HTML <!DOCTYPE>标签
一般一个基本html页面的结构,如下代码所示:
<html>
<head>
<title>我是基本的页面结构</title>
</head>
<body>
//...一些其他代码
</body>
</html>
基本的页面有了,那这个页面里的标签,浏览器要怎么来解析呢。以上的html结构浏览器只能根据自己的理解来生成DOM tree。然后按照自己的方式,根据里面的标签来生成对应的对象及对象层级关系。如果想把页面真正的渲染出来就需要告诉浏览器按照怎样一种规则来渲染,如果没有浏览器就会想当然的去做了。
当没有引入doctype标签时,页面是按照怪异模式(quirks mode)渲染的,这时候页面对样式的解析是使用浏览器的方式进行的,因为各个浏览器厂商对于页面各元素的解析形为各不相同,导致大家各有各的样,奇奇怪怪的(我是这样理解的)。
当引入doctype标签后,页面就是按照doctype标签的声明的标准,对各元素进行解析来渲染。这个时候由于声明的标准都是一致的,浏览器在对各元素的渲染方式也就相同了,这个时候页面可以在多数浏览器中实现相同的排版。这样的大家都统一了,都是按照一个标准在走,所以这个时候页面就处于标准模式(strict mode)。
怎样切换这两种模式呢?
第1种方法,通过添加和删除doctype来让页面处于相应的模式。
第2种方法,在IE中可以通过切换文档模式来快速切换。
具体这个切换有什么用,其实没什么用。
有时IE出现样式错乱,可以通过观察这个文档模式来确定BUG产生原因。
比如,之前的文章中写到过的,在文档声明前出现注释这种情况的BUG。
而在现代浏览器中,怪异模式也能很好的解析。
了解过去才知未来
在HTML 4.01中,DOCTYPEK声明引用DTD,基于SGML的语言标准。DTD的标记语言的规则,使浏览器可以正确呈现。
HTML5时代的到来,已经不基于SGML,所以也不需要引用DTD了。
下面就简单的介绍一下HTML4.01中的几种经常引用的DOCTYPE声明。
HTML 4.01 Strict
该DTD包含所有HTML元素和属性,但不包括展示性的和弃用的元素(比如font)。不允许框架集(Framesets)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
HTML 4.01 Transitional
该DTD包含所有HTML元素和属性,包括展示性的和弃用的元素(比如font)。不允许框架集(Framesets)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
HTML 4.01 Frameset
该DTD等于与HTML 4.01 Transitional。但允许框架集(Framesets)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
XHTML 1.0 Strict
该 DTD 包含所有 HTML 元素和属性,但不包括展示性的和弃用的元素(比如 font)。不允许框架集(Framesets)。必须以格式正确的 XML 来编写标记。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML 1.0 Transitional
该 DTD 包含所有 HTML 元素和属性,包括展示性的和弃用的元素(比如 font)。不允许框架集(Framesets)。必须以格式正确的 XML 来编写标记。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
XHTML 1.0 Frameset
该 DTD 包含所有 HTML 元素和属性,包括展示性的和弃用的元素(比如 font)。但允许框架集(Framesets)。必须以格式正确的 XML 来编写标记。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
XHTML 1.1
该 DTD 等同于 XHTML 1.0 Strict,但允许添加模型(例如提供对东亚语系的 ruby 支持)。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
HTML5的声明
<!DOCTYPE html>
是不是眼睛看花了,我也看花了,写了这么多年的页面。前半时间都是在和html 4.01及xhtml打交道,但也没怎么去记这个。听说以前有的公司还会专门让默写这个,阿门。
DW中的文档类型设置
很多人的入门都是从DW开始。使用DW,可以在菜单里找到编辑-首选参数-创建文档-默认文档类型进行设置。对应图片大致如下: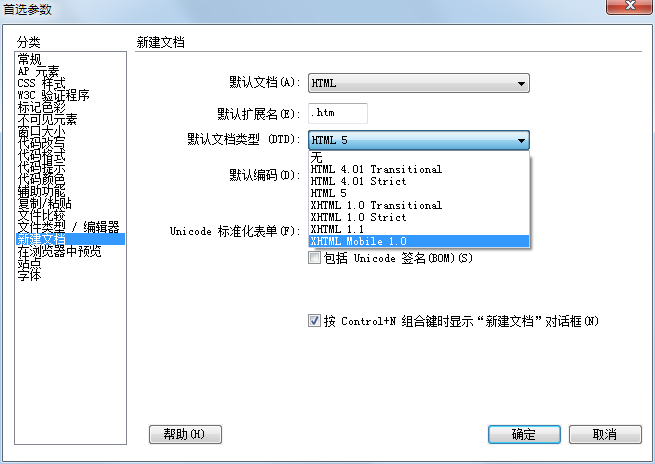
选择相应的文档类型,下次再创建时会自动生成对应的文档类型的头。
如果你想装B,非要记住上面的这些个字符头。我会说你闲得蛋疼,下面可以这样去记(好吧我也蛋疼了),xhtml类似。
第1步记住基本代码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 填空1//EN" "http://www.w3.org/TR/html4/填空2.dtd">
第2步记住文档类型英文
html 4.01类型
Strict (空 Strict)
Transitional (Transitionnal loose)
Frameset(Frameset frameset)
第3步填进去
如果你在默默记,一个你可以去吹牛了,另一个你应该尽快尝试HTML5了。
小提示
- 声明没有结束标签
- 声明对大小写不敏感
- 始终向 HTML 文档添加 <!DOCTYPE> 声明,这样浏览器才能获知文档类型。
- 声明必须是 HTML 文档的第一行
- 声明不是 HTML 标签;它是指示 web 浏览器关于页面使用哪个 HTML 版本进行编写的指令。
总结
个人拙见:在整个HTML的演进过程中,文档类型各浏览器解析页面依据的标准,促进了html语言的发展,也方便广大页面开发人员,可以把主要精力放到创新页面内容上,而不是各种兼容上。HTML5的出现,也是这种统一后的发展。大家不在寻求各自的特立独行,而是创造更好的生态环境,把对标准的实现做为目标。之后这些进入历史的内容,也就留给我们吹吹牛得了。那里讲得不对的,真心希望可以指出来,以纠正我长久的认知错误。
附录一:SGML
以下内容来自百度百科
简介
标记分为两种:
一种称为procedardmarkup,用来描述文档显示的样式;
另一种称为descriptive markup,用来描述文档中的文字的用途。制定SGML的基本思想是把文档的内容与样式分开。
工作原理
一个典型的文档可被分成3个层次:结构(structure)、内容(content)和样式(style)。SGML主要是处理结构和内容之间的关系。
(1) 结构
为了描述文档的结构,SGML定义了一个称为“文档类型定义(Document Type Definition,DTD)”的文件(file),它为组织文档的文档元素(例如章和章标题,节和主题等)提供了一个框架。此外,DTD还为文档元素之间的相互关系制定了规则。例如,“章的标题必须是在章开始之后的第一个文档元素”,“每个列表至少要有两个项目”等。DTD定义的这些规则可以确保文档的一致性。
(2) 内容
这里指的内容就是信息本身。内容包括信息名称(标题)、段落、项目列表和表格中的具体内容,具体的图形和声音等。确定内容在DTD结构中的位置的方法称为“加标签(tagging)”,而创建SGML文档实际上就是围绕内容插入相应的标签。这些标签就是给结构中的每一部分的开始和结束做标记。
HTML <!DOCTYPE>标签的更多相关文章
- HTML <del> 标签
HTML <del> 标签 什么是<del> 标签? 定义文档中已被删除的文本. 实例 a month is <del>25</del> 30 day ...
- HTML——b i del a p img h1 h2 h3 h4 h5 h6 hr ol ul 标签的使用方法详解
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 来吧,HTML5之基础标签(上)
什么是html5 HTML 5 是下一代的 HTML.HTML5 仍处于完善之中.然而,大部分现代浏览器已经具备了某些 HTML5 支持. 学习过程中标签的理解 <a>标签 定义超链接, ...
- Html标签的语义化
为了使我们的网站更好的被搜索引擎抓取收录,更自然的获得更高的流量,网站标签的语义化就显得尤为重要.所谓标签语义化,就是指标签的含义. 为了更好的理解标签的语义化,先看下面这个例子: 1 <tab ...
- HTML 文本格式化<b><big><em><i><small><strong><sub><sup><ins><del>
<b> 标签-粗体 定义和用法: <b>标签规定粗体文本. 提示和注释 注释:根据 HTML5 规范,在没有其他合适标签更合适时,才应该把 <b> 标签作为最后的选 ...
- html5标签集结1
1.<bdo>标签:覆盖默认的文本方向. <bdo dir="ltr">Here is some text</bdo> 显示结果(从左到右): ...
- HTML标签语义化
标签语义化 Web语义化是指使用语义恰当的标签,使页面有良好的结构,页面元素有含义,能够让人和搜索引擎都容易理解. 如果可以在合适的位置使用恰当的标签,那么写出来的页面语义明确,结构清晰,搜索引擎也可 ...
- <jsp:include page="">和<%@include page=""%> 标签学习
<jsp:include page=""><jsp:param value=""name=""/><DEL&g ...
- 前端基础HTML以及常用的标签
cs模式:--- c:client server bs模式:---Browser server 1.WEB标准的概念及组成 网页主要有三部分组成: a:结构 -- 主要标准:XHTML和XML ...
- HTML标签参考(一)
hi,小哥哥小姐姐们,我们今天要说的是前端的入门,却也是十分重要的意识的培养哦! • html中的标签数量是很多的,据人统计大概有300个左右,并且每年都会以20-30个的速度增加着,但是这么多的标签 ...
随机推荐
- PAT_A1107#Social Clusters
Source: PAT A1107 Social Clusters (30 分) Description: When register on a social network, you are alw ...
- Day 11 文件和异常
文件和异常 在实际开发中,常常需要对程序中的数据进行持久化操作,而实现数据持久化最直接简单的方式就是将数据保存到文件中.说到“文件”这个词,可能需要先科普一下关于文件系统的知识,对于这个概念,维基百科 ...
- C/C++ 中野指针产生的问题
野指针产生的问题: 野指针的定义: > 野指针是指:指向一个已删除的对象或未申请访问受限内存区域的指针.与空指针不同,野指针无法通过简单地判断是否为NULL避免,而只能通过养成良好的编程习惯来尽 ...
- MongoDB - 认识MongoDB及数据类型
目录 MongoDB - 认识MongoDB及数据类型 启动 MogoDB的数据 MogoDB的数据类型 1.Object ID : Documents自生成的_id 2.string : 字符串,必 ...
- 【模板】Link-Cut Tree
#include<cstdio> #include<algorithm> #define N 500010 #define rg register #define ls (c[ ...
- 【Codeforces 446A】DZY Loves Sequences
[链接] 我是链接,点我呀:) [题意] 让你找一段连续的区间 使得这一段区间最多修改一个数字就能变成严格上升的区间. 问你这个区间的最长长度 [题解] dp[0][i]表示以i为结尾的最长严格上升长 ...
- Maven学习总结(9)——使用Nexus搭建Maven私服
1 . 私服简介 私服是架设在局域网的一种特殊的远程仓库,目的是代理远程仓库及部署第三方构件.有了私服之后,当 Maven 需要下载构件时,直接请求私服,私服上存在则下载到本地仓库:否则,私服请求外部 ...
- JavaSE 学习笔记之异 常(十)
异 常: 异常:就是不正常.程序在运行时出现的不正常情况.其实就是程序中出现的问题.这个问题按照面向对象思想进行描述,并封装成了对象.因为问题的产生有产生的原因.有问题的名称.有问题的描述等多个属性信 ...
- [TS-A1489][2013中国国家集训队第二次作业]抽奖[概率dp]
概率dp第一题,开始根本没搞懂,后来看了09年汤可因论文才基本搞懂,关键就是递推的时候做差比较一下,考虑新加入的情况对期望值的贡献,然后推推公式(好像还是不太会推qaq...) #include &l ...
- PatentTips – RDMA data transfer in a virtual environment
BACKGROUND Embodiments of this invention relate to RDMA (remote direct memory access) data transfer ...