kesci---2019大数据挑战赛预选赛---情感分析
一、预选赛题------文本情感分类模型
本预选赛要求选手建立文本情感分类模型,选手用训练好的模型对测试集中的文本情感进行预测,判断其情感为「Negative」或者「Positive」。所提交的结果按照指定的评价指标使用在线评测数据进行评测,达到或超过规定的分数线即通过预选赛。
二、比赛数据
训练集数据:(6328个样本)

测试集数据(2712个样本)

评价方法:AUC
三、分析
1、加载模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.feature_extraction.text import TfidfTransformer,TfidfVectorizer
2、数据读取
train_data = pd.read_csv('./data/train.csv',engine = 'python')
test_data = pd.read_csv('./data/20190520_test.csv')
3、数据预处理
test_data.info() ###可以看到有5个缺失值。
###缺失值处理
train_data = train_data.dropna (axis=0,subset = ['label'])
###标签数据处理,label转成(0,1)
train_data['label'] = train_data['label'].replace(to_replace=['Positive', 'Negative'], value=[0, 1])
###评论数据处理
1、去除一些【标点符号、数字、特殊符号、等】
2、分词,去除句子的空格前缀(strip),单词最小化(lower)
3、去除一些【短词】和【停用词】,大多数太短的词起不到什么作用,比如‘pdx’,‘his’,‘all’。
4、提取词干,将不同但同义的词转化成相同的词,如loves,loving,lovable变成love
###评论数据处理
def filter_fun(line):
#表示将data中的除了大小写字母之外的符号换成空格,去除一些标点符号、特征符号、数字等
line = re.sub(r'[^a-zA-Z]',' ',line)
##单词小写化
line = line.lower()
return line train_data['review'] = train_data['review'].apply(filter_fun)
test_data['review'] = test_data['review'].apply(filter_fun)
##把空格前缀去除
train_data['review'] = train_data['review'].str.strip()
test_data['review'] = test_data['review'].str.strip() ##删除短单词
train_data['review'] = train_data['review'].apply(lambda x:' '.join([w for w in x.split() if len(w) > 3]))
test_data['review'] = test_data['review'].apply(lambda x:' '.join([w for w in x.split() if len(w) > 3])) ##分词
train_data['review'] = train_data['review'].str.split()
test_data['review'] = test_data['review'].str.split()
##提取词干,即基于规则从单词中去除后缀的过程。例如,play,player,played,plays,playing都是play的变种。
from nltk.stem.porter import *
stemmer =PorterStemmer()
train_data['review'] = train_data['review'].apply(lambda x: [stemmer.stem(i) for i in x])
test_data['review'] = test_data['review'].apply(lambda x: [stemmer.stem(i) for i in x]) train_data['review'] = train_data['review'].apply(lambda x:" ".join(x))
test_data['review'] = test_data['review'].apply(lambda x:" ".join(x))
########################以下部分可以不处理##################
3、数据分析
在这次比赛中数据分析没起什么作用,因为评论做了脱敏处理。
####################################
1、数据集中最常见的单词有哪些?【可采用词云】
2、数据集上表述积极和消极的常见词汇有哪些?【可采用词云】
3、评论一般有多少主题标签?
4、我的数据集跟哪些趋势相关?
5、哪些趋势跟情绪相关?他们和情绪是吻合的吗?
6、词长与频次的关系【画柱状图,此次代码中平均词长为15】
#使用 词云 来了解评论中最常用的词汇
all_words = ' '.join([text for text in combi['review']])
from wordcloud import WordCloud
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(all_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show()

# 积极数据
positive_words =' '.join([text for text in combi['review'][combi['label'] == 0]])
wordcloud = WordCloud(width=800, height=500, random_state=21, max_font_size=110).generate(positive_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show() # 消极数据
negative_words = ' '.join([text for text in combi['review'][combi['label'] == 1]])
wordcloud = WordCloud(width=800, height=500,random_state=21, max_font_size=110).generate(negative_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.show() def hashtag_extract(x):
hashtags = [] # Loop over the words in the tweet
for i in x:
ht = re.findall(r"#(\w+)", i)
hashtags.append(ht)
return hashtags # extracting hashtags from non racist/sexist tweets
HT_positive = hashtag_extract(combi['review'][combi['label'] == 0])
# extracting hashtags from racist/sexist tweets
HT_negative = hashtag_extract(combi['review'][combi['label'] == 1])
# unnesting list
HT_positive = sum(HT_positive,[])
HT_negative = sum(HT_negative,[]) # 画积极标签
a = nltk.FreqDist(HT_positive)
d = pd.DataFrame({'Hashtag': list(a.keys()),'Count': list(a.values())})
# selecting top 10 most frequent hashtags
d = d.nlargest(columns="Count", n = 10)
#前十
plt.figure(figsize=(16,5))
ax = sns.barplot(data=d, x= "Hashtag", y = "Count")
ax.set(ylabel = 'Count')
plt.show() # 画消极标签
b = nltk.FreqDist(HT_negative)
e = pd.DataFrame({'Hashtag': list(b.keys()),'Count': list(b.values())})
# selecting top 10 most frequent
hashtagse = e.nlargest(columns="Count", n = 10)
plt.figure(figsize=(16,5))
ax = sns.barplot(data=e, x= "Hashtag", y = "Count")
ax.set(ylabel = 'Count')
plt.show()

##数据分析
def split_word(s):
return len(s.split())
train_data['word_length'] = train_data['review'].apply(split_word)
sum_len , nums ,maxnum , minnum = sum(train_data['word_length']) , len(train_data['word_length']) , max(train_data['word_length']) ,min(train_data['word_length'])
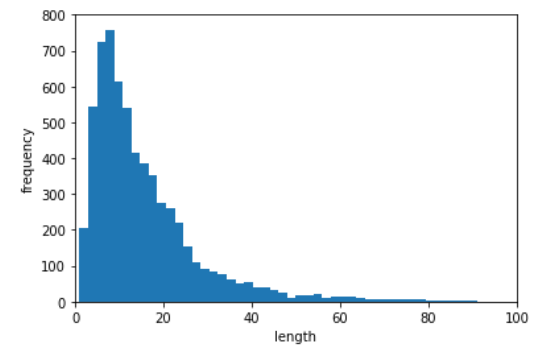
print("all words number: {0} , mean word length : {1} ,max word length: {2} and min: {3} ".format(sum_len , sum_len // nums , maxnum,minnum)) ##评论词长---频次
plt.xlabel('length')
plt.ylabel('frequency')
plt.hist(train_data['word_length'],bins = 150)
plt.axis([0,100,0,800])
plt.show()
#######################################################3
4、模型
训练模型----两部分(文本特征提取、文本分类)
1、文本特征提取:词袋模型、TF_IDF、word_embbeding
2、文本分类:逻辑回归、SVM、贝叶斯、LSTM、textCNN等 【在这次预选赛中,效果最好的是 TF_IDF + 贝叶斯 ----0.86】
【试了 词袋模型 + LR 和 TF_IDF + LR(这两种效果最差)、词袋模型 + 贝叶斯 (效果一般)----0.84、TF_IDF + 贝叶斯(效果最好)】
(1)文本特征提取:
①词袋模型
#构建词袋模型
from sklearn.feature_extraction.text import CountVectorizer
bow_vectorizer = CountVectorizer(max_df=0.30, max_features=8200, stop_words='english')
X_train = bow_vectorizer.fit_transform(train_data['review'])
X_test = bow_vectorizer.fit_transform(test_data['review'])
print(test_data.describe())
print(X_train.toarray())
②TF-IDF模型
#####TF-IDF模型
ngram = 2
vectorizer = TfidfVectorizer(sublinear_tf=True,ngram_range=(1, ngram), max_df=0.5) X_all = train_data['review'].values.tolist() + test_data['review'].values.tolist() # Combine both to fit the TFIDF vectorization.
lentrain = len(train_data) vectorizer.fit(X_all)
X_all = vectorizer.transform(X_all) X_train = X_all[:lentrain] # Separate back into training and test sets.
X_test = X_all[lentrain:]
(2)文本分类模型
①逻辑回归
# 逻辑回归构建模型 #切分训练集和测试集
# xtrain_bow, xvalid_bow, ytrain, yvalid = train_test_split(X_train, train_data['label'], random_state=42, test_size=0.3)
X_train_part,X_test_part,y_train_part,y_test_part = train_test_split(X_train,train_data['label'],test_size = 0.2)
# 使用词袋模型特征集合构建模型 lreg = LogisticRegression()
lreg.fit(X_train_part, y_train_part)
prediction = lreg.predict_proba(X_test_part)
# predicting on the validation set
prediction_int = prediction[:,1] >= 0.3
prediction_int = prediction_int.astype(np.int)
print("回归f",f1_score(y_test_part, prediction_int)) # calculating f1 score
fpr, tpr, thresholds = roc_curve(y_test_part, prediction_int)
print('回归auc',auc(fpr, tpr)) test_pred = lreg.predict_proba(X_test) print("这里P:",test_pred)
保存测试结果
print(test_pred.size)
test_pred_int = test_pred[:,1] #提取我们需要预测的test的label列
print(test_pred_int.size) #看看进过模型预测后的长度是否有变化
print(pd.DataFrame(test_data,columns=["ID"]).size) #看看原始test的数据列有多少 test_data['Pred'] = test_pred_int
submission = test_data[['ID','Pred']]
submission.to_csv('./result.csv', index=False) # writing data to a CSV file
②贝叶斯模型
from sklearn.model_selection import train_test_split,KFold
#from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB,BernoulliNB,MultinomialNB
from sklearn.metrics import roc_auc_score,auc,roc_curve
#from sklearn.svm import SVC
#import xgboost as xgb X_train_part,X_test_part,y_train_part,y_test_part = train_test_split(X_train,train_data['label'],test_size = 0.2) clf = MultinomialNB()
clf.fit(X_train_part,y_train_part) y_pred = clf.predict_proba(X_train_part)
fpr, tpr, thresholds = roc_curve(y_train_part, y_pred[:,1])
auc(fpr, tpr) ###0.9992496306904572 y_pred = clf.predict_proba(X_test_part)
fpr, tpr, thresholds = roc_curve(y_test_part, y_pred[:,1])
auc(fpr, tpr) ###0.8613719824212871
clf = MultinomialNB() clf.fit(X_train,train_data['label']) y_pred_text = clf.predict_proba(X_test) ##保存测试结果 submit = pd.DataFrame() submit['ID'] = test['ID'] submit['Pred'] = y_pred_text[:,1] submit.to_csv('submit_bayes_2.csv',index=False)
参考:https://blog.csdn.net/Strawberry_595/article/details/90205761
kesci---2019大数据挑战赛预选赛---情感分析的更多相关文章
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
转自:http://www.36dsj.com/archives/28590 Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分 ...
- 零起点PYTHON足彩大数据与机器学习实盘分析
零起点PYTHON足彩大数据与机器学习实盘分析 第1章 足彩与数据分析 1 1.1 “阿尔法狗”与足彩 1 1.2 案例1-1:可怕的英国足球 3 1.3 关于足彩的几个误区 7 1.4 足彩·大事件 ...
- MaxCompute 最新特性介绍 | 2019大数据技术公开课第三季
摘要:距离上一次MaxCompute新功能的线上发布已经过去了大约一个季度的时间,而在这一段时间里,MaxCompute不断地在增加新的功能和特性,比如参数化视图.UDF支持动态参数.支持分区裁剪.生 ...
- 从 Apache ORC 到 Apache Calcite | 2019大数据技术公开课第一季《技术人生专访》
摘要: 什么是Apache ORC开源项目?主流的开源列存格式ORC和Parquet有何区别?MaxCompute为什么选择ORC? 如何一步步成为committer和加入PMC的?在阿里和Uber总 ...
- Oracle大数据量查询实际分析
Oracle数据库: 刚做一张5000万条数据的数据抽取,当前表同时还在继续insert操作,每分钟几百条数据. 该表按照时间,以月份为单位做的表分区,没有任何索引,当前共有14个字段,平均每个字段3 ...
- Python大数据:信用卡逾期分析
# -*- coding:utf-8 -*- # 数据集成 import csv import numpy as np import pandas as pd import matplotlib.py ...
- 大数据江湖之即席查询与分析(下篇)--手把手教你搭建即席查询与分析Demo
上篇小弟分享了几个“即席查询与分析”的典型案例,引起了不少共鸣,好多小伙伴迫不及待地追问我们:说好的“手把手教你搭建即席查询与分析Demo”啥时候能出?说到就得做到,差啥不能差人品,本篇只分享技术干货 ...
- chinacloud大数据新闻
2015年大数据发展八大趋势 (0 篇回复) “数据很丰满,信息很骨感”:Sight Machine想用大数据的方法,打碎两者间的屏障 (0 篇回复) 百度携大数据"圈地" ...
- 追本溯源 解析“大数据生态环境”发展现状(CSDN)
程学旗先生是中科院计算所副总工.研究员.博士生导师.网络科学与技术重点实验室主任.本次程学旗带来了中国大数据生态系统的基础问题方面的内容分享.大数据的发展越来越快,但是对于大数据的认知大都还停留在最初 ...
随机推荐
- iOS中的成员变量,实例变量,属性变量
在ios第一版中: 我们为输出口同时声明了属性和底层实例变量,那时,属性是oc语言的一个新的机制,并且要求你必须声明与之对应的实例变量,例如: 注意:(这个是以前的用法) @interface MyV ...
- 在SAE搭建Python+Django+MySQL(基于Windows)
为了与时俱进,工作闲余開始研究Python,刚一接触就被Python这"优雅"的语法吸引住.后来接触到了Django.尽管还没有太深入的研究.但对这样的新概念的WEB开发非常感兴趣 ...
- Apache 配置学习占位
http://www.cnblogs.com/yeer/archive/2011/01/18/1938024.html http://www.cnblogs.com/zgx/archive/2011/ ...
- web的自己主动化公布
</pre>基于眼下业务的版本号.使用的maven 及tomcat <p></p><p>假设我们使用 Jenkins 公布是比較好的,可是存在一定的问题 ...
- HDU4689Derangement (动态规划)
题目链接:传送门 题意: 对于一个由1~n组成的长度为n的序列来说它有n!种排法.我们定义初始的排列为1,2,3,...,n对于兴许的排列假设a[i]>i则用'+'表示.a[i]<i用'- ...
- bzoj1833
http://www.lydsy.com/JudgeOnline/problem.php?id=1833 2.5个小时就花在这上面了... 水到200题了...然并卵,天天做水题有什么前途... #i ...
- PCB CE工具取Genesis JOB与STEP内存地址 方法分享
今天无意中在硬盘上找到了<CE工具取Genesis JOB与STEP内存地址 >视频, 这是2013年初由郭兄(永明)远程时录制的一段视频,特别感谢郭兄指引与帮助, 想当初要不是你推出全行 ...
- windows2003下svn的安装
Windows2003下svn平台搭建 编辑:dnawo 日期:2010-08-03 转自http://www.mzwu.com/article.asp?id=2557 字体大小: 小 中 大 ...
- [Swift通天遁地]三、手势与图表-(10)创建包含圆点、方形、三角形图标的散点图表
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- Git 迁库 标签
Git迁库 (一)克隆裸库 git clone --bare https://github.com/SunArmy/Tourist.git 克隆之后进入该目录下是这样的 (二)创建新的版本库 这里我已 ...