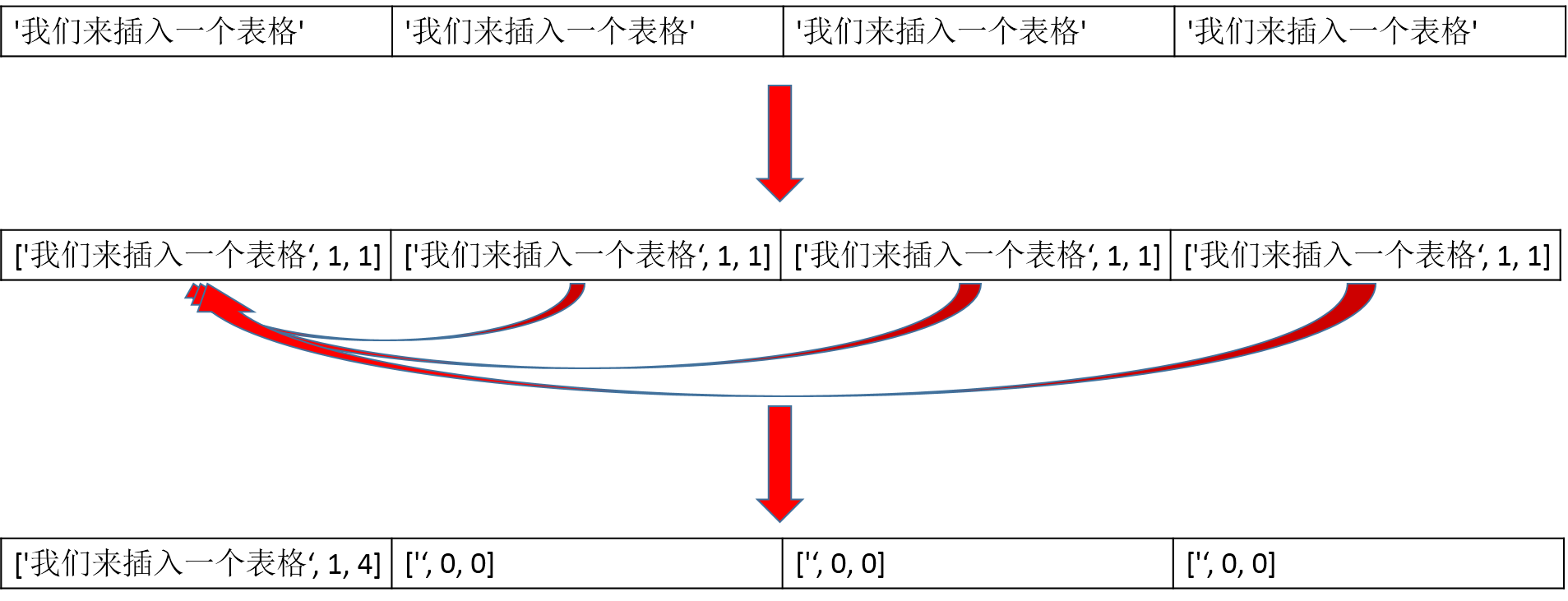
['我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格']
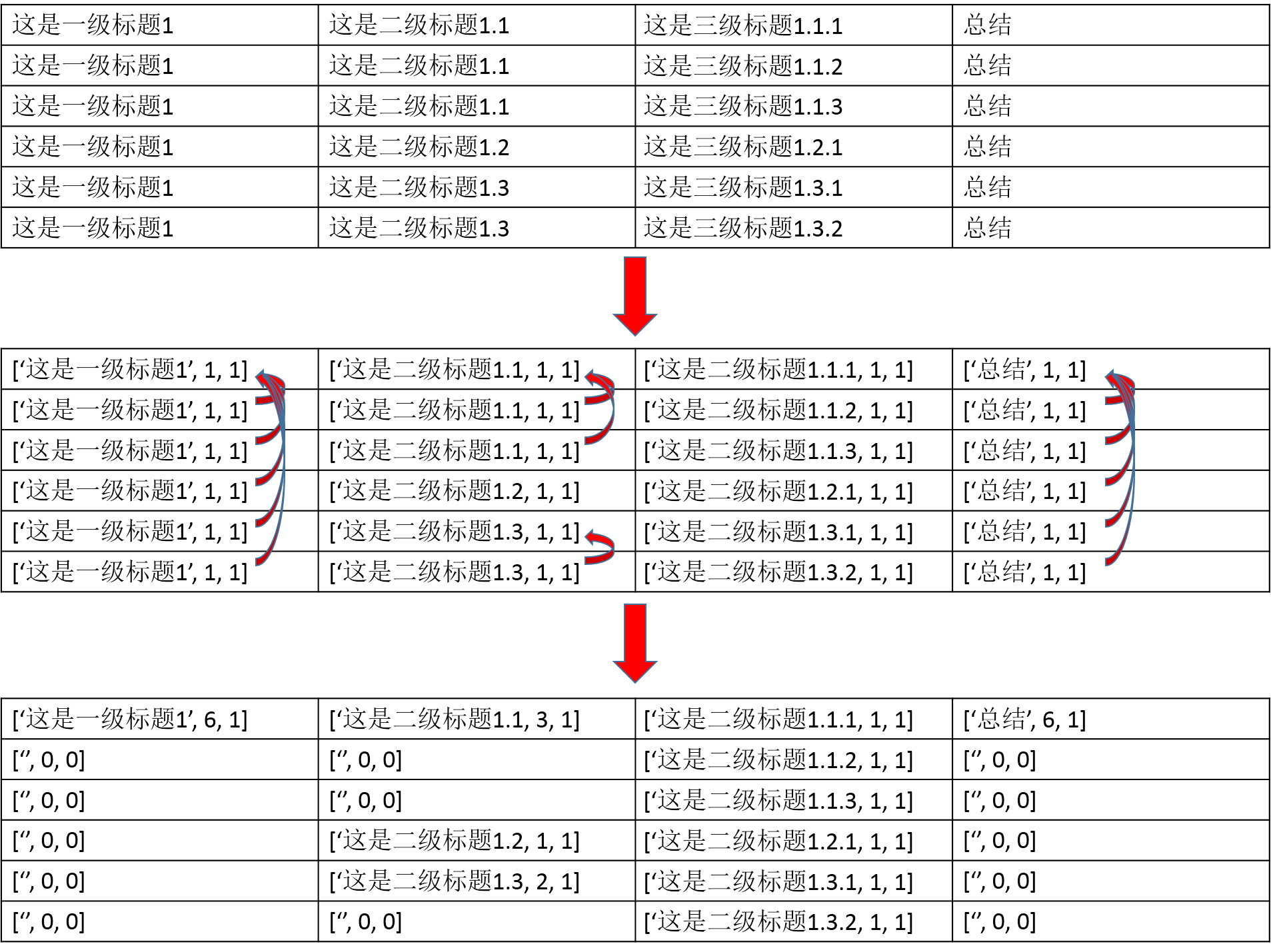
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结']
['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结']
['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结']
['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结']
['别忙,还有内容', '别忙,还有内容', '别忙,还有内容', '别忙,还有内容']
['内容', '内容', '另一段内容', '另一段内容']
<table border="1" align="center">
<tr align="center"><td colspan="4">Row One</td></tr>
<tr align="center"><td>Row Two</td><td>Row Two</td><td>Row Two</td><td>Row Two</td></tr>
</table>

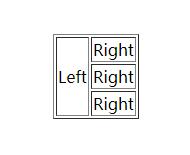
<table border="1" align="center">
<tr><td rowspan="3">Left</td><td>Right</td></tr>
<tr><td>Right</td></tr>
<tr><td>Right</td></tr>
</table>
def _table_matrix():
if not table:
return "" # 处理同一行的各列
temp_matrix = []
for row in table:
if not row:
continue col_last = [row[0], 1, 1]
line = [col_last]
for i, j in enumerate(row):
if i == 0:
continue if j == col_last[0]:
col_last[2] += 1
line.append(["", 0, 0])
else:
col_last = [j, 1, 1]
line.append(col_last) temp_matrix.append(line) # 处理不同行
matrix = [temp_matrix[0]]
last_row = []
for i, row in enumerate(temp_matrix):
if i == 0:
last_row.extend(row)
continue new_row = []
for p, r in enumerate(row):
if p >= len(last_row):
break last_pos = last_row[p] if r[0] == last_pos[0] and last_pos[0] != "":
last_row[p][1] += 1
new_row.append(["", 0, 0])
else:
last_row[p] = row[p]
new_row.append(r) matrix.append(new_row) return matrix
def table2html(t):
table = _fill_blank(t)
matrix = _table_matrix(table) html = ""
for row in matrix:
tr = "<tr>"
for col in row:
if col[1] == 0 and col[2] == 0:
continue td = ["<td"]
if col[1] > 1:
td.append(" rowspan=\"%s\"" % col[1])
if col[2] > 1:
td.append(" colspan=\"%s\"" % col[2])
td.append(">%s</td>" % col[0]) tr += "".join(td)
tr += "</tr>"
html += tr return html
{{ table|safe }}
用python解析word文件(二):table的更多相关文章
- 用python解析word文件(一):paragraph
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph)(本篇) (二)表格篇(table) (三)样式篇(style) 选你所需即可.下面开始正文. 最近公司的项目,需要在页面上显示w ...
- 用python解析word文件(三):style
太长了,我决定还是拆开三篇写. (一)段落篇(paragraph) (二)表格篇(table) (三)样式篇(style)(本篇) 选你所需即可.下面开始正文. 在前两篇中,我们已经解析出了par ...
- 用python解析word文件(段落篇(paragraph) 表格篇(table) 样式篇(style))
首先需要安装相应的支持库: 直接在命令行执行pip install python-docx 示例代码如下: import docxfrom docx import Document #导入库 path ...
- 用python读取word文件里的表格信息【华为云技术分享】
在企查查查询企业信息的时候,得到了一些word文件,里面有些控股企业的数据放在表格里,需要我们将其提取出来. word文件看起来很复杂,不方便进行结构化.实际上,一个word文档中大概有这么几种类型的 ...
- Python解析excel文件并存入sqlite数据库
最近由于工作上的需求 需要使用Python解析excel文件并存入sqlite 就此做个总结 功能:1.数据库设计 建立数据库2.Python解析excel文件3.Python读取文件名并解析4.将解 ...
- C#仪器数据文件解析-Word文件(doc、docx)
不少仪器数据报告输出为Word格式文件,同Excel文件,Word文件doc和docx的存储格式是不同的,相应的解析Word文件的方式也类似,主要有以下方式: 1.通过MS Word应用程序的DCOM ...
- Python处理word文件
python对word文件进行读写和复制 import win32conimport win32com.clientimport os #读取word文件def readWoldFile(path): ...
- Python解析Wav文件并绘制波形的方法
资源下载 #本文PDF版下载 Python解析Wav文件并绘制波形的方法 #本文代码下载 Wav波形绘图代码 #本文实例音频文件night.wav下载 音频文件下载 (石进-夜的钢琴曲) 前言 在现在 ...
- 用Python将word文件转换成html(转)
用Python将word文件转换成html 序 最近公司一个客户大大购买了一堆医疗健康方面的科普文章,希望能放到我们正在开发的健康档案管理软件上.客户大大说,要智能推送!要掌握节奏!要深度学习!要 ...
随机推荐
- ie,你还能再浪一点不
一个div,设置了高度,并且溢出滚动 各位观众,当点击滚动条的时候,event.target应该是什么呢? 火狐,chrome都认为是点击了div,这个也很好理解,他是div的滚动条,自然应该算div ...
- gdb中run出现的Missing separate debuginfos, use: debuginfo-install XXX
问题: Missing separate debuginfos, use: debuginfo-install glib 解决方法: 1.将/etc/yum.repo.d/CentOS-Debugin ...
- Jsp&Servlet入门级项目全程实录第8讲
惯例广告一发,对于初学真,真的很有用www.java1234.com,去试试吧! 1.添加dao public int studentAdd(Connection con,Student studen ...
- 并发编程之ThreadLocal源码分析
当访问共享的可变数据时,通常需要使用同步.一种避免同步的方式就是不共享数据,仅在单线程内部访问数据,就不需要同步.该技术称之为线程封闭. 当数据封装到线程内部,即使该数据不是线程安全的,也会实现自动线 ...
- 撩课-Web大前端每天5道面试题-Day19
1.实现一个函数clone,可以对JavaScript中的5种主要的数据类型(包括Number.String.Object.Array.Boolean)进行值复制 考察点1:对于基本数据类型和引用数据 ...
- java实现返回一个字符串所有排列
今天偶然看到了一个笔试题,觉得挺有意思,分享一下解题思路 public void permute(String string); public void permute(char[] chars , ...
- 14、通过jpa往数据库插数据
这是接着上一篇写的,在上一篇的基础上添加 Controller @RestController public class HelloController { @Resource private Hel ...
- Go 中包导入声明
Go中的程序由软件包组成.通常,软件包依赖于其他软件包,或者内置于标准库或第三方的软件包.包需要先导入才能使用其导出的标识符.本文将翻译一篇国外的文章,用于介绍包导入的原理以及几种常用的导入方式. & ...
- drupal smtp could not connect to smtp
情况说明: 使用了SMTP Authentication Support 模块. 配置都没问题,是从另一台服务器迁过来的网站和数据库. 原因是客户的smtp服务器限制了我们新服务器的IP. 验证方式t ...
- javaSE——字节流
IO流:InputStream/OutputStream 字节流: 文件输出流 :内存 ——>文件 文件输入流 :内存<——文件 应用 文件输入/出 ...