ML一些零散记录
- 朴素贝叶斯的假定条件:变量独立同分布
- 一般情况下,越复杂的系统,过拟合的可能性就越高,一般模型相对简单的话泛化能力会更好一点,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向, svm高斯核函数比线性核函数模型更复杂,容易过拟合
- AdaBoost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被凸显出来,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。以此类推,将所有的弱分类器重叠加起来,得到强分类器。
Bagging与Boosting的区别主要是取样方式不同:Bagging采用均匀取样,而Boosting根据错误率取样。Bagging的各个预测函数没有权重,而Boosting是有权重的。Bagging的各个预测函数可以并行生成,而Boosing的各个预测函数只能顺序生成。
- 神经网络学习过程的本质就是学习数据分布,在训练数据与测试数据分布不同情况下,模型的泛化能力就大大降低;另一方面,若训练过程中每批batch的数据分布也各不相同,那么网络每批迭代学习过程也会出现较大波动,使之更难趋于收敛,降低训练收敛速度。通常在输入层做标准化/归一化并不能保证每次minibatch通过每个层的输入数据都是均值0方差1,因此我们可以加一个batch normalization层对这个minibatch的数据进行处理。但是这样也带来一个问题,把某个层的输出限制在均值为0方差为1的分布会使得网络的表达能力变弱。因此又给batch normalization层进行一些限制的放松,给它增加两个可学习的参数 β 和 γ ,对数据进行缩放和平移,平移参数 β 和缩放参数 γ 是学习出来的。极端的情况这两个参数等于mini-batch的均值和方差,那么经过batch normalization之后的数据和输入完全一样,当然一般的情况是不同的。Batch normalization输出计算的统计量会受到batch中其他样本的影响(对一个batch里所有的图片的所有像素求均值和标准差。而instance norm是对单个图片的所有像素求均值和标准差)由于shuffle的存在,每个batch里每次的均值和标准差是不稳定,本身相当于是引入了噪声。而instance norm的信息都是来自于自身的图片,某个角度来说,可以看作是全局信息的一次整合和调整。对于训练也说也是更稳定的一种方法。在RNN里面(看hinton的layer normalization想到的), 超分辨率或者对图像对比度、亮度等有要求的时候不建议使用BN。

- 生成模型是通过联合概率分布来求条件概率分布,而判别模型是通过数据直接求出条件概率分布,换句话说也就是,生成模型学习了所有数据的特点(更宽泛,更普适),判别模型则只是找出分界(更狭隘 更特殊)。
判别模型求解的思路是:条件分布------>模型参数后验概率最大------->(似然函数参数先验)最大------->最大似然
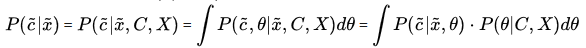 即为求条件分布的参数
即为求条件分布的参数关于训练数据(C,X)的后验分布
生成模型的求解思路是:联合分布------->求解类别先验概率和类别条件概率

常见的判别式模型有:
- Logistic regression(logistical 回归)
- Linear discriminant analysis(线性判别分析)
- Supportvector machines(支持向量机)
- Boosting(集成学习)
- Conditional random fields(条件随机场)
- Linear regression(线性回归)
- Neural networks(神经网络)
常见的生成式模型有:
- Gaussian mixture model and othertypes of mixture model(高斯混合及其他类型混合模型)
- Hidden Markov model(隐马尔可夫)
- NaiveBayes(朴素贝叶斯)
- AODE(平均单依赖估计)
- Latent Dirichlet allocation(LDA主题模型)
- Restricted Boltzmann Machine(限制波兹曼机)
- 联合概率公式:$p(x,y) = p(x|y)p(y) = p(y|x)p(x)$,若x,y独立,则公式退化为$p(x,y) = p(x)p(y)$
- 从联合概率公式可以推导出条件概率公式:$p(x|y) = p(x,y)/p(y)$ $p(y|x) = p(x,y)/p(x)$
- 全概率公式:$p(x)=\sum_{m=1}^Mp(x|y_m)p(y_m)$,其中$\sum_{m=1}^Mp(y_m)=1$
- 贝叶斯(后验概率)公式:$p(y_m|x) = p(y_m,x)/p(x) = p(x|y_m)p(y_m)/\sum_{m=1}^Mp(x|y_m)p(y_m)$
$p(y_m|x)$:后验概率
$p(x|y_m)$:先验概率
$p(y_m)$:似然函数
$sum_{m=1}^Mp(x|y_m)p(y_m) = p(x)$:证据因子

ML一些零散记录的更多相关文章
- C++细节系列(零):零散记录
老规矩:记录细节,等待空余,再进行整理. 1:const,static,const static成员初始化. 1.const成员:只能在构造函数后的初始化列表中初始化 2.static成员:初始化在类 ...
- C ~ 指针零散记录
2016.10.11 一个记录 void MB_float_u16(float f,uint16_t *a,uint16_t *b) { uint8_t *fp; ① uint8_t *ap; ② a ...
- Mysql:零散记录
limit用法 查询第4行记录 select * from tablename limit 3,1; limit 3,1:截取第3行加1行的数据 查询第6-15行 select * from tabl ...
- ASP.NET Core学习零散记录
赶着潮流听着歌,学着.net玩着Core 竹子学Core,目前主要看老A(http://www.cnblogs.com/artech/)和tom大叔的博客(http://www.cnblogs.com ...
- python 零散记录(七)(下) 新式类 旧式类 多继承 mro 类属性 对象属性
python新式类 旧式类: python2.2之前的类称为旧式类,之后的为新式类.在各自版本中默认声明的类就是各自的新式类或旧式类,但在2.2中声明新式类要手动标明: 这是旧式类为了声明为新式类的方 ...
- python 零散记录(七)(上) 面向对象 类 类的私有化
python面向对象的三大特性: 多态,封装,继承 多态: 在不知道对象到底是什么类型.又想对其做一些操作时,就会用到多态 如 'abc'.count('a') #对字符串使用count函数返回a的数 ...
- python 零散记录(六) callable 函数参数 作用域 递归
callable()函数: 检查对象是否可调用,所谓可调用是指那些具有doc string的东西是可以调用的. 函数的参数变化,可变与不可变对象: 首先,数字 字符串 元组是不可变的,只能替换. 对以 ...
- python 零散记录(五) import的几种方式 序列解包 条件和循环 强调getattr内建函数
用import关键字导入模块的几种方式: #python是自解释的,不必多说,代码本身就是人可读的 import xxx from xxx import xxx from xxx import xx1 ...
- python 零散记录(四) 强调字典中的键值唯一性 字典的一些常用方法
dict中键只有在值和类型完全相同的时候才视为一个键: mydict = {1:1,':1} #此时mydict[1] 与 mydict['1']是两个不同的键值 dict的一些常用方法: clear ...
随机推荐
- SpringMVC拦截器详解[附带源码分析](转)
本文转自http://www.cnblogs.com/fangjian0423/p/springMVC-interceptor.html 感谢作者 目录 前言 重要接口及类介绍 源码分析 拦截器的配置 ...
- expect实现无交互操作
按两下tab linux总共2000个命令,,常用的200个命令. 只要文件改变了,MD5值就会变!
- 最近遇到的C++数字和字符串的转换问题
1. 用itoa 和atoi 在头文件#include<cstidlib> itoa用法: char * itoa ( int value, char * str, int base ) ...
- time machine不备份指定文件夹
osx中常常会使用timemachine来备份一些文件,timemachine能够使某个文件夹恢复到之前某个时刻的状态,很的方便.但是备份须要空间,特别是有些我们并不想备份一些无关紧要的文件,比方电影 ...
- HDU2897( 巴什博奕变形)
邂逅明下 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submissi ...
- Intel Edision —— 上电、基本设置与系统初探
前言 原创文章,转载引用务必注明链接.如有疏漏,欢迎斧正. Intel的文档其实挺清楚了,坛子上很多人把文档又详细复述一边,私以为一篇就够了其他的跟着文档走一遍也挺好的...俗一把使用过程顺手记录下来 ...
- Linux的SOCKET编程详解(转)
Linux的SOCKET编程详解 1. 网络中进程之间如何通信 进 程通信的概念最初来源于单机系统.由于每个进程都在自己的地址范围内运行,为保证两个相互通信的进 程之间既互不干扰又协调一致工作,操作系 ...
- 协议的注冊与维护——ndpi源代码分析
在前面的文章中,我们对ndpi中的example做了源代码分析.这一次我们将尽可能深入的了解ndpi内部的结构和运作.我们将带着以下三个目的(问题)去阅读ndpi的源代码. 1.ndpi内部是怎么样注 ...
- Yii框架中安装srbac扩展方法
首先,下载srbac_1.3beta.zip文件和对应的blog-srbac_1.2_r228.zip 问什么要下载第二个文件,后面就知道了. 按照手册进行配置: 解压缩srbac_1.3beta.z ...
- bzoj1601【Usaco2008 Oct】灌水
1601: [Usaco2008 Oct]灌水 Time Limit: 5 Sec Memory Limit: 162 MB Submit: 1589 Solved: 1035 [Submit][ ...