Hadoop基础-HDFS的API实现增删改查
Hadoop基础-HDFS的API实现增删改查
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客开发IDE使用的是Idea,如果没有安装Idea软件的可以去下载安装,如何安装IDE可以参考我的笔记:https://www.cnblogs.com/yinzhengjie/p/9080387.html。当然如果有小伙伴已经有自己使用习惯的IDE就不用更换了,只是配置好相应的Maven即可,我这里配置Maven是针对idea界面进行说明的。
一.将模块添加maven框架支持
1>.点击"Add Frameworks Support"
2>.添加Maven框架的支持
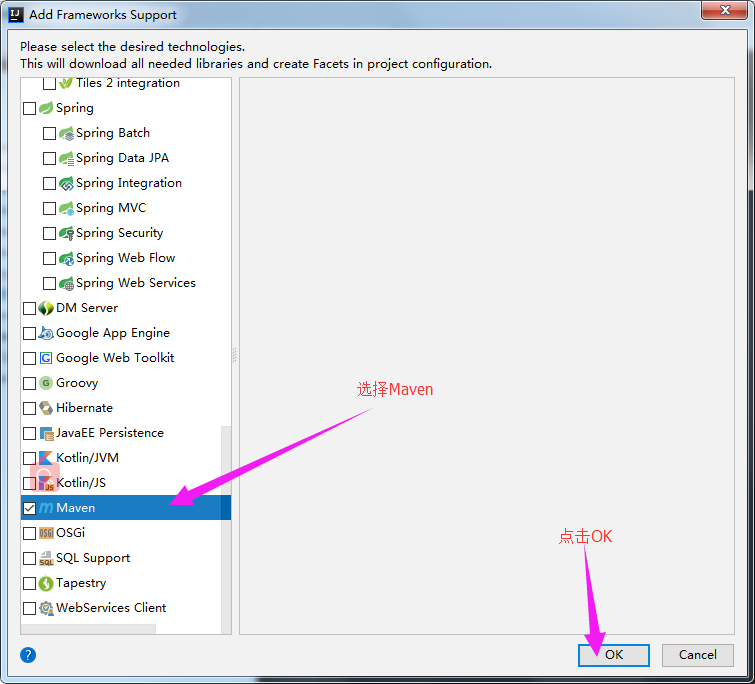
3>.在pom.xml中添加以下依赖关系
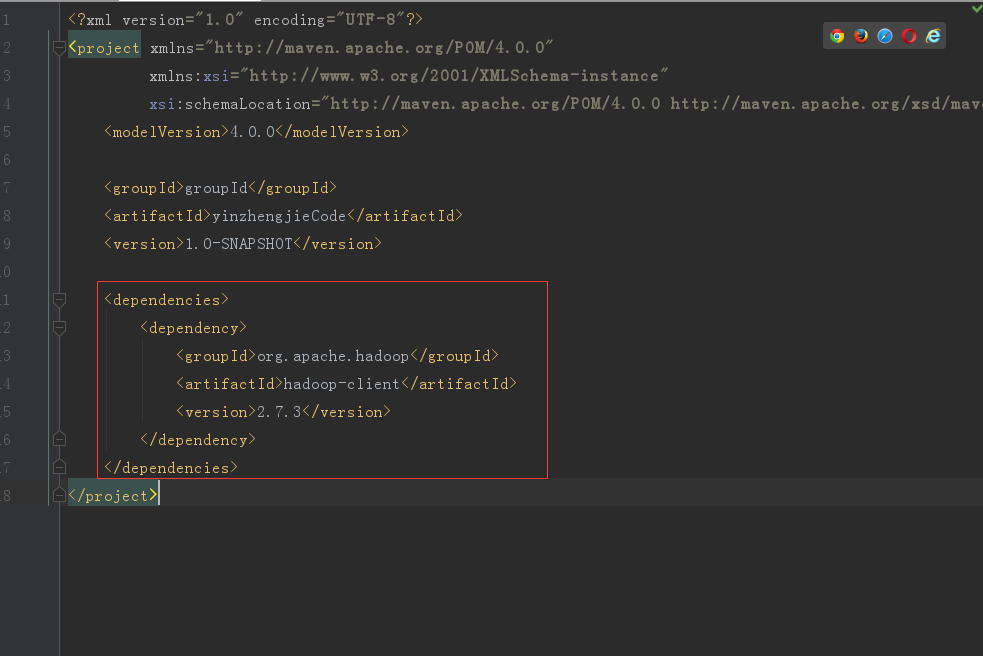
4>.启用自动导入

5>.等待下载完成
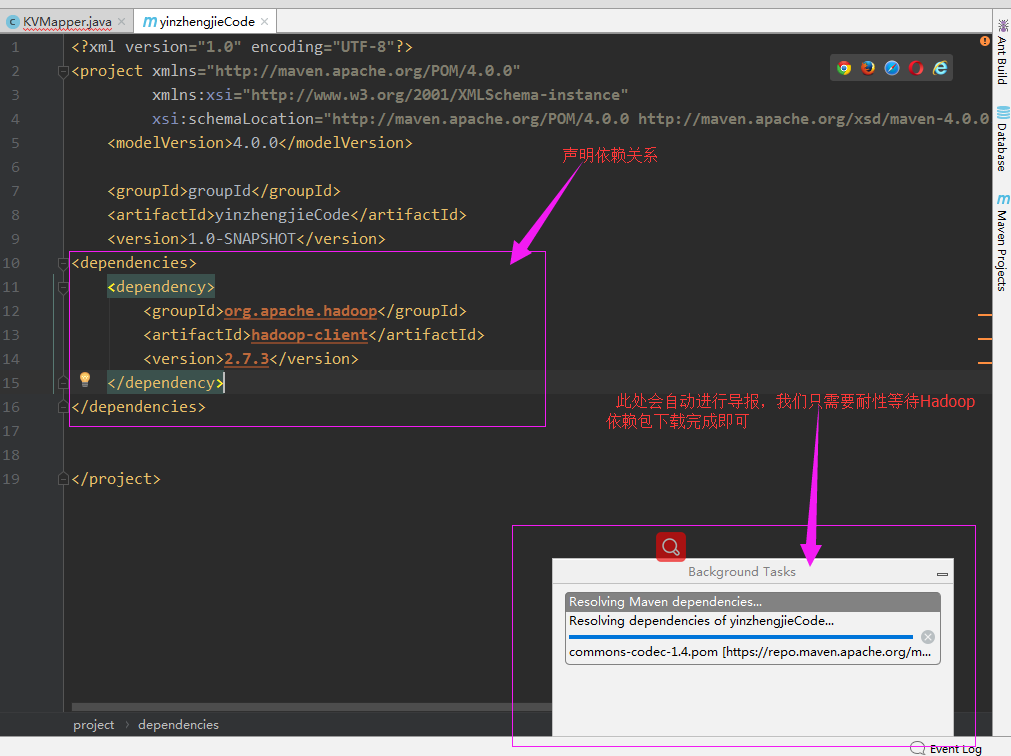
6>.手动刷新Maven项目
二.将Linux服务器端的HDFS文件到项目中的resources目录
1>.查看服务端配置文件
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s101:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/yinzhengjie/hadoop</value>
</property>
</configuration> <!-- core-site.xml配置文件的作用:
用于定义系统级别的参数,如HDFS URL、Hadoop的临时
目录以及用于rack-aware集群中的配置文件的配置等,此中的参
数定义会覆盖core-default.xml文件中的默认配置。 fs.defaultFS 参数的作用:
#声明namenode的地址,相当于声明hdfs文件系统。 hadoop.tmp.dir 参数的作用:
#声明hadoop工作目录的地址。 -->
[yinzhengjie@s101 ~]$ sz /soft/hadoop/etc/hadoop/core-site.xml
rz
zmodem trl+C ȡ % bytes bytes/s :: Errors [yinzhengjie@s101 ~]$
2>.将下载的文件拷贝到项目中resources目录下
3>.查看下载的core-site.xml 文件内容
三.HDFS的API实现增删改查
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException; public class HdfsDemo {
public static void main(String[] args) throws IOException {
insert();
update();
read();
delete();
} //删除文件
private static void delete() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie");
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称
Path path = new Path("/yinzhengjie.sql");
//通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录
boolean res = fs.delete(path, true);
if (res == true){
System.out.println("====================");
System.out.println(path + "文件删除成功!");
System.out.println("====================");
}
//释放资源
fs.close();
} //将数据追加到文件内容中
private static void update() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称
Path path = new Path("/yinzhengjie.sql");
//通过fs的append方法实现对文件的追加操作
FSDataOutputStream fos = fs.append(path);
//通过fos写入数据
fos.write("\nyinzhengjie".getBytes());
//释放资源
fos.close();
fs.close(); } //将数据写入HDFS文件系统
private static void insert() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称
Path path = new Path("/yinzhengjie.sql");
//通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖!
FSDataOutputStream fos = fs.create(path,true);
//通过fos写入数据
fos.writeUTF("尹正杰");
//释放资源
fos.close();
fs.close();
} //在HDFS文件系统中读取数据
private static void read() throws IOException {
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指NameNode中的HDFS分布式系统中的路径映射(注意,我这里写的是主机名,你可以写IP,如果是测试环境的话需要在hosts文件中添加主机名映射哟!)
Path path = new Path("hdfs://s101:8020/yinzhengjie.sql");
//通过fs读取数据
FSDataInputStream fis = fs.open(path);
int len = 0;
byte[] buf = new byte[4096];
while ((len = fis.read(buf)) != -1){
System.out.println(new String(buf, 0, len));
}
}
} /*
以上代码执行结果如下:
尹正杰
yinzhengjie
====================
/yinzhengjie.sql文件删除成功!
====================
*/
四.HDFS的API实现文件拷贝(不需要我们自己实现数据流的拷贝,而是使用Hadoop自带的IOUtils类实现)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; import java.io.FileOutputStream;
import java.io.IOException; public class HdfsDemo1 {
public static void main(String[] args) throws IOException {
get();
} //定义方法下载文件到本地
private static void get() throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie");
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/xrsync.sh”,但由于core-site.xml配置
// 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写相对路径
Path path = new Path("/xrsync.sh");
//通过fs的open方法获取一个对象输入流
FSDataInputStream fis = fs.open(path);
//创建一个对象输出流
FileOutputStream fos = new FileOutputStream("yinzhengjie.sql");
//通过Hadoop提供的IOUtiles工具类的copyBytes方法拷贝数据,第一个参数是需要传一个输入流,第二个参数需要传入一个输出流,第三个指定传输数据的缓冲区大小。
IOUtils.copyBytes(fis,fos,4096);
System.out.println("文件拷贝成功!");
//别忘了释放资源哟
fis.close();
fos.close();
fs.close();
}
} /*
以上代码执行结果如下:
文件拷贝成功!
*/
五.自定义块大小写入文件
配置Hadoop的最小blocksize,必须是512的倍数,有可能你会问为什么要设置大小是512的倍数呢?因为hdfs在写入的过程中会进行校验,每512字节进行依次校验,因此需要设置是512的倍数。编辑“hdfs-site.xml”配置文件。
1>.服务器端hdfs的配置文件,修改默认的块大小,默认块大小是1048576字节,我们手动改为1024字节,配合过程如下:(别忘记重启服务,修改配置文件一般都是需要重启服务的哟)
[yinzhengjie@s101 ~]$ more `which xrsync.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数";
exit
fi #获取文件路径
file=$@ #获取子路径
filename=`basename $file` #获取父路径
dirpath=`dirname $file` #获取完整路径
cd $dirpath
fullpath=`pwd -P` #同步文件到DataNode
for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo =========== s$i %file ===========
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
rsync -lr $filename `whoami`@s$i:$fullpath
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value></value>
</property>
</configuration> <!--
hdfs-site.xml 配置文件的作用:
#HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限
等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用:
#为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据
块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用
保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个
软件级备份。 dfs.namenode.fs-limits.min-block-size 参数的作用:
#该参数是用指定hdfs最小块存储设置 -->
[yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop/etc/full/hdfs-site.xml
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$
2>.客户端编写API代码如下
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.io.IOException; public class HdfsDemo4 {
public static void main(String[] args) throws IOException {
String path = "F:/yinzhengjie.sql";
customWrite(path);
} //定制化写入副本数和块大小(blocksize)
private static void customWrite(String path) throws IOException {
//由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入
// 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定!
System.setProperty("HADOOP_USER_NAME","yinzhengjie");
//实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。)
Configuration conf = new Configuration();
//代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。
FileSystem fs = FileSystem.get(conf);
//这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写相对路径
Path hdfsPath = new Path("/yinzhengjie.sql");
//通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖!第三个参数是指定缓冲区大小,第四个参数是指定存储的副本数(规定数据类型必须为short类型),第五个参数是指定块大小。
FSDataOutputStream fos = fs.create(hdfsPath,true,,(short) ,);
//创建出本地的文件输入流,也就是我们真正想要上传的文件。
FileInputStream fis = new FileInputStream(path);
//拷贝文件
IOUtils.copyBytes(fis,fos,);
//释放资源
fos.close();
fis.close();
}
}
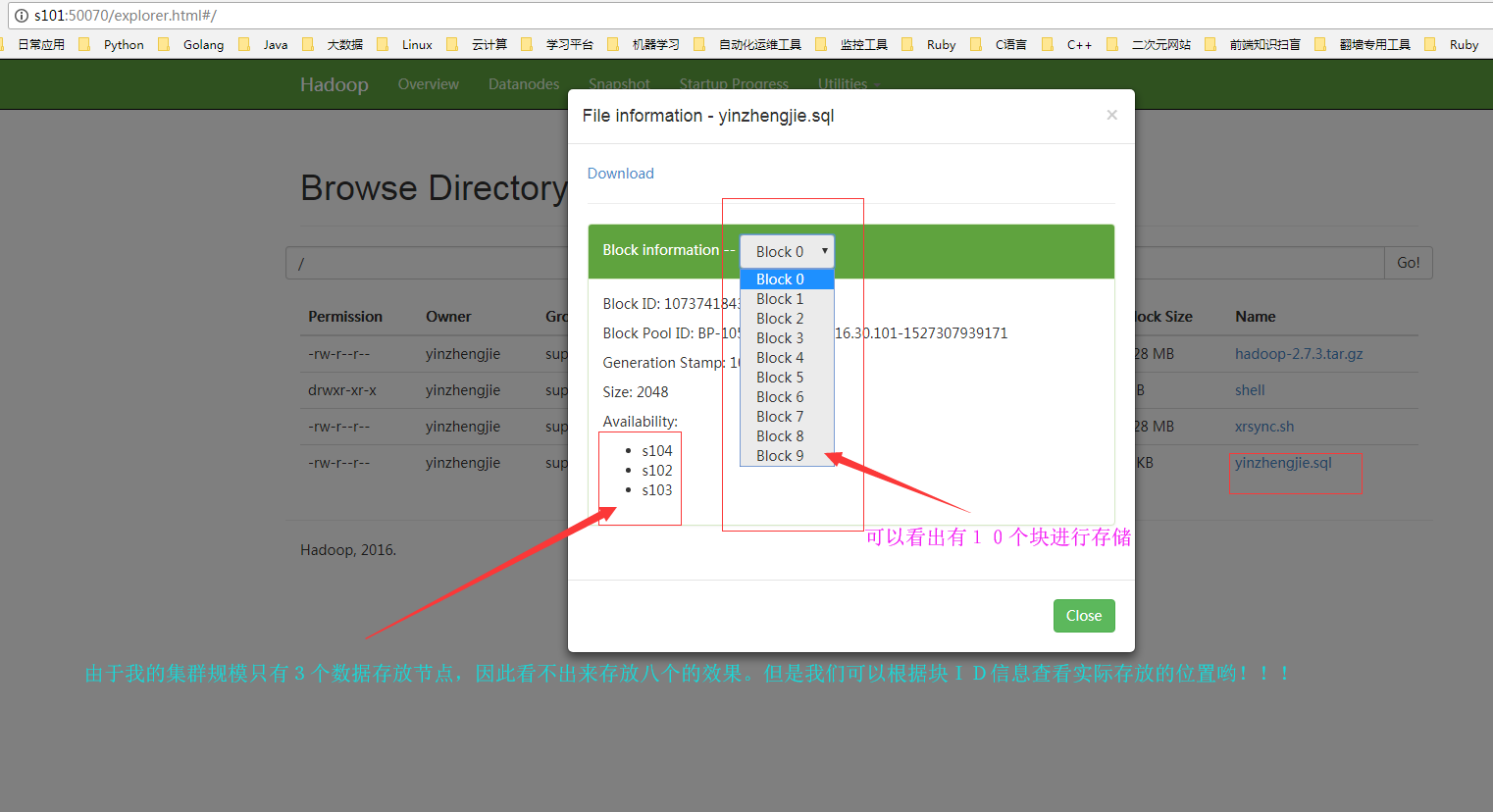
3>.客户端通过浏览器访问NameNode的WEBUI
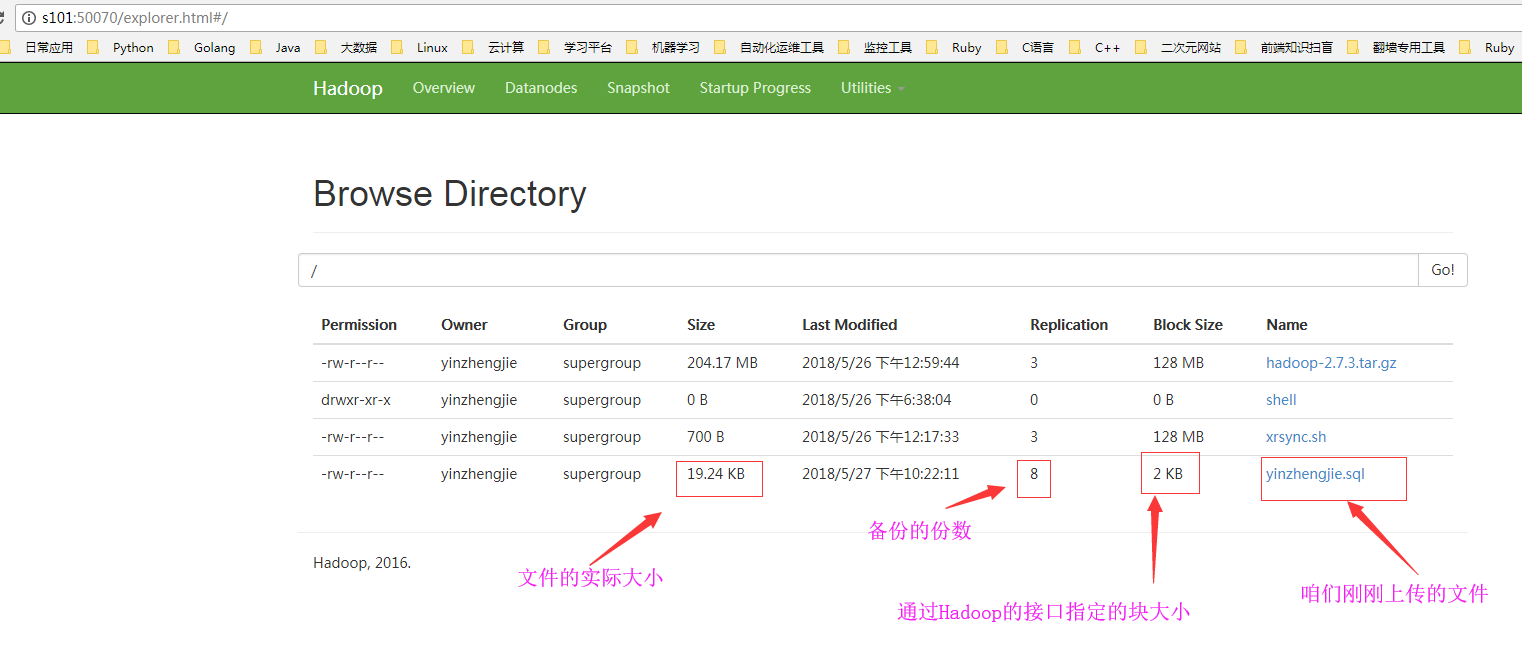
看完上面的信息发现和API设置的几乎一致呢,那必定得一致啊,由于块大小是2KB,而上传的文件是19.25kb,最少得10个块进行存储,我们也可以通过WEBUI来查看。
Hadoop基础-HDFS的API实现增删改查的更多相关文章
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- 05_Elasticsearch 单模式下API的增删改查操作
05_Elasticsearch 单模式下API的增删改查操作 安装marvel 插件: zjtest7-redis:/usr/local/elasticsearch-2.3.4# bin/plugi ...
- Elasticsearch 单模式下API的增删改查操作
<pre name="code" class="html">Elasticsearch 单模式下API的增删改查操作 http://192.168. ...
- Vc数据库编程基础MySql数据库的表增删改查数据
Vc数据库编程基础MySql数据库的表增删改查数据 一丶表操作命令 1.查看表中所有数据 select * from 表名 2.为表中所有的字段添加数据 insert into 表名( 字段1,字段2 ...
- Elasticsearch学习系列之单模式下API的增删改查操作
这里我们通过Elasticsearch的marvel插件实现单模式下API的增删改查操作 索引的初始化操作 创建索引之前可以对索引进行初始化操作,比如先指定shard数量以及replicas的数量 代 ...
- Java数据库连接--JDBC基础知识(操作数据库:增删改查)
一.JDBC简介 JDBC是连接java应用程序和数据库之间的桥梁. 什么是JDBC? Java语言访问数据库的一种规范,是一套API. JDBC (Java Database Connectivit ...
- JDBC基础学习(一)—JDBC的增删改查
一.数据的持久化 持久化(persistence): 把数据保存到可掉电式存储设备中以供之后使用.大多数情况下,数据持久化意味着将内存中的数据保存到硬盘上加以固化,而持久化的实现过程大多通过各 ...
- MongoDB(二)-- Java API 实现增删改查
一.下载jar包 http://central.maven.org/maven2/org/mongodb/mongo-java-driver/ 二.代码实现 package com.xbq.mongo ...
- python基础学习之类的属性 增删改查
类中的属性如何在类外部使用代码进行增删改查呢 增加.改变: setattr内置函数以及 __setattr__魔法方法 class A: aaa = '疏楼龙宿' a = A() setattr(a, ...
随机推荐
- Java试验四
北京电子科技学院(BESTI) 实 验 报 告 课程: Java 班级:1352 姓名:朱国庆 学号:20135237 成绩: ...
- 超实用 1 ArrayList 链表
package ArrayList链表; import java.util.*; public class kk1 { /** * 作者:Mr.Fan * 功能:记住ArrayList链表 */ pu ...
- angularJS1笔记-(16)-模块里的constant、value、run
index.html: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- 汇编语言段和RSEG用法
RSEG是段选择指令,要想明白它的意思就要了解段的意思.段是程序代码或数据对象的存储单位.程序代码放到代码段,数据对象放到数据段.段分两种,一是绝对段,一是再定位段.绝对段在汇编语言中指定,在用L51 ...
- keil51下使用sprintf问题
测试环境:keil c51 + STC89C52说明: 1.keil的不定参数只有15个字节也就是说sizeof(...) 加起来总共不能超过15字节,否则会出错 2.当不定参数中有常数时,你也会得不 ...
- 更新ubuntu的源
什么是Ubuntu的软件源? 我们在使用Debian或者Ubuntu的apt-get工具来安装需要的软件时,其实就是从服务器获取需要安装的软件并把它安装在本地计算机的过程.所谓的软件源,就是我们获取软 ...
- Java中的设计模式之单例模式
Java中的单例模式 设计模式是软件开发过程中经验的积累 一.单例模式 1.单例模式是一种常用的软件设计模式,通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控 ...
- 实验一 命令解释程序cmd的编写
#include<stdio.h>#include<stdlib.h>#include<string.h>#define N 30main(){ char str[ ...
- vue使用axios发送数据请求
本文章是基于vue-cli脚手架下开发 1.安装 npm install axios --s npm install vue-axios --s 2.使用.在index.js中(渲染App组件的那个j ...
- 如何调换antd中Modal对话框确认按钮和取消按钮两个按钮的位置
今天有个工作是把所有的确认按钮放在取消按钮的左边,类似于下图这样的,公司用的时antd组件 但是antd组件的按钮时确认键放在右边的 可以采用下面的方式,将按钮调换过来: 对的,就是在modal里面的 ...