Mysql 表分区分类
针对Mysql数据库,表分区类型简析。
【1】表分区类型
(1)Range分区:按范围分区。按列值的范围区间进行分区存储;比如:id小于10存储在一个分区;id大于10小于20存储在另外一个分区;
(2)List分区:按离散值集合分区。与range分区类似,不过它是按离散值进行分区。
(3)Hash分区:按hash算法结果分区。对用户定义的表达式所返回的hash值来进行分区。
可以写partitions num(分区数目),或直接使用分区语句,比如partition p0 values in … ..
根据分区算法的不同,Hash分区分为一般(取模法)Hash分区和线性(线性Hash规则,详见下线性hash分区内容)Hash分区。
(4)Key分区:Key分区类似于Hash分区,不同点如下:
[1] Key分区允许多列,而Hash分区只允许一列。
[2] 如果在有主键或者唯一键的情况下,Key中分区列可不指定,默认为主键或者唯一键;如果没有,则必须显性指定列。
[3] Key分区对象必须为列,而不能是基于列的表达式。
[4] Key分区和Hash分区的算法不一样。PARTITION BY HASH (expr),MOD取值的对象是expr返回的值,而PARTITION BY KEY (column_list),基于列的MD5值。
(5)子分区:在一级分区的基础上,再进行分区后才存储。
【2】Range分区
Range分区创建表SQL语句:
-- ----------------------------BEGIN RANGE---------------------
-- 按Range范围分区
-- [1]删除旧表
DROP TABLE `t_partition_by_range`;
-- [2]创建新表
CREATE TABLE `t_partition_by_range`
(
`id` INT AUTO_INCREMENT PRIMARY KEY,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) DEFAULT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL
) ENGINE = INNODB
PARTITION BY RANGE(id)
(
PARTITION p0 VALUES LESS THAN(5),
PARTITION p1 VALUES LESS THAN(10),
PARTITION p2 VALUES LESS THAN(15)
);
-- [3]添加源数据
INSERT INTO t_partition_by_range
(sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
('wangchao', 8, 'heyang', 1, 1801111, 0),
('suntao', 9, 'weinan', 3, 1803110, 1),
('liuyan', 16, 'hancheng', 2, 20190211, 0),
('xuhui', 22, 'hancheng', 4, 201904107, 1),
('wangqi', 18, 'xian', 10, 201910104, 1),
('baihua', 16, 'nanjing', 8, 201908105, 1),
('xiaoping', 15, 'shenzhen', 6, 20190603, 1);
-- [4]查询分区信息
SELECT PARTITION_NAME, TABLE_ROWS, PARTITION_METHOD,
PARTITION_EXPRESSION, PARTITION_DESCRIPTION, PARTITION_ORDINAL_POSITION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 't_partition_by_range';
-- ----------------------------END RANGE---------------------
分区存储信息结果:

如上表,理论与实际结合分析:
把id < 5的4个实体(wangchao、suntao、liuyan、xuhui)存储在分区p0;
把5 < id < 10的3个实体(wangqi、baihua、xiaoping)存储在分区p1;
把10 < id < 15的实体会存储在分区p2;
【3】List分区
List分区创建表SQL语句:
-- ----------------------------BEGIN LIST---------------------
-- 按List范围分区
-- [1]删除旧表
DROP TABLE `t_partition_by_list`;
-- [2]创建新表
CREATE TABLE `t_partition_by_list`
(
`id` INT AUTO_INCREMENT ,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL,
PRIMARY KEY (`id`, `sGrade`)
) ENGINE = INNODB PARTITION BY LIST(sGrade)
(
PARTITION p0 VALUES IN(1, 3),
PARTITION p1 VALUES IN(2, 4, 6),
PARTITION p3 VALUES IN(10)
);
-- [3]添加源数据
INSERT INTO t_partition_by_list
(sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
('wangchao', 8, 'heyang', 1, 1801111, 0),
('suntao', 9, 'weinan', 3, 1803110, 1),
('liuyan', 16, 'hancheng', 2, 20190211, 0),
('xuhui', 22, 'hancheng', 4, 201904107, 1),
('wangqi', 18, 'xian', 10, 201910104, 1),
('baihua', 16, 'nanjing', 1, 201908105, 1),
('xiaoping', 15, 'shenzhen', 6, 20190603, 1);
-- [4]查询分区信息
SELECT PARTITION_NAME, TABLE_ROWS, PARTITION_METHOD,
PARTITION_EXPRESSION, PARTITION_DESCRIPTION, PARTITION_ORDINAL_POSITION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 't_partition_by_list';
-- ----------------------------END LIST---------------------
分区存储信息结果:

如上表,理论与实际结合分析:
把班级sgrade归属于离散值集合为(1、3)的3个实体(wangchao、suntao、baihua)存储在分区p0;
把班级sgrade归属于离散值集合为(2、4、6)的3个实体(liuyan、xuhui、xiaoping)存储在分区p1;
把班级sgrade归属于离散值集合为(10)的1个实体(wangqi)存储在分区p2;
另外,关于list分区表,尤其注意:当分区字段的值不归属于任何一个离散值集合时,数据会插入失败!
比如:插入源数据SQL语句:
INSERT INTO t_partition_by_list
(sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
('wangchao', 8, 'heyang', 1, 1801111, 0),
('suntao', 9, 'weinan', 3, 1803110, 1),
('liuyan', 16, 'hancheng', 2, 20190211, 0),
('xuhui', 22, 'hancheng', 4, 201904107, 1),
('wangqi', 18, 'xian', 10, 201910104, 1),
('baihua', 16, 'nanjing', 8, 201908105, 1),
('xiaoping', 15, 'shenzhen', 6, 20190603, 1);
插入失败,失败信息如下:
查询:INSERT INTO t_partition_by_list (sName, sAge, sAddr, sGrade, sStuId, sSex) VALUES ('wangchao', 8, 'heyang', 1, 1801111, 0), ('su...错误代码: 1526
Table has no partition for value 8
【4】Hash分区
(1)一般Hash分区
Hash分区创建表SQL语句:
-- ----------------------------BEGIN HASH---------------------
-- 按Hash值分区
-- [1]删除旧表
DROP TABLE `t_partition_by_hash`;
-- [2]创建新表
CREATE TABLE `t_partition_by_hash`
(
`id` INT AUTO_INCREMENT PRIMARY KEY,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL
) ENGINE = INNODB PARTITION BY HASH(id) PARTITIONS 4;
-- [3]添加源数据
INSERT INTO t_partition_by_hash
(sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
('wangchao', 8, 'heyang', 3, 1803111, 0),
('suntao', 9, 'weinan', 6, 1806110, 1),
('liuyan', 16, 'hancheng', 8, 20190811, 0),
('xuhui', 22, 'hancheng', 12, 201912107, 1),
('wangqi', 18, 'xian', 11, 201911104, 1),
('baihua', 16, 'nanjing', 10, 201910105, 1),
('xiaoping', 15, 'shenzhen', 9, 20190103, 1);
-- [4]查询分区信息
SELECT PARTITION_NAME, TABLE_ROWS, PARTITION_METHOD,
PARTITION_EXPRESSION, PARTITION_DESCRIPTION, PARTITION_ORDINAL_POSITION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 't_partition_by_hash';
-- ----------------------------END HASH---------------------
分区存储信息结果:

如上表,理论与实际结合分析:我们知道,一般情况下(非一般情况比如线性hash),hash分区使用的哈希函数为求模数。
那我们先利用Mysql的求模数函数分析一下,执行SQL如下:
SELECT id, MOD(id, 4) AS p_index FROM t_partition_by_hash ORDER BY id;
结果如下图:
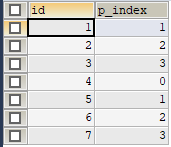
现在再结合上图分区信息的结果,我们得知:
把id哈希值为0的1个实体(xuhui)存储在分区p0;
把id哈希值为1的2个实体(wangchao、wangqi)存储在分区p1;
把id哈希值为2的2个实体(suntao、baihua)存储在分区p2;
把id哈希值为3的2个实体(liuyan、xiaoping)存储在分区p3;
好的,分析至此,我们查询一下数据存储的实际情况:
SQL语句如下:
SELECT * FROM t_partition_by_hash;
执行结果如下图:
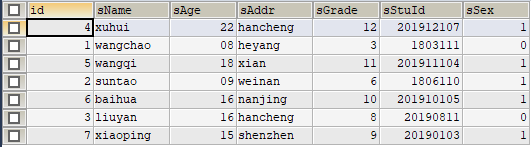
如上图,查询时,数据库引擎会按照分区顺序p0~p3依次读取到各个分区的数据内容。
(2)线性Hash分区
线性Hash分区创建表SQL语句:
-- ----------------------------BEGIN LINEAR HASH---------------------
-- 按Linear Hash值分区
-- [1]删除旧表
DROP TABLE `t_partition_by_linear_hash`;
-- [2]创建新表
CREATE TABLE `t_partition_by_linear_hash`
(
`id` INT NOT NULL,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL
) ENGINE = INNODB PARTITION BY LINEAR HASH(sGrade) PARTITIONS 6;
-- [3]添加源数据
INSERT INTO t_partition_by_linear_hash
(id, sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
(1, 'wangchao', 8, 'heyang', 3, 1803111, 0),
(2, 'suntao', 9, 'weinan', 6, 1806110, 1),
(3, 'liuyan', 16, 'hancheng', 8, 20190811, 0),
(4, 'xuhui', 22, 'hancheng', 12, 201912107, 1),
(5, 'wangqi', 18, 'xian', 11, 201911104, 1),
(6, 'baihua', 16, 'nanjing', 10, 201910105, 1),
(7, 'xiaoping', 15, 'shenzhen', 9, 20190103, 1);
-- [4]查询分区信息
SELECT PARTITION_NAME, TABLE_ROWS, PARTITION_METHOD,
PARTITION_EXPRESSION, PARTITION_DESCRIPTION, PARTITION_ORDINAL_POSITION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 't_partition_by_linear_hash';
-- ----------------------------END LINEAR HASH---------------------
分区存储信息结果:

学习一下线性Hash分区的规则:
假设分区个数num = 6, 那么N表示数据最终存储的分区:
[1] 第一步,确定V值
V值计算公式:V = POWER(2, CEILING(LOG(2, num)))
LOG()是计算num以2为底的对数,CEILING()是向上取整,POWER()是取2的次方值。
假设num的值是2的倍数那么这个表达式计算出来的结果不变。
V = POWER(2, CEILING(LOG(2, 6)))
V = POWER(2, 3)
V = 8
[2] 第二步,计算N值
N值计算公式:N = values & (V - 1)
&位与运算,将两个值都转换成二进制进行求与运算。
N = values & (V - 1)
N = 3 & (8 - 1)
N = 3 & 7
N = 3
[3] 第三步(当N >= num场景)
因为分区个数为num,那么,当N >= num时,显然分区仍未知,需要再求N值:
N值计算公式:N = N & (CEIL(V / 2) - 1)
N = 6 & (CEIL(8 / 2) - 1)
N = 6 & 3
N = 2
由于2不大于或等于6,所以可以确定存储在分区p2。
依据以上规则,下面首先,我们计算一级分区存储索引号,SQL语句如下:
SELECT id,
sGrade & (POWER(2, CEILING(LOG(2, 6))) - 1) AS p_index
FROM t_partition_by_linear_hash ORDER BY id;
结果如下图:

很明显,id为2的实体,一级N值为6,需要进行第三步再确认,经规则示例分析,再确认结果应该为2。
好的,至此为止,我们已经分析完成,验证源数据存储实际情况,结果如下图:
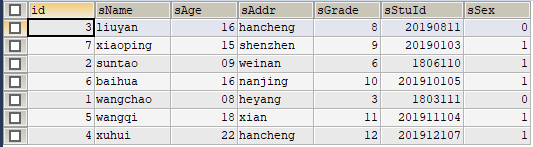
经验证,可知:
sGrade为8(id为3)的实体被存储在分区p0;
sGrade为9(id为7)的实体被存储在分区p1;
sGrade为6、10(id为2、6)的实体被存储在分区p2;
sGrade为3、11(id为1、5)的实体被存储在分区p3;
sGrade为12(id为4)的实体被存储在分区p4;
综上所述,实际与理论分析完全一致。
【5】Key分区
Key分区创建表SQL语句:
-- ----------------------------BEGIN KEY-----------------------
-- [1]删除旧表
DROP TABLE `t_partition_by_key`;
-- [2]创建新表
CREATE TABLE `t_partition_by_key`
(
`id` INT AUTO_INCREMENT,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL,
PRIMARY KEY (`id`, `sGrade`)
) ENGINE = INNODB PARTITION BY KEY(sGrade) PARTITIONS 6;
-- [3]添加源数据
INSERT INTO t_partition_by_key
(sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
('wangchao', 8, 'heyang', 3, 1803111, 0),
('suntao', 9, 'weinan', 3, 1803110, 1),
('liuyan', 16, 'hancheng', 8, 20190811, 0),
('xuhui', 22, 'hancheng', 8, 201908107, 1),
('wangqi', 18, 'xian', 10, 201910104, 1),
('baihua', 16, 'nanjing', 10, 201910105, 1),
('xiaoping', 15, 'shenzhen', 9, 20190903, 1);
-- [4]查询分区信息
SELECT PARTITION_NAME, TABLE_ROWS, PARTITION_METHOD,
PARTITION_EXPRESSION, PARTITION_DESCRIPTION, PARTITION_ORDINAL_POSITION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 't_partition_by_key';
-- ----------------------------END KEY---------------------
分区存储信息结果:

总结:从分区存储信息结果可知,p2分区存储了3个实体;p3分区存储了2个实体;p5分区存储了2个实体。的确已全部存储。
鉴于目前只明确Key分区的规则是基于列的MD5值,但具体为什么7个实体分别放在了p2、p3、p5分区,细节分析未果,待再研究。
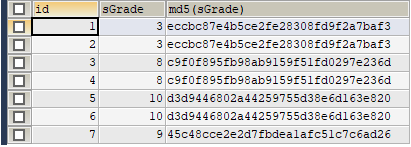
附加目前分析进展,MD5值如下图:
查询SQL语句:
SELECT id, sGrade, MD5(sGrade) FROM t_partition_by_key ORDER BY id;
结果集:
【6】子分区
子分区创建表SQL语句:
-- ----------------------------BEGIN SUB PARTITION---------------------
-- 按SUB PARTITION分区
-- [1]删除旧表
DROP TABLE `t_partition_by_subpart`;
-- [2]创建新表
CREATE TABLE `t_partition_by_subpart`
(
`id` INT AUTO_INCREMENT,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL,
PRIMARY KEY (`id`, `sGrade`)
) ENGINE = INNODB
PARTITION BY RANGE(id)
SUBPARTITION BY HASH(sGrade) SUBPARTITIONS 2
(
PARTITION p0 VALUES LESS THAN(5),
PARTITION p1 VALUES LESS THAN(10),
PARTITION p2 VALUES LESS THAN(15)
);
-- [3]添加源数据
INSERT INTO t_partition_by_subpart
(sName, sAge, sAddr, sGrade, sStuId, sSex)
VALUES
('wangchao', 8, 'heyang', 3, 1803111, 0),
('suntao', 9, 'weinan', 3, 1803110, 1),
('liuyan', 16, 'hancheng', 8, 20190811, 0),
('xuhui', 22, 'hancheng', 8, 201908107, 1),
('wangqi', 18, 'xian', 10, 201910104, 1),
('baihua', 16, 'nanjing', 10, 201910105, 1),
('xiaoping', 15, 'shenzhen', 9, 20190903, 1);
-- [4]查询分区信息
SELECT PARTITION_NAME, TABLE_ROWS, PARTITION_METHOD,
PARTITION_EXPRESSION, PARTITION_DESCRIPTION, PARTITION_ORDINAL_POSITION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 't_partition_by_subpart';
-- ----------------------------END SUB PARTITION---------------------
分区存储信息结果:

如上表,理论与实际结合分析:
把id < 5的4个实体(wangchao、suntao、liuyan、xuhui)存储在分区p0;
把5 < id < 10的3个实体(wangqi、baihua、xiaoping)存储在分区p1;
把10 < id < 15的实体会存储在分区p2;
按子分区再分析:
子分区为hash分区,即以sGrade值取模值作为分区索引号,查询SQL如下:
SELECT id, sGrade, MOD(sGrade, 2) FROM t_partition_by_subpart ORDER BY id;
分区索引号结果如下图:
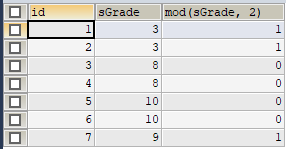
id为1、2、3、4的实体,按主range分区,应该归属于p0分区;再按子hash分区:
因为实体1、2(wangchao、suntao)的sGrade值均为3,取模后值为1,即存储在p0的第二个子分区;
因为实体3、4(liuyan、xuhui)的sGrade值均为8,取模后置为0,即存储在p0的第一个子分区;
id为5、6、7的实体,按主range分区,应该归属于p1分区;再按子hash分区:
因为实体5、6(wangqi、baihua)的sGrade值均为10,取模后值为0,即存储在p1的第一个子分区;
因为实体7(xiaoping)的sGrade值为9,取模后值为1,即存储在p1的第二个子分区。
好的,分析至此,我们查询一下数据存储的实际情况:
SQL语句如下:
SELECT * FROM t_partition_by_subpart;
实际情况:
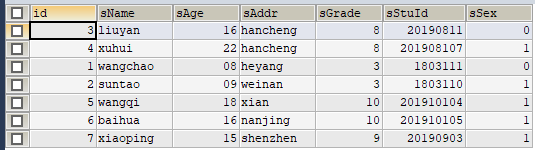
如上图,说明:
因为查询时数据库引擎会按照分区顺序p0~p3依次读取到各个分区(包括子分区)存储的数据内容,可见与我们的理论分析结果相符。
Good Good Study, Day Day Up.
顺序 选择 循环 总结
Mysql 表分区分类的更多相关文章
- MySQL表分区技术
MySQL表分区技术 MySQL有4种分区类型: 1.RANGE 分区 - 连续区间的分区 - 基于属于一个给定连续区间的列值,把多行分配给分区: 2.LIST 分区 - 离散区间的分区 - 类似于按 ...
- Mysql 表分区和性能
以下内容节选自<Mysql技术内幕InnoDB存储引擎> mysql表分区: 分区功能并不是所有存储引擎都支持的,如CSV.MERGE等就不支持.mysql数据库支持的分区类型为水平分区( ...
- Mysql表分区的选择与实践小结
在一些系统中有时某张表会出现百万或者千万的数据量,尽管其中使用了索引,查询速度也不一定会很快.这时候可能就需要通过分库,分表,分区来解决这些性能瓶颈. 一. 选择合适的解决方法 1. 分库分表. 分库 ...
- MYSQL 表分区的 3 方法
背景知识: 表分区是把逻辑上同一范围的数据保存到同一个文件中,就和超市一样,把同类商品放在同一个区域,把不同的商品放在不同的地方.不同的是超市中 是根据用途分类的,表分区是根据它的取值区间来分的. 分 ...
- Mysql 表分区
是否支持分区:mysql> show variables like '%partition%';+-----------------------+-------+| Variable_name ...
- MySQL 表分区详解MyiSam引擎和InnoDb 区别(实测)
一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了.如:某用户表的记录超过了1000万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区 ...
- mysql表分区(摘自 MySQL表的四种分区类型)
一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了. 如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区 ...
- MySQL表分区
MySQL的表分区 一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了.如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以 ...
- mysql表分区、查看分区
原文地址:http://blog.csdn.net/feihong247/article/details/7885199 一. mysql分区简介 数据库分区 数据库分区是一种物理数据库设 ...
随机推荐
- 开发技术--Numpy模块
开发|Numpy模块 Numpy模块是数据分析基础包,所以还是很重要的,耐心去体会Numpy这个工具可以做什么,我将从源码与 地产呢个实现方式说起,祝大家阅读愉快! Numpy模块提供了两个重要对象: ...
- 配置Java,jdk环境变量
注意:所有的都是配系统变量 变量名:JAVA_HOME 变量值:D:\Program Files\Java\jdk1.8.0_202(以自己的为准)变量名:Path 变量值:%JAVA_HOME%\b ...
- Linux发展史与安装-Linux从入门到精通第一天(非原创)
文章大纲 一.Linux发展史二.Linux系统的安装三.Linux系统的文件四.学习资料下载五.参考文章 一.Linux发展史 1. Linux前身-Unix 1968年 Multics项目MI ...
- Spring之IoC详解(非原创)
文章大纲 一.Spring介绍二.Spring的IoC实战三.IoC常见注解总结四.项目源码及参考资料下载五.参考文章 一.Spring介绍 1. 什么是Spring Spring是分层的Java ...
- PHP7.2.6安装sodium扩展
安装libsodium libsodium是安装sodium扩展的必须依赖条件,我这里提供两种安装方式,编译和直接yum 编译安装libsodium wget https://github.com/j ...
- 枚举ENUM的tostring() valueof()name()和values()用法
从jdk5出现了枚举类后,定义一些字典值可以使用枚举类型; 枚举常用的方法是values():对枚举中的常量值进行遍历; valueof(String name) :根据名称获取枚举类中定义的常量值; ...
- 【转】Pandas学习笔记(六)合并 merge
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- php访问者模式(visitor design)
终于搞定,累成一滩,今晚不想说话. <?php /* The visitor design pattern is a way of separating an algorithm from an ...
- react.js知识汇总
首先ract的基本结构 var Input = React.createClass({ getInitialState: function() { return {value: 'Hello!'}; ...
- python scapy中sniffer的用法以及过滤器
Sniff方法定义: sniff(filter="",iface="any", prn=function, count=N) 1.filter的规则使用 Ber ...