hadoop学习笔记(四):HDFS
一、HDFS体系结构
1 HDFS假设条件
数据流访问
大数据集
简单相关模型
移动计算比移动数据便宜
多种软硬件平台中的可移植性
2 HDFS的设计目标
非常巨大的分布式文件系统
运行于普通硬件上
优化批处理
用户控件可以位于异构的操作系统中
在整个集群中使用单一的命名空间
数据一致性
文件被分为各个小块
智能客户端
程序采用“数据就近”原则分配节点执行
客户端对文件没有缓存机制
3 HDFS 架构
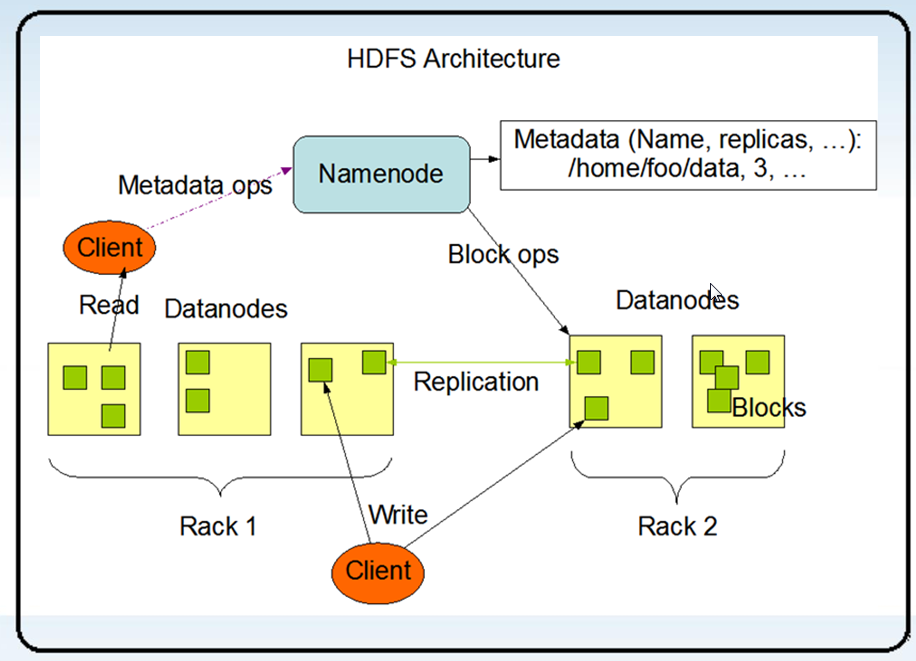
1 HDFS架构-文件
文件被切分为块(默认大小64M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)。
NameNode是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表以及块所在的DataNode等等。
DataNode在本地文件系统存储文件块数据,以及块数据校验和。
可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
2 HDFS文件权限
与 linux文件权限类似。
r:read;w:write;x:execute,权限x对于文件忽略,对于文件夹表示是否允许访问其内容。
如果linux系统用户zhangsan使用hadoop命令创建了一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS权限目的:阻止好人做错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。
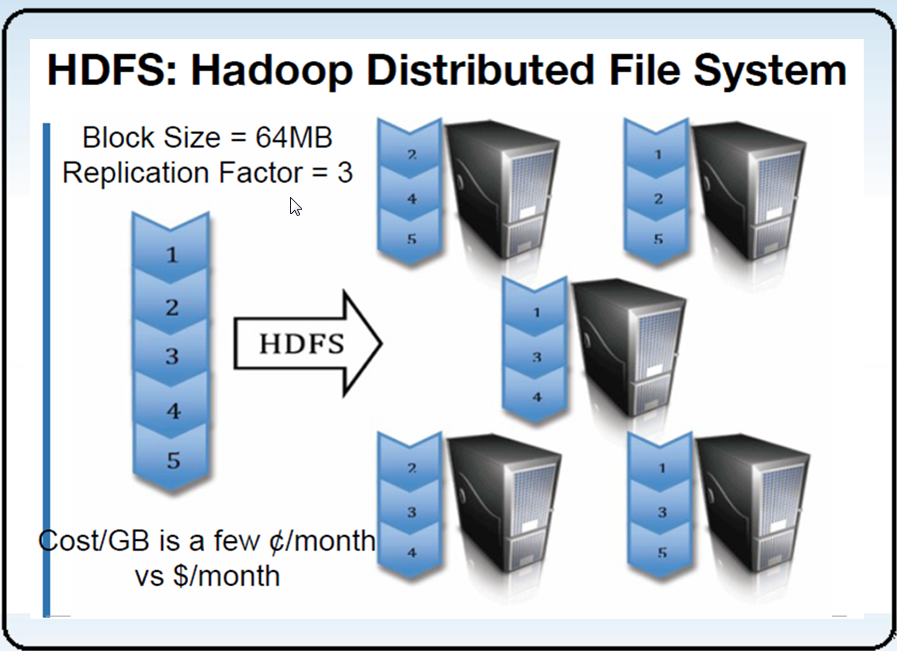
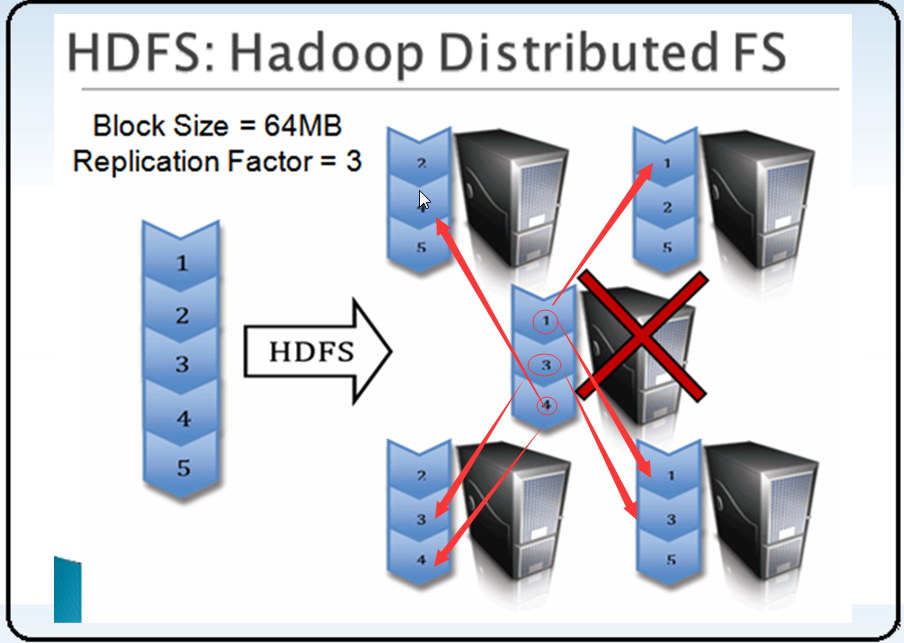
3 HDFS架构-组件功能
| NameNode | DataNode |
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘中 |
| 保存文件、block、DataNode之间的映射关系 | 维护了blockId到DataNode本地文件的映射关系 |
NameNode:
是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
文件操作,NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只会询问跟哪个DataNode的联系,否则NameNode会成为系统瓶颈。
副本存放在哪些DataNode上由NameNode来控制,根据全局情况作出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低带宽消耗和读取延时。
NameNode全权管理数据块的复制,它周期性地从集群中的每一个DataNode接收心跳信号和块状态报告(BlockReport)。接收到心跳信号意味着该DataNode节点工作正常。块状态报告包含了一个该DataNode上所有数据块的列表。
DataNode:
一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
DataNode启动后向NameNode注册,通过后,周期性(1小时)地向NameNode上报所有的块信息。
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
集群运行中可以安全加入和退出一些机器。
4 HDFS副本放置策略
| hadoop 0.17之前 | hadoop 0.17之后 |
| 副本1:同机架的不同节点 | 副本1:同Client的节点上 |
| 副本2:同机架的另一个节点 | 副本2:不同机架中的节点上 |
| 副本3:不同机架的另一个节点 | 副本3:同第二个副本的机架中的另一个节点 |
| 其他副本:随机挑选 | 其他副本:随机挑选 |
5 HDFS数据损坏(corruption)处理
当DataNode读取block的时候,它会计算checksum。
如果计算后的checksum与block创建时值不一样,说明该block已经损坏。
Client读取其他DN上的block。
NameData标记该块已经损坏,然后复制block达到预期设置的文件备份数。
DataNode在其文件创建后三周验证其checksum。
6 HDFS架构-Client&SNN
| Client | Secondary NameNode |
|
文件切分 与NameNode交互,获取文件位置信息 与DataNode交互,读取或写入数据 管理HDFS 访问HDFS |
并非NameNode的热备 辅助NameNode,分担其工作量 定期合并fsimage和fsedits,推送给NameNode 在紧急情况下,可辅助恢复NameNode |
7 HDFS架构-NN&SNN
NameNode两个重要的文件:
fsimage:元数据镜像文件(保存文件系统的目录树)
edits:元数据操作日志(针对目录树的修改操作)
元数据镜像:
内存中保存一份最新的
内存中的镜像=fsimage+edits
定期合并fsimage和edits:
edits文件过大导致NameNode重启速度慢
Secondary NameNode负责定期合并他们
NameNode启动过程与fsimag和edits的变化:
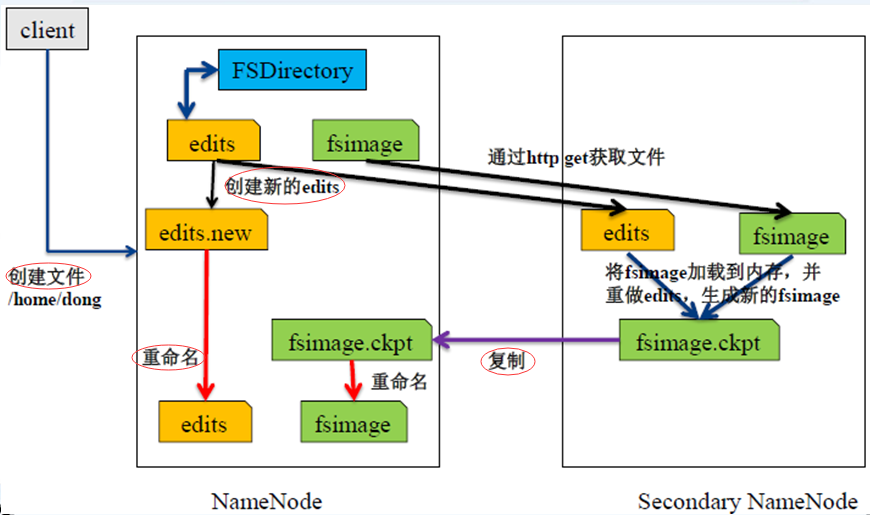
执行过程:
Secondary NN通知NN切换editlog -->
Secondary NN从NN获得fsimage和editlog(通过http方式)-->
Secondary NN将fsimage载入内存,然后开始合并editlog -->
Secondary NN将新的fsimage发回给NN -->
NN用新的fsimage替换旧的fsimage
hadoop学习笔记(四):HDFS的更多相关文章
- Hadoop学习笔记: HDFS
注:该文内容部分来源于ChinaHadoop.cn上的hadoop视频教程. 一. HDFS概述 HDFS即Hadoop Distributed File System, 源于Google发表于200 ...
- Hadoop学习笔记(2)-HDFS的基本操作(Shell命令)
在这里我给大家继续分享一些关于HDFS分布式文件的经验哈,其中包括一些hdfs的基本的shell命令的操作,再加上hdfs java程序设计.在前面我已经写了关于如何去搭建hadoop这样一个大数据平 ...
- Hadoop学习笔记四
一.fsimage,edits和datanode的block在本地文件系统中位置的配置 fsimage:hdfs-site.xml中的dfs.namenode.name.dir 值例如file:// ...
- hadoop学习笔记贰 --HDFS及YARN的启动
1.初始化HDFS :hadoop namenode -format 看到如下字样,说明初始化成功. 启动HDFS,start-dfs.sh 终于启动成功了,原来是core-site.xml 中配置 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- hadoop学习笔记(四)——eclipse+maven+hadoop2.5.2源代码
Eclipse同maven进口hadoop源代码 1) 安装和配置maven环境变量 M2_HOME: D:\profession\hadoop\apache-maven-3.3.3 PATH: % ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- 全自动baidu云盘下载脚本
20141231<吃元宵>孔云龙_6平米.MP3 20141231<家庭论>李云杰_6平米.MP3 20141231<劫皇杠>李昊洋_6平米.MP3 2014123 ...
- Checkpoint--在Tempdb上的特殊性
由于Checkpoint的目的是为减少数据库恢复时间,而每次实例重启都会创建新的tempdb,而不需要恢复,因此checkpoint在Tempdb上行为与其他用户数据库上略微不同. 1. 系统引发的c ...
- Alwayson--工作流程
Alwayson的工作流程: 1. 在主副本上,用户提交数据修改事务,等待服务器返回成功表示: 2. 在主副本上,将事务日志固化(harden),SQL SERVER调用Logwriter线程将事务日 ...
- js实现回车登陆
2018-11-15 $(document).keydown(function (event) { if (event.keyCode == 13) { $("#LoginBtn" ...
- Asp.Net Mvc ScriptBundle 脚本文件捆绑压缩 导致 脚本出错的问题
由于捆绑压缩会对所有包含的文件进行压缩,无法设置忽略对某个js文件的压缩.导致压缩该js后,脚本出错的问题. 解决方式: 重写 ScriptBundle 的 GenerateBundleRespons ...
- Android studio项目预览的时候提示错误ActionBarOverlayLayout
android studio打开项目(别人的demo),提示页面没法预览.截图如下 根据查询,是主题没法正常显示,需要修改样式.样式文件的路径为res\values\styles.xml,截图如下. ...
- K8S+GitLab-自动化分布式部署ASP.NET Core(二) ASP.NET Core DevOps
一.介绍 前一篇,写的K8S部署环境的文章,简单的介绍下DevOps(Development和Operations的组合词),高效交付, 自动化流程,来减少软件开发人员和运维人员的沟通.Martin ...
- 深入理解Aspnet Core之Identity(4)
主题 之前简单介绍了Asp.net core 的初步的使用,本篇我打算给大家介绍一下Identity的架构,让大家对Identity有一个总体的理解和认识. 简介 博客原文欢迎访问我的博客网站,地址是 ...
- VC API常用函数简单例子大全(1-89)
第一个:FindWindow根据窗口类名或窗口标题名来获得窗口的句柄,该函数返回窗口的句柄 函数的定义:HWND WINAPI FindWindow(LPCSTR lpClassName ,LPCST ...
- django模型中, 外键字段使用to_filed属性 指定到所关联主表的某个字段
在django项目的开发过程中,在设计模型时一开始将主键设置成了一个自定义的字段,但是在创建搜索索引时却发现必须要存在一个id的字段,并且为主键(不知道是否是项目一开始就这样配置的原因), 但此时表结 ...