CentOS 安装 Hadoop
原文地址:http://www.cnblogs.com/caca/p/centos_hadoop_install.html
.png)
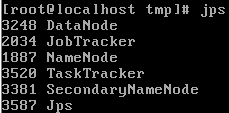
.png)
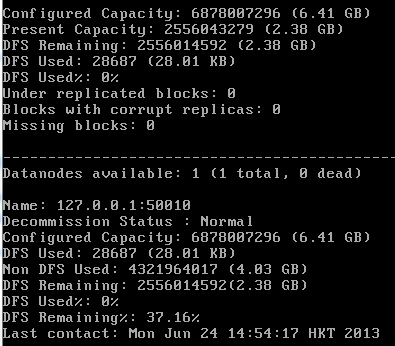
CentOS 安装 Hadoop的更多相关文章
- centos安装hadoop(伪分布式)
在本机上装的CentOS 5.5 虚拟机, 软件准备:jdk 1.6 U26 hadoop:hadoop-0.20.203.tar.gz ssh检查配置 [root@localhost ~]# ssh ...
- 腾讯云CentOS 安装 Hadoop 2.7.3
1.安装 jdk yum install java 2.安装maven wget http://mirrors.hust.edu.cn/apache/maven/maven-3/3.5.0/binar ...
- CentOS安装Hadoop
Hadoop的核心由3个部分组成: HDFS: Hadoop Distributed File System,分布式文件系统,hdfs还可以再细分为NameNode.SecondaryNameNode ...
- CentOS 安装 Hadoop 手记
Download & Install download hadoop from http://hadoop.apache.org/releases.html#Download downlo ...
- CentOS安装Hive
1.环境和软件准备: hive版本:apache-hive-2.3.6-bin.tar.gz,下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hive ...
- CentOS下安装hadoop
CentOS下安装hadoop 用户配置 添加用户 adduser hadoop passwd hadoop 权限配置 chmod u+w /etc/sudoers vi /etc/sudoers 在 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- CentOS 7 Hadoop安装配置
前言:我使用了两台计算机进行集群的配置,如果是单机的话可能会出现部分问题.首先设置两台计算机的主机名 root 权限打开/etc/host文件 再设置hostname,root权限打开/etc/hos ...
- 大数据——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
随机推荐
- iOS开发-UI基础Demo
现在更多的学习资料都是xCode4.X的,发现xCode6.1还是很多东西,如果有正在学习iOS开发的可以通过Demo简单了解下iOS的UI开发~ 1.新建单视图文件: 2.新建项目名称,语言选择OC ...
- c语言中pthread的理解和使用
在头文件中看到#typedef unsigned long int pthread_t这句话怎么理解,pthread_t是一个什么类型呢? 相当于pthread_t实际是个unsigned long ...
- (转)初识 Lucene
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能.Lucene 目前是 Apache Jakarta 家族中的一个开源项目. ...
- svn自助改动password(PHP脚本实现)
#创建脚本文件夹 mkdir -p /var/www/svn/svntools #创建apache配置文件 touch /etc/httpd/conf.d/alias.conf #输入下面内容: Al ...
- 【python】如何去掉使用BeautifulSoup读取html出现的警告UserWarning: You provided Unicode markup but also provided a value for from_encoding
如果我们这样读取html页面 soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='utf-8') # 粗体部分多余了 就会出现下面的警 ...
- (算法)Partition方法求数组第k大的数
如题,下面直接贴出代码: #include <iostream> using namespace std; int Partition(int* A,int left,int right) ...
- spring mvc返回jsonp内容
代码如下: import com.alibaba.fastjson.JSONPObject; @RequestMapping(value = "/method1") @Respon ...
- Android 之类库常用包
Android 是由谷歌公司推出的一款基于Linux平台的开源手机操作系统平台. 在Android类库中,各种包写成android.*的方式,重要包的描述如下所示: [1]android.app:提供 ...
- MySQL主从常见的架构
Master-Slave 级联 双Master互为主备
- SQL Server 2012 “阻止保存要求又一次创建表”的更改问题的设置方法
我们在用SQL Server 2012 建完表后,插入或改动随意列时,提示:当用户在在SQL Server 2012企业管理器中更改表结构时.必需要先删除原来的表.然后又一次创建新表,才干完毕表的更改 ...