YOLOv3模型识别车位图片的测试报告(节选)
1,YOLOv3模型简介
YOLO能实现图像或视频中物体的快速识别。在相同的识别类别范围和识别准确率条件下,YOLO识别速度最快。
官网:https://pjreddie.com/darknet/yolo/
知乎:https://zhuanlan.zhihu.com/p/25236464
YOLO有多种模型,包括V1,V2,V3,其中V3识别准确率最高,但对硬件要求也高。还有tiny模型。也可针对特定识别物体类别进行训练,获得应用需要的专用模型。
本次测试采用V3模型。对实际车场图片进行批量检测,对检测结果进行分析,重点是车位中的车辆能否得到正确识别,以探讨YOLO V3模型应用于车场车位状态检测中的可行性。
2,测试环境
|
操作系统 |
Windows7 64位 |
|
|
Cpu |
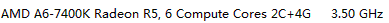 |
|
|
Gpu |
0 |
|
|
内存 |
4GB |
|
|
输入图片的数量和规格 |
2019张,960*1280 |
|
|
运行时间 |
2018-05-23 18:03~~2018-05-24 05:01 |
|
|
执行文件 |
||
|
检测模型 |
YOLO v3 |
|
|
物体检测阈值 |
置信度 > 0.25 |
|
|
物体分类模型 |
80种,与车位车辆相关的4种(car, motorbike, truck, bus)。详见coco.names |
3,测试数据和结果
|
运行总时间 |
11小时 |
|
|
平均每张图片的分析时间 |
20秒 |
|
|
分析后输出的图片包 |
YOLO对车位图片的检测结果.rar |
|
|
分析输出文字信息 |
||
|
车位图片输出结果分析 |
识别错误类别统计:
|
错误类别编号 |
错误类别 |
数量 |
比例 |
备注 |
|
1 |
识别到周围停有车辆,因而判断有车 |
118 |
此问题与YOLO算法无关 |
|
|
2 |
未识别出相机识别车位上的车辆 |
74 |
3.66% |
2类错误的文件已打包在文件2类错误.rar |
|
3 |
镜头范围过小,车辆无法体现特征 |
1 |
此问题与YOLO算法无关 |
|
|
4 |
图像变形 |
1 |
此问题与YOLO算法无关 |
|
|
5 |
在无车位置上错误标注 |
6 |
0.3% |
5类错误的文件已打包在文件5类错误.rar |
综上所述,本次测试错误率为3.96%。效果还是令人基本满意的。
4,测试分析
4.1 YOLOv3静态车位图片检测优势
总体来说,识别车辆准确,适应强。具体表现如下:
² 对于多车不会漏检
² 面向镜头的无论是车头、车尾还是车身都能检测到。
² 特种车辆也能识别。
² 只出现一部分的车身也能检测到。但也要看是否能体现车辆特征
² 光线强弱对检测影响不大。
² 强大的物体检测能力,不仅限于车辆检测。
以下具体示例略。
4.2 YOLOv3静态车位图片检测存在的问题
测试中发现的问题可以归纳为以下几类:
² 存在漏检。某些明显的车辆未能检测到
² 在全域范围内能检测到的车辆,区域裁剪后可能导致检测不到
² 同一物体可能检测出多种类别或多台车检测成1台
² 车辆错误识别为其它种类
² 空车位错误识别为车辆
以下具体示例略。
5,后续计划
对于车位车辆的识别,如果速度和准确度达到实用程度,那么可用于简易停车场的车位调度。
如果结合人脸识别或车牌识别,也能做到反向寻车。
也可应用于路边停车,可将车辆进入停车区和离开停车区的信息及时上报。
目前关键还是将车辆识别做到又好又快。以下为思路:
略。
YOLOv3模型识别车位图片的测试报告(节选)的更多相关文章
- yolov3输出检测图片位置信息
前言 我们在进行图片识别后需要进行进一步的处理,该文章会介绍:1.怎样取消lables;2.输出并保存(.txt)标记框的位置信息 一.去掉label 在darknet/src/image.c 收索d ...
- yolov3和ssd的区别
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/BlowfishKing/article/d ...
- YOLOv1到YOLOv3的演变过程及每个算法详解
1,YOLOv1算法的简介 YOLO算法使用深度神经网络进行对象的位置检测以及分类,主要的特点是速度够快,而且准确率也很高,采用直接预测目标对象的边界框的方法,将候选区和对象识别这两个阶段合二为一, ...
- AI应用开发实战 - 定制化视觉服务的使用
AI应用开发实战 - 定制化视觉服务的使用 本篇教程的目标是学会使用定制化视觉服务,并能在UWP应用中集成定制化视觉服务模型. 前一篇:AI应用开发实战 - 手写识别应用入门 建议和反馈,请发送到 h ...
- KNN算法案例--手写数字识别
import numpy as np import matplotlib .pyplot as plt import pandas as pd from sklearn.neighbors impor ...
- [2] LabelImg图片标注 与 YOLOv3 网络训练 (待补充)
LabelImg是一个图形图像注释工具. 它是用Python编写的,并使用Qt作为其图形界面. 注释以PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式.Besdies,它也支持 ...
- Jmeter 发测试报告到邮箱,expand/collapse 图片不显示
由于发送到邮箱中html文件是不包含expand/collapse 资源文件的,所以导致邮箱中这两个图片没有显示,解决方法有两种: 1. 使用http能访问的图片链接地址 修改change中的图片资源 ...
- ReportNg 测试报告的定制修改【转】
前言 前段时间在Testerhome上面看到了测试报告生成系列之-------如何用 testNG 生成测试报告 简单的描述了一些测试报告的生成,接着有人在评论中回复说可以针对reportNg的测试报 ...
- (引用 )自动化测试报告HTMLtestrunner
1>下载HTMLTestRunner.py文件,地址为: http://tungwaiyip.info/software/HTMLTestRunner.html Windows平台: 将下载 ...
随机推荐
- 访问某类型的元数据的方式-TypeDescriptor 类
.NET Framework 提供了两种访问某类型的元数据的方式:通过 System.Reflection 命名空间中提供的反射 API,以及通过 TypeDescriptor 类.反射是可用于所有类 ...
- Chapter1-data access reloaded:Entity Framework(上)
本章包括以下几个部分: 1.DataSet and classic ADO.NET approach2.Object model approach3.Object/relational mismatc ...
- bash builtin eval
1 在开始执行eval后面的命令之前eval主要做了哪些事情 1.1 去掉反斜杠的quoting 比如\$ac_optarg,会变成$ac_optarg. 1.2 去掉单引号的quoting 比如: ...
- 移动端和PC端有什么区别
1.PC考虑的是浏览器的兼容性,而移动端开发考虑的更多的是手机兼容性,因为目前不管是android手机还是ios手机,一般浏览器使用的都是webkit内核,所以说做移动端开发,更多考虑的应该是手机分辨 ...
- BZOJ1266:上学路线route (最短路+最小割)
可可和卡卡家住合肥市的东郊,每天上学他们都要转车多次才能到达市区西端的学校.直到有一天他们两人参加了学校的信息学奥林匹克竞赛小组才发现每天上学的乘车路线不一定是最优的. 可可:“很可能我们在上学的路途 ...
- Linux中的工作队列
工作队列(work queue)是Linux kernel中将工作推后执行的一种机制.这种机制和BH或Tasklets不同之处在于工作队列是把推后的工作交由一个内核线程去执行,因此工作队列的优势就在于 ...
- Pimple研究及PHP框架搭建
此文参考PHP容器--Pimple运行流程浅析 和 利用 Composer 一步一步构建自己的 PHP 框架,如有不清楚的,请参考原文. Pimple貌似在PHP社区里非常流行,听闻是个非常轻量化并且 ...
- bzoj 1089: [SCOI2003]严格n元树【dp+高精】
设f[i]为深度为i的n元树数目,s为f的前缀和 s[i]=s[i-1]^n+1,就是增加一个根,然后在下面挂n个子树,每个子树都有s[i-1]种 写个高精就行了,好久没写WA了好几次-- #incl ...
- bzoj 2508: 简单题【拉格朗日乘数法】
大概是对于f(x,y)求min,先把x看成常数,然后得到关于y的一元二次方程,然后取一元二次极值把y用x表示,再把x作为未知数带回去化简,最后能得到一个一元二次的式子,每次修改这个式子的参数即可. 智 ...
- Survival on the Titanic (泰坦尼克号生存预测)
>> Score 最近用随机森林玩了 Kaggle 的泰坦尼克号项目,顺便记录一下. Kaggle - Titanic: Machine Learning from Disaster On ...