【Coursera】基于朴素贝叶斯的中文多分类器
一、算法说明
- 为了便于计算类条件概率\(P(x|c)\),朴素贝叶斯算法作了一个关键的假设:对已知类别,假设所有属性相互独立。
- 当使用训练完的特征向量对新样本进行测试时,由于概率是多个很小的相乘所得,可能会出现下溢出,故对乘积取自然对数解决这个问题。
- 在大多数朴素贝叶斯分类器中计算特征向量时采用的都是词集模型,即将每个词的出现与否作为一个特征。而在该分类器中采用的是词袋模型,即文档中每个词汇的出现次数作为一个特征。
- 当新样本中有某个词在原训练词中没有出现过,会使得概率为0,故使用拉普拉斯平滑处理技术解决这一问题。对应公式如下:
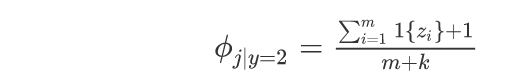
二、数据源
在该模型中,所用到的训练数据和测试数据均来自于搜狗分类语料库,并选择了体育类、财经类和教育类这三种新闻的各40个样本,以作为该多分类器的输入数据。
三、中文分词
为了对文本完成分词,对于英文文本而言,只需要简单得利用str.split(" "),用空格对整个英文文本进行切割即可。而对于中文文本而言就相对复杂了点,因为在中文文本中,往往包含了中文、英文、数字、标点符号等多种字符,此外中文中常常是多个词组连接起来组成一个句子,所以也无法类似英文那样简单利用某个符号进行分割。为了完成中文文本的分词,使用了如下的文本过滤算法:
stopWords = open("stop_words.txt", encoding='UTF-8').read().split("\n")
def textParse(inputData):
import re
global stopWords
inputData = "".join(re.findall(u'[\u4e00-\u9fa5]+', inputData))
wordList = "/".join(jieba.cut(inputData))
listOfTokens = wordList.split("/")
return [tok for tok in listOfTokens if (tok not in stopWords and len(tok) >= 2)]
- 利用正则表达式
u'[\u4e00-\u9fa5]+'过滤掉输入数据中的所有非中文字符; - 在Python下,有个中文分词组件叫做jieba,可以很好得完成对中文文本的分词。在这里便是利用jieba中的cut函数
"/".join(jieba.cut(inputData))完成对中文的分词,并且以“/”作为分隔符。 - 在中文文本中,存在在大量的停用词,这些停用词对于表示一个类别的特征没有多少贡献,因此必需过滤掉输入数据中的停用词。这里所用到的stop_words.txt ,包含了1598个停用词,利用
tok not in stopWords过滤掉输入数据中的停用词。 - 在利用jieba完成分词后,往往会存在大量长度为1的词(不在停用词表里),这些词对特征表示同样贡献不大,利用
len(tok) >= 2将其过滤掉。
通过以上过程,便完成了中文文本的分词。分词结果如下:

四、分类结果
为了对分类器的泛化误差进行评估,遂使用留存交叉验证法,即从输入的40 * 3共120个样本中,随机选中20个样本作为测试数据,其他100个样本作为训练数据,以此来测定泛化误差。
经过10次测试,得到分类器的泛化误差为:(0.1 + 0.0 + 0.1 + 0.1 = 0.0 + 0.05 + 0.1 + 0.15 + 0.1 + 0.25)/ 10 = 0.095,可见该中分多分类器在新样本上的表现还是很好的。其中部分分类结果如下所示:



【Coursera】基于朴素贝叶斯的中文多分类器的更多相关文章
- 详解基于朴素贝叶斯的情感分析及 Python 实现
相对于「 基于词典的分析 」,「 基于机器学习 」的就不需要大量标注的词典,但是需要大量标记的数据,比如: 还是下面这句话,如果它的标签是: 服务质量 - 中 (共有三个级别,好.中.差) ╮(╯-╰ ...
- Java实现基于朴素贝叶斯的情感词分析
朴素贝叶斯(Naive Bayesian)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它是基于概率论的一种有监督学习方法,被广泛应用于自然语言处理,并在机器学习领域中占据了非常重要的地位.在之前 ...
- spark MLlib实现的基于朴素贝叶斯(NaiveBayes)的中文文本自动分类
1.自动文本分类是对大量的非结构化的文字信息(文本文档.网页等)按照给定的分类体系,根据文字信息内容分到指定的类别中去,是一种有指导的学习过程. 分类过程采用基于统计的方法和向量空间模型可以对常见的文 ...
- R 基于朴素贝叶斯模型实现手机垃圾短信过滤
# 读取数数据, 查看数据结构 df_raw <- read.csv("sms_spam.csv", stringsAsFactors=F) str(df_raw) leng ...
- 【sklearn朴素贝叶斯算法】高斯分布/多项式/伯努利贝叶斯算法以及代码实例
朴素贝叶斯 朴素贝叶斯方法是一组基于贝叶斯定理的监督学习算法,其"朴素"假设是:给定类别变量的每一对特征之间条件独立.贝叶斯定理描述了如下关系: 给定类别变量\(y\)以及属性值向 ...
- 机器学习Matlab打击垃圾邮件的分类————朴素贝叶斯模型
该系列来自于我<人工智能>课程回顾总结,以及实验的一部分进行了总结学习机 垃圾分类是有监督的学习分类最经典的案例,本文首先回顾了概率论的基本知识.则以及朴素贝叶斯模型的思想.最后给出了垃圾 ...
- NLP系列(4)_朴素贝叶斯实战与进阶
作者: 寒小阳 && 龙心尘 时间:2016年2月. 出处:http://blog.csdn.net/han_xiaoyang/article/details/50629608 htt ...
- NLP系列(4)_朴素贝叶斯实战与进阶(转)
http://blog.csdn.net/han_xiaoyang/article/details/50629608 作者: 寒小阳 && 龙心尘 时间:2016年2月. 出处:htt ...
- 数据算法 --hadoop/spark数据处理技巧 --(13.朴素贝叶斯 14.情感分析)
十三.朴素贝叶斯 朴素贝叶斯是一个线性分类器.处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字.符号.电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以.在某些情况 ...
随机推荐
- devise的使用
~ 在gemfile中加入 gem 'devise' ~ 终端输入 $ bundle install $ rails generate devise:install ~ 确保登录之后能正常跳转 在co ...
- Web安全0002 - SQL注入 - 注入流程
注:本文是学习网易Web安全进阶课的笔记,特此声明. 一.信息搜集 — 数据库类型 - 报错信息.特有语句— 数据库版本(@@version,$version)— 数据库用户— 判断数据库权限 二.数 ...
- Scala基础语言api入门学习
Scala的变量定义 变量定义 声明一个val变量类似与java的 public static final String 一致,一旦初始化不能改变,和java的泛型类似,Scala会帮我们进行类型推断 ...
- 数据结构与算法之链表(LinkedList)——简单实现
这一定要mark一下.虽然链表的实现很简单,且本次只实现了一个方法.但关键的是例子:单向链表的反转.这是当年我去H公司面试时,面试官出的的题目,而当时竟然卡壳了.现在回想起来,还是自己的基本功不扎实, ...
- C++_编写动态链接库
原文:http://blog.csdn.net/a7055117a/article/details/47733247 动态链接库简介 动态链接库(Dynamic Link Library 或者 Dyn ...
- sqlplus 中 各列对齐设定
设置列标题的对齐方式 JUSTFIFY {L[EFT]|C[ENTER]|R[IGHT]} SQL> col ename justify center SQL> /
- Laravel 跨框架队列交互
公司大部分项目是laravel框架,但有些是yii框架,这两个框架之间有消息需要通信,比如在yii框架发布消息,laravel框架中的队列去处理,用redis作为消息连接纽带 laravel 队列原理 ...
- 解决Linux下编译.sh文件报错 unexpected operator Syntax error: word unexpected
执行一个脚本 发现报语法错误,但是在其他机器上运行都没有问题 唯一的区别就是 一个是centos机器 报错的是ubuntu 网上搜索了一下 因为Ubuntu默认的sh是连接到dash的,又因为da ...
- 人在囧途——Java程序猿学习Python
引言 LZ之前其实一直对python都很好奇,只是苦于平时没有时间去了解它,因此趁着51假期这个机会,便迫不及待的开始了自己的探索.作为一个标准的Java程序猿,在了解python的过程当中,LZ遇到 ...
- 利用自定义 ORM 下使用 flask-login 做登录校验使用笔记
1. 安装: pip install flask_login 2. 使用: 注册应用 import os from flask_login import LoginManager, current_u ...