dplyr 数据操作 统计描述(summarise)
在R中,summary()是一个基础包中的重要统计描述函数,同样的在dplyr中summarise()函数也可以对数据进行统计描述。
不同的是summarise()更加的灵活多变,下面来看下summarise这个函数
summarise(.data, ...)
其灵活性和其他dplyr函数一样,主要在于条件的使用上
下面看些具体的例子
library(dplyr)
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x

summarise(x,sum(shuxue))

可以很好的配合聚合函数一起使用
summarise(group_by(x,name),sum(shuxue))

这里由于每个name对应的shuxue只有一个参数,所以sum的结果没变化。
summarise(group_by(x,name),sum(shuxue,yuwen))

可以看出shuxue和yuwen求和后的数据。
arrange(summarise(group_by(x,name),qiuhe=sum(shuxue,yuwen)),desc(qiuhe))

配合上前面的函数,就可以对求和后的数据进行排序,当然上面数据的可读性较低。
把他分为两个步骤,理解起来可能会相对比较容易。
y<-summarise(group_by(x,name),qiuhe=sum(shuxue,yuwen)) 求和过程
arrange(y,desc(qiuhe)) 排序过程
summarise(x,mean(shuxue),sd(shuxue))

求均值和方差
summarise(group_by(x,name),a=n(),b=a+2)

配合你n()可以对每个因子的出现次数进行统计。
summarise_all(group_by(x,name),mean)

对所有列按照name分组后求平均值
summarise_if(x,is.numeric,mean)

对所有是数值的列求平均值
summarise_at(x,c(3,4),mean)

对特定的列求平均值
类似结果的表达方式有:
summarise_at(x,vars(shuxue,yuwen),mean)
summarise_at(x,c("shuxue","yuwen"),mean)
summarise_all(select(x,c(1,3,4)),funs(min,max,mean,sum,sd))
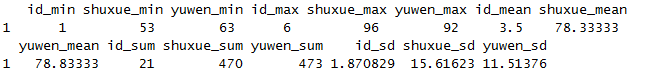
使用funs,对数据进行多重聚合统计。
summarise_each(x[c(1,3,4)],funs(mean,sum))
summarise_each也可以达到类似的效果。
dplyr 数据操作 统计描述(summarise)的更多相关文章
- SQL大数据操作统计
SQL大数据操作统计 1:select count(*) from table的区别SELECT object_name(id) as TableName,indid,rows,rowcnt FROM ...
- dplyr 数据操作 常用函数(5)
继续来了解dplyr中的其他有用函数 1.sample() 目的是可以从一个数据框中,随机抽取一些行,然后组成新的数据框. sample_n(tbl, size, replace = FALSE, w ...
- dplyr 数据操作 常用函数(3)
接下了我们继续了解dplyr中有用的函数 1.if_else() if_else主要用于在数据做判断用 x<-data.frame(id=1:6, name=c("wang" ...
- dplyr 数据操作 常用函数(1)
上面介绍完dplyr中,几个主要的操作函数后,我们再进一步了解dplyr中那些函数可能我们会经常要用到. 这里主要根据dplyr包作者的书籍目录来把它列出来. 1.add_rownames 添加行名称 ...
- dplyr 数据操作 列操作(select / mutate)
在R中,我们通常需要对数据列进行各种各样的操作,比如选取某一列.重命名某一列等. dplyr中的select函数子在数据列的操作上也同样表现了它的简洁性,而且各种操作眼花缭乱. select(.dat ...
- dplyr 数据操作 数据过滤 (filter)
在R的使用过程中我们几乎都绕不开Hadley Wickham 开发的几个包,前面说过的ggplot2.reshape2以及即将要讲的dplyr 因为这几个包可以非常轻易的使我们从复杂的数据操作中逃离, ...
- dplyr 数据操作 常用函数(4)
接下来我们继续了解一些dplyr中的常用函数. 1.ranking 以下各个函数可以实现对数据进行不同的排序 row_number(x) ntile(x, n) min_rank(x) dense_r ...
- dplyr 数据操作 常用函数(2)
继上一节常用函数,继续了解其他函数 1.desc() 这个函数和SQL中的排序用法是一样的,表示对数据进行倒序排序. 接下来我们看些例子. a=sample(20,50,rep=T)a desc(a) ...
- dplyr 数据操作 数据排序 (arrange)
在R中,我们在整理数据时,经常需要对数据排序,以便数据增强数据的可读性. 下面我们来看下dplyr中的,arrange函数 arrange(.data, ...) 跟filter()类似,arrang ...
随机推荐
- IntelliJ IDEA 设置代码提示或自动补全的快捷键 (附IntelliJ IDEA常用快捷键)
修改方法如下: 点击 文件菜单(File) –> 点击 设置(Settings- Ctrl+Alt+S), –> 打开设置对话框. 在左侧的导航框中点击 KeyMap. 接着在右边的树型框 ...
- H5自带表单验证
HTML5自带的表单验证 转载:https://www.web-tinker.com/article/20781.html HTML5对表单元素提供了patern属性,它接受一个正则表达式.表单提交时 ...
- EXCEL 数字统一转换成文本
将excel中的数字统一转换成文本形式.即添加‘. 1.点击数据-分列. 2.分隔符号-下一步. 3.选择文本识别符号,如“‘”分号. 4. 选中文本-完成.
- Openjudge-NOI题库-数根
题目描述 Description 数根可以通过把一个数的各个位上的数字加起来得到.如果得到的数是一位数,那么这个数就是数根.如果结果是两位数或者包括更多位的数字,那么再把这些数字加起来.如此进行下去, ...
- Html5移动端页面自适应百分比布局
按百分比布局,精度肯定不会有rem精确 <!DOCTYPE html> <html lang="en"> <head> <meta cha ...
- AC日记——【模板】字符串哈希 洛谷 3370
题目描述 如题,给定N个字符串(第i个字符串长度为Mi,字符串内包含数字.大小写字母,大小写敏感),请求出N个字符串中共有多少个不同的字符串. 友情提醒:如果真的想好好练习哈希的话,请自觉,否则请右转 ...
- 转:AFNetworking 与 UIKit+AFNetworking 详解
资料来源 : http://github.ibireme.com/github/list/ios GitHub : 链接地址 简介 : A delightful iOS and OS X networ ...
- c#如何使两个方法并行运行
static void Main(string[] args) { Parallel.Invoke(Foo, Bar); } static void ...
- chd校内选拔赛题目+题解
题目链接 A. Currency System in Geraldion 有1时,所有大于等于1的数都可由1组成.没有1时,最小不幸的数就是1. #include<iostream> ...
- rocketmq(1)
参考: 开源社区:https://github.com/alibaba/RocketMQ rocketmq入门: http://www.cnblogs.com/LifeOnCode/p/4805953 ...