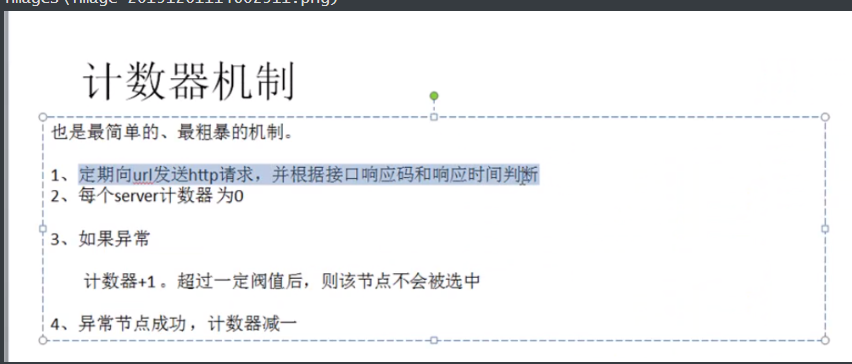
FailOver的机制
package util
import (
"fmt"
"hash/crc32"
"math/rand"
"sort"
"time"
)
type HttpServer struct { //目标server类
Host string
Weight int
CWeight int //当前权重
Status string //健康检查
FailCount int //计数器,默认是0
SuccessCount int //检查到连续成功,当连续成功的次数达到这个值,把宕机的的机器的FailCount立刻重置为0,加快服务器启动速度
}
type HttpServers []*HttpServer
func (p HttpServers) Len() int { return len(p) }
func (p HttpServers) Less(i, j int) bool { return p[i].CWeight > p[j].CWeight }
func (p HttpServers) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func NewHttpServer(host string, weight int) *HttpServer {
return &HttpServer{Host: host, Weight: weight, CWeight: 0}
}
type LoadBalance struct { //负载均衡类
Servers HttpServers
CurIndex int //指向当前访问的服务器
}
func NewLoadBalance() *LoadBalance {
return &LoadBalance{Servers: make([]*HttpServer, 0)}
}
func (this *LoadBalance) AddServer(server *HttpServer) {
this.Servers = append(this.Servers, server)
}
func (this *LoadBalance) SelectForRand() *HttpServer {
rand.Seed(time.Now().UnixNano())
index := rand.Intn(len(this.Servers))
fmt.Println(index)
return this.Servers[index]
}
func (this *LoadBalance) SelectByIpHash(ip string) *HttpServer {
index := int(crc32.ChecksumIEEE([]byte(ip))) % len(this.Servers) //通过取余永远index都不会大于this.servers的长度
return this.Servers[index]
}
func (this *LoadBalance) SelectByWeight(ip string) *HttpServer { //加权随机算法
rand.Seed(time.Now().UnixNano())
index := rand.Intn(len(ServerIndices)) //这里因为权重表为15个1和5个0组成,所以产生0到19的随机数
fmt.Println(this.Servers[ServerIndices[index]])
return this.Servers[ServerIndices[index]] //通过随机数的索引获得服务器索引进而获得地址
}
func (this *LoadBalance) SelectByWeightBetter(ip string) *HttpServer {
rand.Seed(time.Now().UnixNano())
sumList := make([]int, len(this.Servers))
sum := 0
for i := 0; i < len(this.Servers); i++ {
sum += this.Servers[i].Weight
sumList[i] = sum
}
_rand := rand.Intn(sum)
for index, value := range sumList {
if _rand < value {
return this.Servers[index]
}
}
return this.Servers[0]
}
func (this *LoadBalance) RoundRobin() *HttpServer {
server := this.Servers[this.CurIndex]
//this.CurIndex ++
//if this.CurIndex >= len(this.Servers) {
// this.CurIndex = 0
//}
this.CurIndex = (this.CurIndex + 1) % len(this.Servers)
if server.Status == "Down" { //如果当前节点宕机了,则递归查找可以用的服务器
return this.RoundRobin()
}
return server
}
func (this *LoadBalance) RoundRobinByWeight() *HttpServer {
server := this.Servers[ServerIndices[this.CurIndex]]
this.CurIndex = (this.CurIndex + 1) % len(ServerIndices)
return server
}
func (this *LoadBalance) RoundRobinByWeight2() *HttpServer { //加权轮询 ,使用区间算法
server := this.Servers[0]
sum := 0
//3:1:1
for i := 0; i < len(this.Servers); i++ {
sum += this.Servers[i].Weight //第一次是3 [0,3) [3,4) [4,5)
if this.CurIndex < sum {
server = this.Servers[i]
if this.CurIndex == sum-1 && i != len(this.Servers)-1 {
this.CurIndex++
} else {
this.CurIndex = (this.CurIndex + 1) % sum //这里是重要的一步
}
fmt.Println(this.CurIndex)
break
}
}
return server
}
func (this *LoadBalance) RoundRobinByWeight3() *HttpServer { //平滑加权轮询
for _, s := range this.Servers {
s.CWeight = s.CWeight + s.Weight
}
sort.Sort(this.Servers)
max := this.Servers[0]
max.CWeight = max.CWeight - SumWeight
return max
}
var LB *LoadBalance
var ServerIndices []int
var SumWeight int
func checkServers(servers HttpServers) {
t:= time.NewTicker(time.Second*3)
check:=NewHtttpChecker(servers)
for {
select{
case <- t.C:
check.Check(time.Second*2)
for _,s:=range servers{
fmt.Println(s.Host,s.Status,s.FailCount)
}
fmt.Println("---------------------------------")
}
}
}
func init() {
LB = NewLoadBalance()
LB.AddServer(NewHttpServer("http://localhost:12346", 3)) //web1
LB.AddServer(NewHttpServer("http://localhost:12347", 1)) //web2
LB.AddServer(NewHttpServer("http://localhost:12348", 1)) //web2
for index, server := range LB.Servers {
if server.Weight > 0 {
for i := 0; i < server.Weight; i++ {
ServerIndices = append(ServerIndices, index)
}
}
SumWeight = SumWeight + server.Weight //计算加权总和
}
go checkServers(LB.Servers)
//fmt.Println(ServerIndices)
}
package util
import (
"net/http"
"time"
)
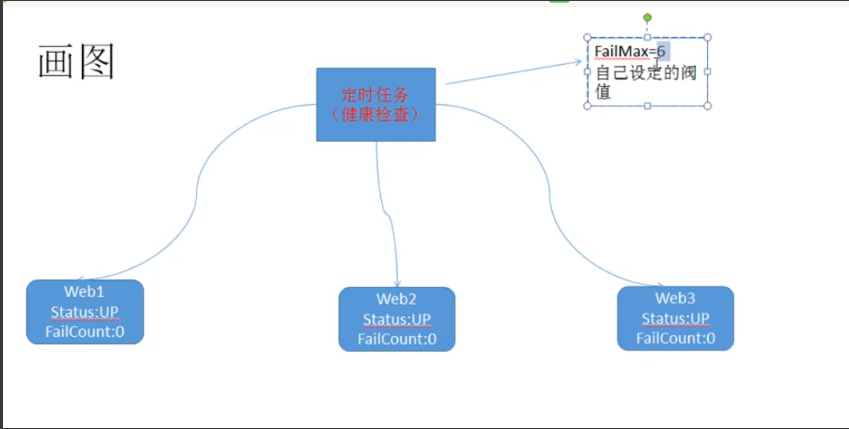
type HttpChecker struct {
Servers HttpServers
FailMax int
RecovCount int //连续成功到达这个值,就会被标识为UP
}
func NewHtttpChecker(servers HttpServers) *HttpChecker {
return &HttpChecker{Servers: servers, FailMax: 6, RecovCount: 3}
}
func (this *HttpChecker) Check(timeout time.Duration) {
client := http.Client{}
for _, server := range this.Servers {
res, err := client.Head(server.Host)
if res != nil {
defer res.Body.Close()
}
if err != nil { //宕机了
this.Fail(server)
continue
}
if res.StatusCode >= 200 && res.StatusCode < 400 {
this.Success(server)
} else {
this.Fail(server)
}
}
}
func (this *HttpChecker) Fail(server *HttpServer) {
if server.FailCount >= this.FailMax { //超过阈值
server.Status = "DOWN"
} else {
server.FailCount++
}
server.SuccessCount = 0
}
func (this *HttpChecker) Success(server *HttpServer) {
if server.FailCount > 0 {
server.FailCount--
server.SuccessCount++
if server.SuccessCount == this.RecovCount {
server.FailCount = 0
server.Status = "UP"
server.SuccessCount = 0
}
} else {
server.Status = "UP"
}
}
FailOver的机制的更多相关文章
- MySQL Proxy和 Amoeba 工作机制浅析
MySQL Proxy处于客户端应用程序和MySQL服务器之间,通过截断.改变并转发客户端和后端数据库之间的通信来实现其功能,这和WinGate 之类的网络代理服务器的基本思想是一样的.代理服务器是和 ...
- Hadoop学习笔记—15.HBase框架学习(基础知识篇)
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型,它存储的是 ...
- Thrift 个人实战--Thrift 服务化 Client的改造
前言: Thrift作为Facebook开源的RPC框架, 通过IDL中间语言, 并借助代码生成引擎生成各种主流语言的rpc框架服务端/客户端代码. 不过Thrift的实现, 简单使用离实际生产环境还 ...
- HBase replication
Hbase Replication 介绍 现状 Hbase 的replication目前在业界使用并不多见,原因有很多方面,比如说HDFS目前已经有多份备份在某种程度上帮助HBASE底层数据的安全性, ...
- Apache-Flink深度解析-State
摘要: 实际问题 在流计算场景中,数据会源源不断的流入Apache Flink系统,每条数据进入Apache Flink系统都会触发计算.如果我们想进行一个Count聚合计算,那么每次触发计算是将历史 ...
- Mysql读写分离方案-Amoeba环境部署记录
Mysql的读写分离可以使用MySQL Proxy,也可以使用Amoeba.Amoeba(变形虫)项目是一个类似MySQL Proxy的分布式数据库中间代理层软件,是由陈思儒开发的一个开源的java项 ...
- Others-阿里专家强琦:流式计算的系统设计和实现
阿里专家强琦:流式计算的系统设计和实现 更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud 阿里云数据事业部强琦为大家带来题为“流式计算的系统设计与实现”的演讲,本 ...
- MongoDB 走马观花(全面解读篇)
目录 一.简介 二.基本模型 BSON 数据类型 分布式ID 三.操作语法 四.索引 索引特性 索引分类 索引评估.调优 五.集群 分片机制 副本集 六.事务与一致性 一致性 小结 一.简介 Mong ...
- 了解 MongoDB 看这一篇就够了【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
随机推荐
- css3 网页图片轮播的实现
.lunbo{ height: 640px; width: 100%; background-position: -280px; margin-top: 103px; -webkit-animatio ...
- xxx商城之商品管理
- uni-app项目导入第三方组件库muse-ui
你说uni-app是什么 我说,uni-app是一套基于vue.js开发跨平台应用的前端框架,可编译多个平台,比如:Android.IOS.H5.微信小程序.支付宝小程序.头条小程序.百度小程序 懂行 ...
- 论文笔记 XGBoost: A Scalable Tree Boosting System
XGBoost是boosting算法的其中一种.Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器,其更关注与降低基模型的偏差.XGBoost是一种提升树模型(Gradient bo ...
- SpringBoot 多数据库支持:
SpringBoot 多数据库支持: springboot2.0+mybatis多数据源集成 https://www.cnblogs.com/cdblogs/p/9275883.html Spring ...
- java之struts2之拦截器
1.struts2能完成数据的设置,数据的封装,数据的类型转换,数据的校验等等.struts2是如何来完成这些功能的?struts2的所有功能都是由拦截器来完成的. 2.拦截器是struts2的核心. ...
- Java调用Http/Https接口(1)--编写服务端
Http接口输入的数据一般是键值对或json数据,返回的一般是json数据.本系列文章主要介绍Java调用Http接口的各种方法,本文主要介绍服务端的编写,方便后续文章里的客户端的调用.文中所使用到的 ...
- 动画处理<并行和串行>
并行动画 当多个动画定义同时指向某个组件,并使用动画控制器启动时,就产生了并行动画(Parallel Animation).例如我们可以让一个组件: 移动的同时改变大小 旋转的同时边界颜色闪烁 圆形图 ...
- Synchronized 和 Lock 的主要区别(转)
Synchronized 和 Lock 的主要区别Synchronzied 和 Lock 的主要区别如下: 存在层面:Syncronized 是Java 中的一个关键字,存在于 JVM 层面,Lock ...
- css3可拖动的魔方3d
css3可拖动的魔方3d 主要用到知识点: css3 3d转换 原生js鼠标拖动事件 display:grid 布局 实现的功能 3d魔方 可点击,可拖动 直接看效果 html: <div cl ...