分析VoltDB内存数据库
转自https://blog.csdn.net/olidrop/article/details/7065384
https://blog.csdn.net/ransom0512/article/details/50440316
VoltDB的数据主要存储在内存中,Shared Nothing的集群结构,单机是单线程处理事务,不是用锁而是基于Optimistic的方法处理事务并发,所有的事务必须以存储过程形式先提交到VoltDB系统。
适用场景
VoltDB适合OLTP系统,单个事务较小,但是事务总量非常之多的应用。比如金融,零售,WEB2.0等传统OLTP应用。不适合进行范围查询或者频繁多表Join这样的场景。
设计思路
VoltDB通过内存存储、数据分区和无锁计算来实现高性能运算。
- 内存存储
VoltDB所有数据都保存在内存中(可靠性中会有数据刷到磁盘,见VoltDB ACID中可靠性设计), 内存存取速度已经比磁盘远远高出几个数量级了,这就是VoltDB高性能的重要原因。 - 数据分区
VoltDB对每个节点的内存进行管理,在每个节点上创建多个分区,所有分区表中的数据,都分散在各个分区中,然后在读写的时候,就可以实现多个分区并发进行,所以拓展性是线性提升的。
这种分区机制也会带来问题,当集群需要扩容的时候,需要停止整个集群,然后再进行扩容;当集群启动的时候,VoltDB会重新调整数据分布,在所有数据分布调整完毕之后,才开始提供服务。 - 无锁计算
VoltDB数据分区存放,在执行SQL语句的时候,客户端就会根据条件自动判断数据在哪个分区中,然后下发至该分区执行。如果查询条件中不包含分区列,那么就会由客户端进行统一控制,在每个分区上都进行查询之后,再统一返回结果,这种场景会极大影响性能。
VoltDB的程序都是以存储过程的方式执行的,支持使用java或者其他语言定义存储过程。每个分区的存储过程执行都是单线程线性执行的,这就保证了单分区的无锁设计。当一个语句涉及到多个区分协调读写的时候,VoltDB会在协调,统一锁定分区队列,等该语句执行完毕之后,才会释放锁。所以多分区操作才会如此消耗性能。
VoltDB在分区管理上,建议每个物理CPU创建一个分区,这样单个分区内的数据都在CPU的一级缓存和二级缓存上,避免在多个CPU之间的数据操作,最大限度的提升CPU利用率,避免并发锁。所以理论上,VoltDB的CPU使用率是可以达到100%的。
高可用性
VoltDB使用K-safety、双活、snapshot、WAL机制组合机制保证数据的高可用性。
- K-Safety
其实就是N+1的副本机制,VoltDB在写数据操作的时候,会在每个副本中执行该语句,这样就可以保证数据被正确插入每个副本。这N+1的副本都可以同时提供访问,同时允许最多N个副本丢失(分区故障), 当N+1个副本都不可用的时候,VoltDB就会停止服务进行修复。 - 双活
多集群双活机制,两个集群都可以提供服务,数据在多分区之间异步复制,当一个集群挂了的时候,另外一个集群提供服务,当异常集群恢复之后,会自动进行数据同步,只有数据一致的时候,才会提供服务。但是这种机制其实还是有问题,有可能导致数据不一致,因此同步复制机制还是需要的。 - Snapshot
由于数据在内存中存放,当节点掉电的时候,数据就会丢失,所以VoltDB会定期对每个分区数据做快照,以备节点掉电时候进行恢复。 - WAL
Write ahead log,VoltDB会在对数据进行插入操作的时候,预先进行写日志操作,这个和传统数据库一样,但是由于是顺序写入,所以性能还是比传统数据库要好很多。
Snapshot机制和WAL机制会导致造成性能5%左右的下降,不过这个也是为了完整ACID不得不做出的牺牲。
事务提交
既需要支持复杂的事务操作,又需要快速的执行过程,VoltDB采取了一个比较极端的事务提交方式。虽然VoltDB支持部分SQL语句接口,但是不允许用户使用传统的"BEGIN TRANSACTION"和"END TRANSACTION"的语法模式,而是完全基于存储过程。用户通过写存储过程完成应用程序的逻辑,作为一个先置条件将存储过程提交到VoltDB。运行时,用户程序调用存储过程完成事务操作,所有事务的运行逻辑是由VoltDB在服务器进程中完成的。这种方式保证了事务不会被人为打断,并且服务器可以预先判断各个事务的逻辑,也为事务并发处理挖掘信息。
分区表和复制表
- 分区表
创建表之后,需要手工执行分区语句为表进行分区。
PARTITION TABLE towns ON COLUMN state_num;
该语句表明使用state_numn字段为towns表进行分区。之后插入数据的时候,VoltDB会自动将数据插入指定分区。
目前VoltDB只支持Hash分区,后续可能会考虑支持范围分区。
VoltDB的分区是一个逻辑上的概念,一个分区中可能包含多个表的多个数据分区的数据。VoltDB建议按照物理CPU的数量进行分区,每个分区独立使用一个CPU,这样可以避免CPU之间的锁竞争。 - 复制表
一个表,没有指定分区,那么就是一个复制表。这个表的特征就是会在每个分区保存一份全量副本,这样在和其他表在做Join查询的时候,就不会跨节点查询,大大加快Join速度。
复制表适合于数据比较稳定,只有少量更新的场景。如果数据要更新,就意味着要在每个分区上都执行一次插入操作,这种操作会显著降低系统并发度。
数据分布
VoltDB使用Shared Nothing结构,整个数据库的数据分散到集群的多台机器上。VoltDB的数据分布策略是基于哈希的,存储在VoltDB中的每一张表,对数据的主键哈希取模后的结果对应于数据存储的节点。相比较于BigTable基于主键的连续范围分段的方法,哈希方法的好处是数据分散的均匀,没有动态数据调整的烦恼。但也有很多缺点,采用这种方法后,集群的规模是事先确定好的,新增机器需要停止服务后重新分布数据。另外,数据哈希被分散后,数据的连续性被打乱了,在这个数据结构上做范围查询需要动用服务这张表的所有机器,这个后面会祥说。
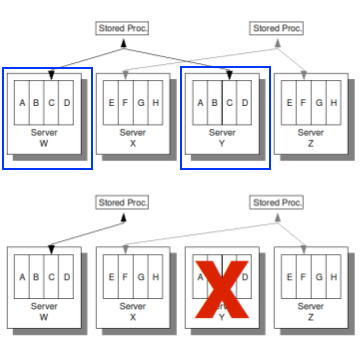
上面这张图描述了数据的分布方式,VoltDB集群的每台机器都会服务多张表。从图里还能看到VoltDB的数据复制是基于机器单位的,蓝色框圈住的两台机器内的数据是完全同构的。
VoltDB的哈希分布数据的方法是系统设计的简化,这种简化让VoltDB工程实现难度降低,可以快速的商用。天下没有免费的午餐,这个设计也是VoltDB功能缺陷,导致VoltDB无法动态扩容以及其他一些问题。
数据一致性
同一份数据的多个副本之间需要保证数据一致性,VoltDB采用所有修改操作在每一个副本上单独更新的方式。如何保证更新操作在所有副本上以相同的顺序更改而不至于产生不一致,这就要提到VoltDB的并发控制方式。
VoltDB的事务并发控制需要依赖于集群内所有机器的时间是一致的,这个可以使用NTP之类的时间同步协议,保证机器之间的时间差异远远小于一个交换机下的两台机器之间的Round Trip时间。VoltDB对于用户每一次事务的调用分配一个时间戳,并且保证这个时间戳是全局有序的,虽然时间戳是由集群中的各台机器独自分配的,但是加上机器的序号,可以保证(机器序号,时间戳)的组合值是全局有序的。一台服务器执行事务之前,需要等待Round Trip时间后,如果其他机器没有开始比自己更早的事务,那么就执行自己的事务。以这种方式保证集群内多台机器之间事务的有序。数据的多个副本的更新操作也都以相同的顺序进行修改,所有副本之间保证了一致性。
事务并发处理
为了充分发挥多核机器的性能,而又不引入多线程执行事务的复杂性,VoltDB的数据分片规模是按照集群核数来划分的。一台物理机器上可能运行多个VoltDB服务器进程,每个进程对应于一个核,服务器进程之间都是通过网络进行通信。在单个进程内,只使用单线程,所有的事务执行都是顺序进行的。
多个事务在多个服务器节点同时执行,VoltDB保证如果事务之间有冲突,那么事务的执行是完全隔离的,即达到SERIALIZABLE ISOLATION。VoltDB会事先分析好存储过程之间的关系,如果两个事务可能存在冲突,则不让这两个进程在同一个时间执行。
在VoltDB的并发处理中,每一个事务在执行之前都要等待一个Round Trip时间,显然会增加事务执行的时延。这么做是为了确保别的节点没有发起比这个事务更早的事务,保证事务执行的顺序。在实现中,VoltDB用了另外一种优化方法。例如A,B两个节点,分别要执行事务1和2,A节点开始执行事务1的时间是T1,如果A收到B发了事务2的执行需求,并且T2 > T1,那么A节点可以确认从B节点不会有更早的事务再发送过来,A节点就不必等Round Trip时间,可以直接执行事务1。当整个系统压力比较大时,这个优化方法效果尤其明显,事务的时延有效降低。
VoltDB还花了很大精力在处理事务之间的逻辑关系,尽可能对事务分门别类进行处理,以期获得更好的性能。
范围查询的处理
VoltDB取巧的采用的哈希的方法做数据分布,在面对范围查询的需求时,再次吃到苦果。哈希方法打乱了数据的连续性,对于范围查询的处理能力显著下降。VoltDB执行某张表的范围查询,需要发送这个查询到这张表的所有数据分片上。在所有分片完成同样的范围查询,再将结果汇总,才能得到全局的准确结果。所以VoltDB处理范围查询会很低效
数据持久
虽然Stonebraker在H-Store的论文里反复提到,在内存型数据库里,即使使用Group Commit写操作日志也是非常低效的,但是为了保证数据的持久性,VoltDB还是不得不采用记操作日志的办法。VoltDB使用定期做Snapshot加上记操作日志来保证数据持久性,这种方法没有什么特别的地方。
分析VoltDB内存数据库的更多相关文章
- SQL Server 内存数据库原理解析
前言 关系型数据库发展至今,细节上以做足文章,在寻求自身突破发展的过程中,内存与分布式数据库是当下最流行的主题,这与性能及扩展性在大数据时代的需求交相辉映.SQL Server作为传统的数据库也在最新 ...
- VoltDB介绍——本质:数据保存在内存,充分利用CPU,单线程去锁,底层数据结构未知
转自:http://blog.csdn.net/ransom0512/article/details/50440316 简介 VoltDB数据库是一个分布式,可扩展,shared-nothing的内存 ...
- [转帖]SSD和内存数据库技术
SSD和内存数据库技术 自己的理解还是不是很对 SSD 提升的是 随机读 并没有对顺序写有多大的提升, 因为数据库采用的是redo的模式. 理论上写入 时是顺序写 所以 写并发的提升不会很大 但是会很 ...
- 300万运算/秒 :VoltDB在电信行业基准测试上可线性扩展性能
01 总 体 概 述 VoltDB受到全球电信软件解决方案提供商的信赖,后者将其作为首选内存数据库来驱动他们部署在全球100多家运营商处的任务关键型应用.VoltDB受到青睐的原因在于其性能和功能不仅 ...
- ABP源码分析二十八:ABP.MemoryDB
这个模块简单,且无实际作用.一般实际项目中都有用数据库做持久化,用了数据库就无法用这个MemoryDB 模块了.原因在于ABP限制了UnitOfWork的类型只能有一个(前文以作介绍),一般用了数据库 ...
- Memcache,Redis,MongoDB(数据缓存系统)方案对比与分析
mongodb和memcached不是一个范畴内的东西.mongodb是文档型的非关系型数据库,其优势在于查询功能比较强大,能存储海量数据.mongodb和memcached不存在谁替换谁的问题. 和 ...
- Dynamics AX 2012 在BI分析中建立数据仓库的必要性
AX系统已有的BI分析架构 对于AX 的BI分析架构,相信大家都了解,可以看Reinhard之前的译文[译]Dynamics AX 2012 R2 BI系列-分析的架构 . AX 的BI分析架构的优势 ...
- mmzb游戏事故分析
最近一次线上更新,老项目挂了,遍地哀嚎,日活跃掉了好多,心痛... 这次维护时,SA为了缩减硬件资源,做了一次数据库迁移.给到开发手上的player db,只有一些索引数据,不带有任一玩家数据.玩家上 ...
- 161209、简要分析ZooKeeper基本原理及安装部署
一.ZooKeeper 基本概念 1.ZooKeeper 是什么? Zookeeper官网地址: http://zookeeper.apache.org/ Zookeeper官网文档地址:http:/ ...
随机推荐
- 外网访问不了Xampp(本地访问不了虚拟机的Xampp)
安装好了Xampp,在虚拟机是可以访问的, 浏览器中输入localhost 嘛 不过在本地就是访问不了,ping是能通过的 然后网上查了一些资料,并结合Xampp的提示: 特别注意:如果连上面这 ...
- 修改ASP.NET文件上传大小限制
转自:http://www.hello-code.com/blog/asp.net/201603/5954.html 要点: 1.web.config中的<httpRuntime maxRequ ...
- JAVA项目将 Oracle 转 MySQL 数据库转换(Hibernate 持久层)
项目开发时用的是Oracle数据库,但为了更好的做分布式,做集群,我们要将数据库转成 MySQL! 在数据库迁移中首先要做的事是将 Oracle 的表结构以及数据 克隆到 MySQL 数据库. 这点不 ...
- 不用bootstrap,只用CSS创建网格布局
本文译自[http://j4n.co/blog/Creating-your-own-css-grid-system],英语好的,可直接查看原网页,不需要FQ. 翻译拿不准的地方会有英文原文,方便大家理 ...
- HDU 5253 连接的管道(Kruskal算法求解MST)
题目: 老 Jack 有一片农田,以往几年都是靠天吃饭的.但是今年老天格外的不开眼,大旱.所以老 Jack 决定用管道将他的所有相邻的农田全部都串联起来,这样他就可以从远处引水过来进行灌溉了.当老 J ...
- Abp中SwaggerUI的接口文档添加上传文件参数类型
在使用Swashbuckle上传文件的时候,在接口文档中希望看到上传控件,但是C#中,没有FromBodyAttribute这个特性,所以需要在运行时,修改参数的swagger属性. 首先看下,最 ...
- sql视图中写case判断null值
下面是正解 用 is null (case when dbo.Feedback.Funnel is null then '否' when dbo.Feedback.Funnel='否' then '是 ...
- Navbar和Tabbar常用设置
1.navBar [self.navigationController.navigationBar setBackgroundImage:navBarImage forBarMetrics:UIBar ...
- iOS开发消息推送原理
转载自:http://www.cnblogs.com/cdts_change/p/3240893.html 一.消息推送原理: 在实现消息推送之前先提及几个于推送相关概念,如下图1-1: 1.Prov ...
- spring jpa和mybatis整合
spring jpa和mybatis整合 前一阵子接手了一个使用SpringBoot 和spring-data-jpa开发的项目 后期新加入一个小伙伴,表示jpa相比mybatis太难用,多表联合的查 ...