第2节 mapreduce深入学习:6、MapReduce当中的计数器
第2节 mapreduce深入学习:6、 MapReduce当中的计数器
计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助诊断系统故障。如果需要将日志信息传输到map 或reduce 任务, 更好的方法通常是看能否用一个计数器值来记录某一特定事件的发生。对于大型分布式作业而言,使用计数器更为方便。除了因为获取计数器值比输出日志更方便,还有根据计数器值统计特定事件的发生次数要比分析一堆日志文件容易得多。
hadoop内置计数器列表
|
MapReduce任务计数器 |
org.apache.hadoop.mapreduce.TaskCounter |
|
文件系统计数器 |
org.apache.hadoop.mapreduce.FileSystemCounter |
|
FileInputFormat计数器 |
org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
|
FileOutputFormat计数器 |
org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
|
作业计数器 |
org.apache.hadoop.mapreduce.JobCounter |
每次mapreduce执行完成之后,我们都会看到一些日志记录出来,其中最重要的一些日志记录如下截图:
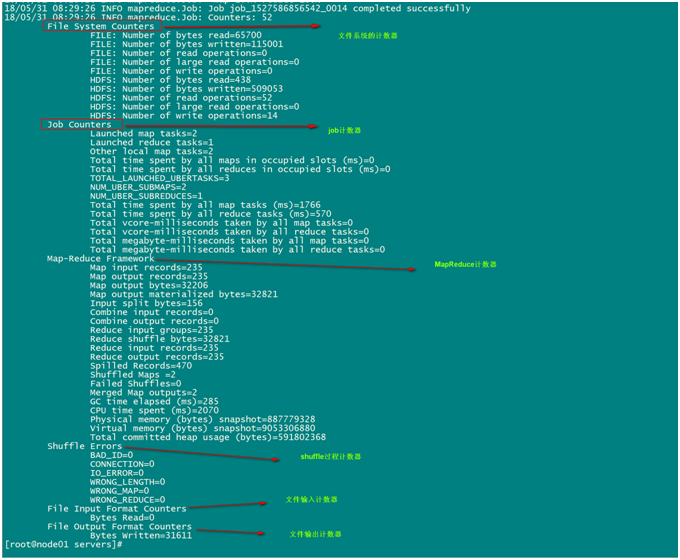
所有的这些都是MapReduce的计数器的功能,既然MapReduce当中有计数器的功能,我们如何实现自己的计数器???
需求1:以上面排序以及序列化为案例,统计map接收到的数据记录条数;需求2:统计reduce端数据的输入的key有多少个,对应的value有多少个。
第一种方式定义计数器,通过context上下文对象可以获取我们的计数器,进行记录。
第二种方式定义计数器,通过enum枚举类型来定义计数器。
详见代码
运行结果:
19/06/14 20:52:37 INFO mapred.JobClient: MAP_COUNTER
19/06/14 20:52:37 INFO mapred.JobClient: MAP_INPUT_RECORDS=8
19/06/14 20:52:37 INFO mapred.JobClient: cn.itcast.demo2.sort.SortReducer$Counter
19/06/14 20:52:37 INFO mapred.JobClient: REDUCE_INPUT_KEY_TOTAL=7
19/06/14 20:52:37 INFO mapred.JobClient: REDUCE_INPUT_VALUE_TOTAL=8
第2节 mapreduce深入学习:6、MapReduce当中的计数器的更多相关文章
- 第2节 mapreduce深入学习:14、mapreduce数据压缩-使用snappy进行压缩
第2节 mapreduce深入学习:14.mapreduce数据压缩-使用snappy进行压缩 文件压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输. 方式一:在代码中进行设置压缩 代码: ...
- 第2节 mapreduce深入学习:8、手机流量汇总求和
第2节 mapreduce深入学习:8.手机流量汇总求和 例子:MapReduce综合练习之上网流量统计. 数据格式参见资料夹 需求一:统计求和 统计每个手机号的上行流量总和,下行流量总和,上行总流量 ...
- 第2节 mapreduce深入学习:7、MapReduce的规约过程combiner
第2节 mapreduce深入学习:7.MapReduce的规约过程combiner 每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次合并,以减少在 ...
- 第2节 mapreduce深入学习:4, 5
第2节 mapreduce深入学习:4.mapreduce的序列化以及自定义排序 序列化(Serialization)是指把结构化对象转化为字节流. 反序列化(Deserialization)是序列化 ...
- 第2节 mapreduce深入学习:2、3
第2节 mapreduce深入学习:2.MapReduce的分区:3.分区案例的补充完成运行实现 在MapReduce中,通过我们指定分区,会将同一个分区的数据发送到同一个reduce当中进行处理,例 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- MapReduce教程(一)基于MapReduce框架开发<转>
1 MapReduce编程 1.1 MapReduce简介 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题. MapReduce分成了两个部分: ...
- Migrating from MapReduce 1 (MRv1) to MapReduce 2 (MRv2, YARN)...
This is a guide to migrating from Apache MapReduce 1 (MRv1) to the Next Generation MapReduce (MRv2 o ...
随机推荐
- [USACO17FEB]Why Did the Cow Cross the Road II
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=4990 [算法] 首先记录b中每个数的出现位置 , 记为P 对于每个ai , 枚举(a ...
- Python3列表、元组、字典、集合的方法
一.列表 温馨提示:对图片点右键——在新标签页中打开图片: 1.count() 定义:统计指定元素在列表中出现的次数并返回这个数.若指定的元素不存在则返回:0. 格式:[列表].count(“指定元素 ...
- Tomcat 在Mac OS X中的安装和配置
简单介绍: 1.Tomcat是目前比较流行的Web应用服务器,它是一个轻量级的应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP程序的首选. 2.Tomcat运行时所 ...
- String类的直接赋值和构造方法赋值的区别
直接赋值:只开辟一块堆内存空间,而且保存的字符串可以自动入池,以供其他内容相同的字符串对象使用. 构造方法:开辟两块堆内存空间,有一块成为垃圾,并且字符串的内容无法自动入池,但是可以使用String类 ...
- bzoj 4071: [Apio2015]巴邻旁之桥【splay】
用权值线段树会容易一些并快一些,但是想复健一下splay所以打了splay 然后果然不会打了. 解题思路: 首先把家和办公室在同一侧的提出来直接加进答案里: 对于k=1,直接选所有办公室和家的中位数即 ...
- 大水题(water)
题目描述dzy 定义一个 $n^2$ 位的数的生成矩阵 $A$ 为一个大小为 $n \times n$ 且 Aij 为这个数的第 $i \times n+j-n$ 位的矩阵.现在 dzy 有一个数 $ ...
- 5 分钟掌握 JS 实用窍门技巧,帮你快速撸码--- 删除数组尾部元素、E6对象解构、async/await、 操作平铺嵌套多维数组等
1. 删除数组尾部元素 一个简单方法就是改变数组的length值: const arr = [11, 22, 33, 44, 55, 66]; arr.length = 3; console.log( ...
- 《windows核心编程系列》四谈谈进程的建立和终止
第二部分:工作机理 第一章:进程 上一章介绍了内核对象,这一节开始就要不断接触各种内核对象了.首先要给大家介绍的是进程内核对象.进程大家都不陌生,它是资源和分配的基本单位,而进程内核对象就是与进程相关 ...
- python优缺点分析及python种类
Python的缺点: 相较于其它类型的语言可能运行速度上会略差.C语言的运行性能速度上最好,因为C最接近计算机底层. Python的优点: 大数据处理,有专门的功能模块,比较方便. Linux自带Py ...
- 官方XmlPullParser和网络解析xml示例及详述
Parsing XML Data This lesson teaches you to Choose a Parser Analyze the Feed Instantiate the Parser ...