(转)Django配置数据库读写分离
转:https://blog.csdn.net/Ayhan_huang/article/details/78784486
转:http://www.cnblogs.com/dreamer-fish/p/5469141.html
目录
简述
对网站的数据库作读写分离(Read/Write Splitting)可以提高性能,在Django中对此提供了支持,下面我们来简单看一下。注意,还需要运维人员作数据库的读写分离和数据同步。
配置数据库
我们知道在Django项目的settings中,可以配置数据库,除了默认的数据库,我在下面又加了一个db2。因为是演示,我这里用的是默认的SQLite,如果希望用MySQL,看这里 。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db2': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db2.sqlite3'),
创建models并执行数据库迁移
这里我简单创建一张产品表
from django.db import models class Products(models.Model):
"""产品表"""
prod_name = models.CharField(max_length=30)
prod_price = models.DecimalField(max_digits=6, decimal_places=2)
创建完成后,执行数据库迁移操作:
python manage.py makemigrations # 在migrations文件夹下生成记录,迁移前检查
python manage.py migrate # 创建表
#
python manage.py migrate --database default
python manage.py migrate --database db2 # 根据settings里的名称逐个迁移
在migrations文件夹下生成记录,并在迁移前检查是否有问题,默认值检查defualt数据库,但是可以在后面的数据库路由类(Router)中通过allow_migrate()方法来指定是否检查其它的数据库。
其实第二步迁移默认有参数python manage.py migrate --database default ,在默认数据库上创建表。因此完成以上迁移后,执行python manage.py --database db2,再迁移一次,就可以在db2上创建相同的表。这样在项目根目录下,就有了两个表结构一样的数据库,分别是db.sqlite3和db2.sqlite3。
读写分离
手动读写分离
在使用数据库时,通过.using(db_name)来手动指定要使用的数据库
from django.shortcuts import HttpResponse
from . import models def write(request):
models.Products.objects.using('default').create(prod_name='熊猫公仔', prod_price=12.99)
return HttpResponse('写入成功') def read(request):
obj = models.Products.objects.filter(id=1).using('db2').first()
return HttpResponse(obj.prod_name)
自动读写分离
通过配置数据库路由,来自动实现,这样就不需要每次读写都手动指定数据库了。数据库路由中提供了四个方法。这里这里主要用其中的两个:def db_for_read()决定读操作的数据库,def db_for_write()决定写操作的数据库。
定义Router类
新建myrouter.py脚本,定义Router类:
class Router:
def db_for_read(self, model, **hints):
return 'db2' def db_for_write(self, model, **hints):
return 'default'
配置Router
settings.py中指定DATABASE_ROUTERS
DATABASE_ROUTERS = ['myrouter.Router',]
可以指定多个数据库路由,比如对于读操作,Django将会循环所有路由中的db_for_read()方法,直到其中一个有返回值,然后使用这个数据库进行当前操作。
一主多从方案
网站的读的性能通常更重要,因此,可以多配置几个数据库,并在读取时,随机选取,比如:
class Router:
def db_for_read(self, model, **hints):
"""
读取时随机选择一个数据库
"""
import random
return random.choice(['db2', 'db3', 'db4']) def db_for_write(self, model, **hints):
"""
写入时选择主库
"""
return 'default'
分库分表
在大型web项目中,常常会创建多个app来处理不同的业务,如果希望实现app之间的数据库分离,比如app01走数据库db1,app02走数据库
class Router:
def db_for_read(self, model, **hints):
if model._meta.app_label == 'app01':
return 'db1'
if model._meta.app_label == 'app02':
return 'db2' def db_for_write(self, model, **hints):
if model._meta.app_label == 'app01':
return 'db1'
if model._meta.app_label == 'app02':
return 'db2'
例子
别人的例子
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'testly',
'USER': 'root',
'PASSWORD': '',
'HOST':'192.168.1.1',
'PORT':'',
},
'hvdb':{ #配置第二个数据库节点名称
'ENGINE': 'django.db.backends.mysql',
'NAME': 'testdjango', #第二个数据库的名称
'USER': 'root',
'PASSWORD': '',
'HOST':'192.168.1.1',
'PORT':'',
}
}
DATABASE_ROUTERS = ['tt.db_router.app02Router'] #tt为当前项目名称,db_router为上一步编写的db_router.py文件,app02Router为Router
#DATABASE_ROUTERS = ['tt.db_router.app02Router','tt.db_router.app01Router'] #如果定义了多个Router,在此就需要分别指定。注意:这个是有顺序的(先匹配上的规则,就先生效)
settings.py
# -*- coding: UTF-8 -*-
class app02Router(object): #配置app02的路由,去连接hvdb数据库
"""
A router to control all database operations on models in the app02 application.
"""
def db_for_read(self, model, **hints):
"""
Attempts to read app02 models go to hvdb DB.
"""
if model._meta.app_label == 'app02': #app name(如果该app不存在,则无法同步成功)
return 'hvdb' #hvdb为settings中配置的database节点名称,并非db name。dbname为testdjango
return None def db_for_write(self, model, **hints):
"""
Attempts to write app02 models go to hvdb DB.
"""
if model._meta.app_label == 'app02':
return 'hvdb'
return None def allow_relation(self, obj1, obj2, **hints):
"""
Allow relations if a model in the app02 app is involved.
当 obj1 和 obj2 之间允许有关系时返回 True ,不允许时返回 False ,或者没有 意见时返回 None 。
"""
if obj1._meta.app_label == 'app02' or \
obj2._meta.app_label == 'app02':
return True
return None def allow_migrate(self, db, model):
"""
Make sure the app02 app only appears in the hvdb database.
"""
if db == 'hvdb':
return model._meta.app_label == 'app02'
elif model._meta.app_label == 'app02':
return False def allow_syncdb(self, db, model): #决定 model 是否可以和 db 为别名的数据库同步
if db == 'hvdb' or model._meta.app_label == "app02":
return False # we're not using syncdb on our hvdb database
else: # but all other models/databases are fine
return True
return None # class app01Router(object):
# """
# A router to control all database operations on models in the
# aew application.
# """
# def db_for_read(self, model, **hints):
# """
# Attempts to read aew models go to aew DB.
# """
# if model._meta.app_label == 'app01':
# return 'default'
# return None # def db_for_write(self, model, **hints):
# """
# Attempts to write aew models go to aew DB.
# """
# if model._meta.app_label == 'app01':
# return 'default'
# return None # def allow_relation(self, obj1, obj2, **hints):
# """
# Allow relations if a model in the aew app is involved.
# """
# if obj1._meta.app_label == 'app01' or obj2._meta.app_label == 'app01':
# return True
# return None # def allow_migrate(self, db, model):
# """
# Make sure the aew app only appears in the aew database.
# """
# if db == 'default':
# return model._meta.app_label == 'app01'
# elif model._meta.app_label == 'app01':
# return False
# return None
router.py
class tb05(models.Model): #该model使用default数据库
name=models.CharField(max_length=100,primary_key=True,unique=True)
ip=models.GenericIPAddressField()
rating = models.IntegerField() def __str__(self):
return self.name class Meta:
#app_label = 'app01' #由于该model连接default数据库,所以在此无需指定
ordering = ['name'] class tb2(models.Model):
name=models.CharField(max_length=100,primary_key=True,unique=True)
ip=models.GenericIPAddressField()
rating = models.IntegerField() def __str__(self):
return self.name class Meta:
app_label = 'app02'
ordering = ['name']
models.py(app01)
class mtable01(models.Model):
name=models.CharField(max_length=100,primary_key=True,unique=True)
ip=models.GenericIPAddressField()
rating = models.IntegerField() def __str__(self):
return self.name class Meta:
app_label = 'app02' #定义该model的app_label
ordering = ['name'] 使用migrate命令同步数据库: class tb06(models.Model):
name=models.CharField(max_length=100,primary_key=True,unique=True,db_column='mycname') #使用db_column自定义字段名称
ip=models.GenericIPAddressField()
rating = models.IntegerField() def __str__(self):
return self.name class Meta:
db_table = 'mytable' #自定义表名称为mytable
verbose_name = '自定义名称' #指定在admin管理界面中显示的名称
app_label = 'app02'
ordering = ['name']
models.py(app02)
migrate管理命令一次操作一个数据库。默认情况下,它在default 数据库上操作,但是通过提供一个 --database 参数,告诉migrate同步一个不同的数据库。
1)同步default节点数据库,只运行不带 --database参数的命令,不对其他数据库进行同步
python manage.py migrate
python manage.py makemigrations
python manage.py migrate
2)同步hvdb节点数据库:
python manage.py migrate --database=hvdb
python manage.py makemigrations
python manage.py migrate --database=hvdb
结果:
testdjango数据库(hvdb节点)下的app02_mtable01表对应app02下的mtable01模型
testdjango数据库(hvdb节点)下的app02_tb2表对应app01下的tb2模型
testly数据库(default节点)下的app01_tb05表对应app01下的tb05模型

实测
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'review_scrapy_dj',
'USER': 'xxxx',
'PASSWORD': 'xxxx',
'HOST': '1.1.1.39',
'PORT': '',
'CHARSET':'utf8',
"COLLATION":'utf8_general_ci'
},
"slave":{
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db2.sqlite3'),
}
}
DATABASE_ROUTERS = ['utils.myrouter.Router',] # router
settings.py
# -*- coding:utf-8 -*- class Router:
def db_for_read(self, model, **hints):
return 'slave' def db_for_write(self, model, **hints):
return 'default'
utils/myrouter.py
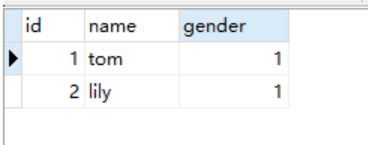
from django.db import models # Create your models here. class UserInfo(models.Model):
name = models.CharField(max_length=64)
gender_choices = [
(0, "男"),
(1, "女"),
]
gender = models.IntegerField(choices=gender_choices,null=True,default=None) class Role(models.Model):
role = models.CharField(max_length=64)
user = models.ManyToManyField(to="UserInfo")
models.py
from django.shortcuts import render,HttpResponse,redirect
from django.views import View
from . import models
# Create your views here.
class Index(View):
def get(self,request):
user_objs_read = models.UserInfo.objects.all()
user_objs_default = models.UserInfo.objects.using("default").all()
gender_choices = models.UserInfo.gender_choices context = {
"user_objs_read":user_objs_read,
"gender_choices":gender_choices,
"user_objs_default":user_objs_default,
} return render(request,"index.html",context=context)
def post(self,request):
name = request.POST.get("name")
print(type(request.POST.get("gender")))
gender = int(request.POST.get("gender"))
models.UserInfo.objects.create(name=name,gender=gender)
return redirect("/test2db/")
views.py
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>index</h1>
<div>
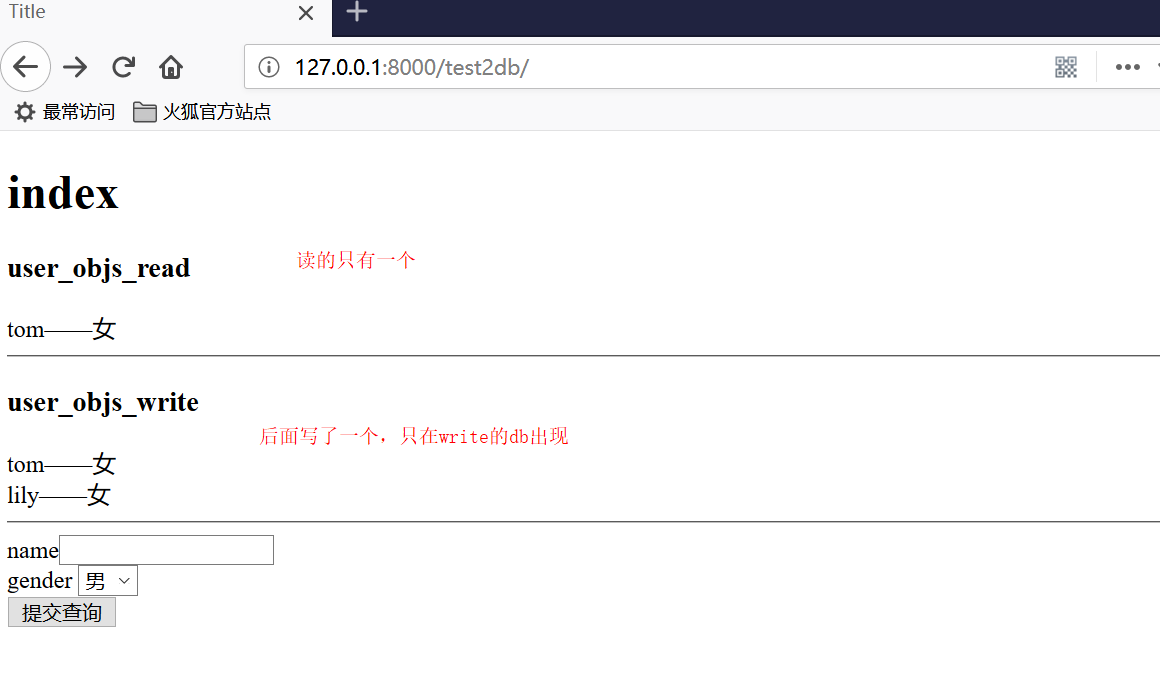
<h3>user_objs_read</h3>
{% for user_obj in user_objs_read %}
<div>{{ user_obj.name }}——{{ user_obj.get_gender_display }}</div>
{% endfor %}
</div>
<hr>
<div>
<h3>user_objs_write</h3>
{% for foo in user_objs_default %}
<div>{{ foo.name }}——{{ foo.get_gender_display }}</div>
{% endfor %}
</div>
<hr>
<form action="" method="post">
{% csrf_token %}
<div>name<input type="text" name="name"></div>
<div>gender
<select name="gender" id="">
{% for gender_choice in gender_choices %}
<option value="{{ gender_choice.0 }}">{{ gender_choice.1 }}</option>
{% endfor %}
</select>
</div>
<input type="submit">
</form> </body>
</html>
index.html

(转)Django配置数据库读写分离的更多相关文章
- Django的数据库读写分离
Django的数据库读写分离 1.首先是配置数据库 在settings.py文件中增加多个数据库的配置: DATABASES = { 'default': { 'ENGINE': 'django.db ...
- 配置Django中数据库读写分离
django在进行数据库操作的时候,读取数据与写数据(曾.删.改)可以分别从不同的数据库进行操作 修改配置文件: DATABASES = { 'default': { 'ENGINE': 'djang ...
- Django----配置数据库读写分离
Django配置数据库读写分离 https://blog.csdn.net/Ayhan_huang/article/details/78784486 https://blog.csdn.net/ayh ...
- django数据库读写分离
django数据库读写分离 1. 配置数据库 settings.py文件中 用SQLite: DATABASES = { 'default': { 'ENGINE': 'django.db.backe ...
- linux中MySQL主从配置(Django实现主从读写分离)
一 linux中MySQL主从配置原理(主从分离,主从同步) mysql主从配置的流程大体如图: 1)master会将变动记录到二进制日志里面: 2)master有一个I/O线程将二进制日志发送到sl ...
- EF架构~通过EF6的DbCommand拦截器来实现数据库读写分离~终结~配置的优化和事务里读写的统一
回到目录 本讲是通过DbCommand拦截器来实现读写分离的最后一讲,对之前几篇文章做了一个优化,无论是程序可读性还是实用性上都有一个提升,在配置信息这块,去除了字符串方式的拼接,取而代之的是sect ...
- yii2的数据库读写分离配置
简介 数据库读写分离是在网站遇到性能瓶颈的时候最先考虑优化的步骤,那么yii2是如何做数据库读写分离的呢?本节教程来给大家普及一下yii2的数据库读写分离配置. 两个服务器的数据同步是读写分离的前提条 ...
- centos MySQL主从配置 ntsysv chkconfig setup命令 配置MySQL 主从 子shell MySQL备份 kill命令 pid文件 discuz!论坛数据库读写分离 双主搭建 mysql.history 第二十九节课
centos MySQL主从配置 ntsysv chkconfig setup命令 配置MySQL 主从 子shell MySQL备份 kill命令 pid文件 discuz!论坛数 ...
- 使用Adivisor配置增强处理,来实现数据库读写分离
一.先写一个demo来概述Adivisor的简单使用步骤 实现步骤: 1.通过MethodBeforeAdivice接口实现前置增强处理 public class ServiceBeforeAdvis ...
随机推荐
- 初识Qt布局管理器
Qt布局管理器的类有4种,它们分别为QHBoxLayout.QVBoxLayout.QGridLayout和QStackLayout.其中,QHBoxLayout实现水平布局,QVBoxLayout实 ...
- ping不通linux服务器排查
很久没启动linux了,今天打开试了下 ssh root@192.168.229.128 ping 一直超时 老规矩挨着来排查 检查网络设备器改为Net 模式 重启网络服务 service netw ...
- 学习笔记·堆优化$\mathscr{dijkstra}$
嘤嘤嘤今天被迫学了这个算法--其实对于学习图论来说我内心是拒绝的\(\mathscr{qnq}\) 由于发现关于这个\(\mathscr{SPFA}\)的时间复杂度\(O(kE)\)中的\(k \ap ...
- sublime 一些常用功能和快捷键
Ctrl+D 选词 (反复按快捷键,即可继续向下同时选中下一个相同的文本进行同时编辑)Ctrl+G 跳转到相应的行Ctrl+J 合并行(已选择需要合并的多行时)Ctrl+L 选择整行(按住-继续选择下 ...
- transform CSS3 2D知识点汇总
transform转换属性的5个值: 1. translate(x值,y值) 移动效果. 2.rotate(45deg) 旋转效果. 3.scale(x轴倍数,y轴倍数) 缩放效果. 4.ske ...
- 查询job的几个语句
select * from dba_jobs ;select * from dba_scheduler_job_run_details t; ------>这个语句通过制定job名,来查看 ...
- sqli-labs学习(less-1-less-4)
学习sqli-labs之前先介绍一些函数,以便于下面的payload看的懂 group_concat函数 将查询出来的多个结果连接成一个字符串结果,用于在一个回显显示多个结果 同理的还有 concat ...
- member access within misaligned address 0x0000002c3931 for type 'struct ListNode‘
From MWeb 在做leetcode 第2题时使用C语言编写链表时报错 错误复现 错误原因 解决办法 错误复现 报错时的代码如下 /** * Definition for singly-linke ...
- Verdi调用VCS进行交互式仿真
前一篇介绍了使用Verdi的后处理模式查看仿真波形进行调试,此外Verdi还支持交互模式,可以调用外部仿真器,下面介绍Verdi调用VCS进行交互模式仿真的方法.注意,这里介绍的方法需要2016版的V ...
- shell重温---基础篇(文件包含)
和其他语言一样,Shell 也可以包含外部脚本.这样可以很方便的封装一些公用的代码作为一个独立的文件.Shell 文件包含的语法格式如下: . filename # 注意点号(.)和文件名中间 ...