Selenium2+python自动化53-unittest批量执行(discover)
前言
我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了。
加载用例后,用unittest里面的TextTestRunner这里类的run方法去一次执行多个脚本的用例。
一、新建测试项目
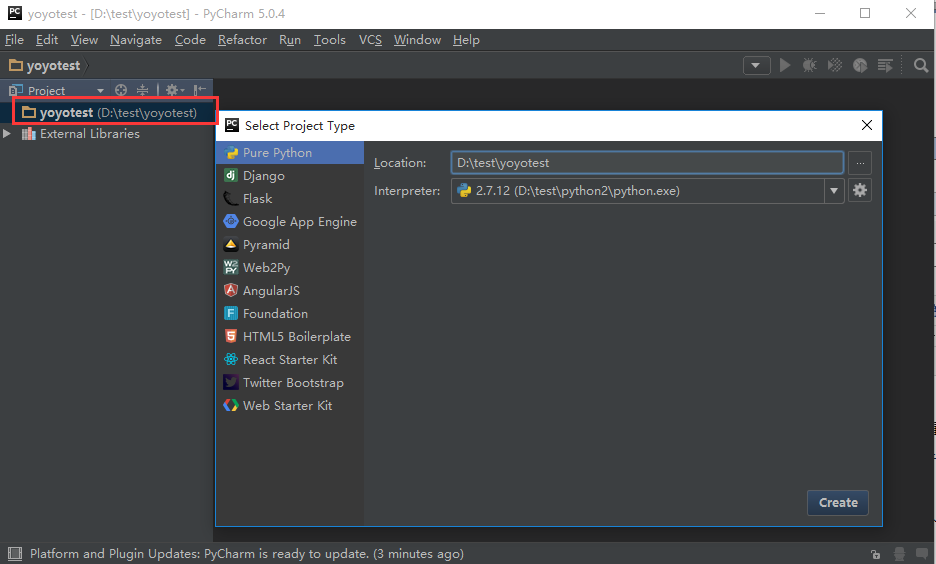
1.pycharm左上角File>New Projetc>Pure Python,在location位置命名一个测试工程的名称:yoyotest,然后保存
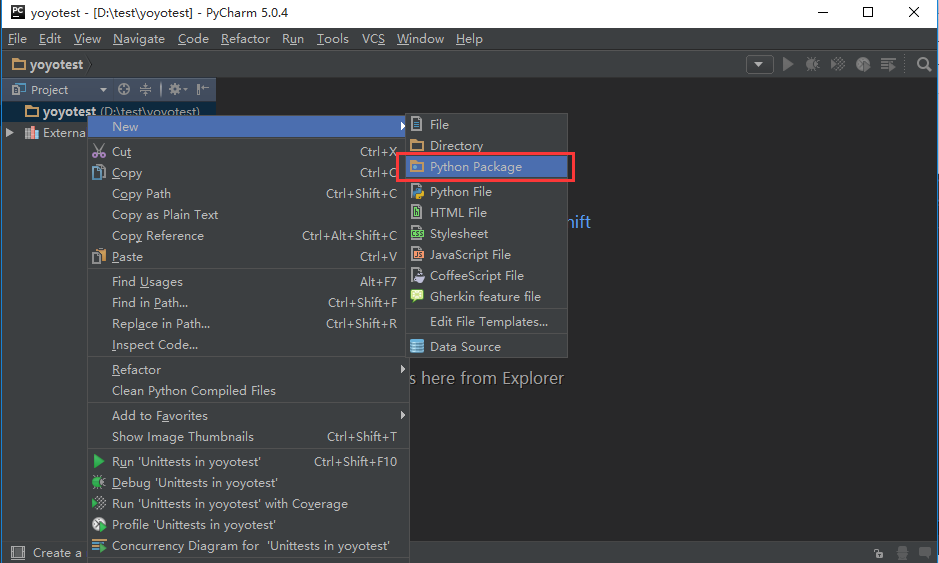
2.选中刚才新建的工程右键>New>Python Package>新建一个case文件夹
3.重复第2步的操作,新建一个case的文件夹,在里面添加一个baidu和一个blog的文件夹,里面分别有两个用例的脚本,如下图所示。
test_01,test_02,test_03,test_04是我们写用例的脚本
4.test_01创建完后,打开脚本,写入用例

5.在yoyotest这个项目下面创建一个脚本run_all_case.py,接下来用这个脚本去批量执行所有的用例。

二、diascover加载测试用例
1.discover方法里面有三个参数:
-case_dir:这个是待执行用例的目录。
-pattern:这个是匹配脚本名称的规则,test*.py意思是匹配test开头的所有脚本。
-top_level_dir:这个是顶层目录的名称,一般默认等于None就行了。
2.discover加载到的用例是一个list集合,需要重新写入到一个list对象testcase里,这样就可以用unittest里面的TextTestRunner这里类的run方法去执行。

3.运行后结果如下,就是加载到的所有测试用例了:
<unittest.suite.TestSuite tests=[<baidu.test_01.Test testMethod=test01>, <baidu.test_01.Test testMethod=test02>, <baidu.test_01.Test testMethod=test03>, <baidu.test_02.Test testMethod=test01>, <baidu.test_02.Test testMethod=test02>, <baidu.test_02.Test testMethod=test03>, <bolg.test_03.Test testMethod=test01>, <bolg.test_03.Test testMethod=test02>, <bolg.test_03.Test testMethod=test03>, <bolg.test_04.Test testMethod=test01>, <bolg.test_04.Test testMethod=test02>, <bolg.test_04.Test testMethod=test03>]>
三、run测试用例
1.为了更方便的理解,可以把上面discover加载用例的方法封装下,写成一个函数

2.参考代码:
# coding:utf-8
import unittest
import os
# 用例路径
case_path = os.path.join(os.getcwd(), "case")
# 报告存放路径
report_path = os.path.join(os.getcwd(), "report")
def all_case():
discover = unittest.defaultTestLoader.discover(case_path,
pattern="test*.py",
top_level_dir=None)
print(discover)
return discover
if __name__ == "__main__":
runner = unittest.TextTestRunner()
runner.run(all_case())
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
觉得对你有帮助,就在右下角点个赞吧,感谢支持!
selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

Selenium2+python自动化53-unittest批量执行(discover)的更多相关文章
- Selenium2+python自动化(unittest)
# coding:utf-8from selenium import webdriverimport unittestimport timeclass Bolg(unittest.TestCase): ...
- Selenium2+python自动化52-unittest执行顺序
前言 很多初学者在使用unittest框架时候,不清楚用例的执行顺序到底是怎样的.对测试类里面的类和方法分不清楚,不知道什么时候执行,什么时候不执行. 本篇通过最简单案例详细讲解unittest执行顺 ...
- Selenium2+python自动化52-unittest执行顺序【转载】
前言 很多初学者在使用unittest框架时候,不清楚用例的执行顺序到底是怎样的.对测试类里面的类和方法分不清楚,不知道什么时候执行,什么时候不执行. 本篇通过最简单案例详细讲解unittest执行顺 ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)【转载】
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- 3.3 unittest批量执行
3.3 unittest批量执行 我们在写用例的时候,单个脚本的用例好执行,那么多个脚本的时候,如何批量执行呢?这时候就需要用到unittet里面的discover方法来加载用例了.加载用例后,用un ...
- Selenium2+python自动化55-unittest之装饰器(@classmethod)
前言 前面讲到unittest里面setUp可以在每次执行用例前执行,这样有效的减少了代码量,但是有个弊端,比如打开浏览器操作,每次执行用例时候都会重新打开,这样就会浪费很多时间. 于是就想是不是可以 ...
- Selenium2+python自动化55-unittest之装饰器(@classmethod)【转载】
前言 前面讲到unittest里面setUp可以在每次执行用例前执行,这样有效的减少了代码量,但是有个弊端,比如打开浏览器操作,每次执行用例时候都会重新打开,这样就会浪费很多时间. 于是就想是不是可以 ...
- Selenium2+python自动化59-数据驱动(ddt)
前言 在设计用例的时候,有些用例只是参数数据的输入不一样,比如登录这个功能,操作过程但是一样的.如果用例重复去写操作过程会增加代码量,对应这种多组数据的测试用例,可以用数据驱动设计模式,一组数据对应一 ...
- Selenium2+python自动化39-关于面试的题
前言 最近看到群里有小伙伴贴出一组面试题,最近又是跳槽黄金季节,小编忍不住抽出一点时间总结了下, 回答不妥的地方欢迎各位高手拍砖指点. 一.selenium中如何判断元素是否存在? 首先selen ...
随机推荐
- CVE-2013-1347Microsoft Internet Explorer 8 远程执行代码漏洞
[CNNVD]Microsoft Internet Explorer 8 远程执行代码漏洞(CNNVD-201305-092) Microsoft Internet Explorer是美国微软(Mic ...
- Spring+Dubbo集成Redis的两种解决方案
当下我们的系统数据库压力都非常大,解决数据库的瓶颈问题势在必行,为了解决数据库的压力等需求,我们常用的是各种缓存,比如redis,本文就来简单讲解一下如何集成redis缓存存储,附github源码. ...
- 宝塔Linux常用命令
https://www.bt.cn/bbs/thread-1186-1-1.html 2017年3月8日发布全新架构的宝塔Linux 面板3.1Beta版,到现在的5.2.0正式版,历经100多天打磨 ...
- C++中bool类型变量初值对程序的影响
很困惑的一个问题 #include<iostream> using namespace std; int main() { //bool a=true; //非0(1,2,3,……)输出1 ...
- Visual Studio Code 常用插件整理
常用插件说明: 一.HTML Snippets 超级使用且初级的H5代码片段以及提示 二.HTML CSS Support 让HTML标签上写class智能提示当前项目所支持的样式 三.Debugg ...
- sicily 1198. Substring (递归全排列+排序)
DescriptionDr lee cuts a string S into N pieces,s[1],…,s[N]. Now, Dr lee gives you these N sub-strin ...
- Asp.net Vnext 中间件实现基本验证
概述 本文已经同步到<Asp.net Vnext 系列教程 >中] vnext 没有 web.config 可以配置基本验证,本文使用中间件实现基本验证 实现 通过Startup(启动类) ...
- easyUI小技巧-纯干货
一.显示分页(pagination:true)情况下,隐藏每页显示的记录条数的那个select(即pageList),下图箭头 方法1:onBeforeLoad:function(param){ ...
- WangSql 3.0源码共享(WangSql 1.0重大升级到3.0)
WangSql 1.0博文阅读: http://www.cnblogs.com/deeround/p/6204610.html 基于1.0做了以下重大改动: 1.多数据实现方式调整 2.使用EmitM ...
- Python全栈开发之14、Javascript
一.简介 前面我们学习了html和css,但是我们写的网页不能动起来,如果我们需要网页出现各种效果,那么我们就要学习一门新的语言了,那就是JavaScript,JavaScript是世界上最流行的脚本 ...