java中的堆、栈、常量池以及String类型的两种声明
参考自http://blog.sina.com.cn/s/blog_798b04f90100ta67.html http://www.cnblogs.com/fguozhu/articles/2661055.html
堆、栈、常量池
首先介绍一下堆、栈、常量池中存放的数据类型吧。
- 堆:存放所有new出来的对象;
- 栈:存放基本数据变量和对象的引用,对象(new出来的对象)本身不存在在栈中,而是存放在堆中或者常量池中(字符串对象存放在常量池中);
- 常量池:存放基本类型常量和字符串常量。
- 对于栈和常量池中的对象可以共享,对于堆中的对象不可以共享。栈中的数据大小和生命周期是可以确定的,当没有引用指向数据时,数据就会自动消失。堆中的对象由垃圾回收器负责回收,因此大小和生命周期不需要确定,具有很大的灵活性。
- 对于字符串来说,其对象的引用都是存储在栈中的,如果是编译期已经创建好(用双引号定义的)就存储在常量池中,如果是运行期(new出来的对象)则存储在堆中。对于equals相等的字符串,在常量池中只有一份,而在堆中有多份,举个例子:
String str1="abc";
String str2="abc";
String str3="abc";
String str4=new String("abc");
String str5=new String("abc");
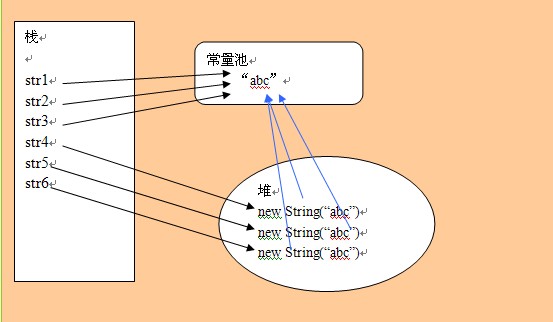
对于浅蓝色箭头,通过new操作产生一个字符串("abc")时,会先去常量池中查找是否有"abc"对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此"abc"对象的拷贝对象,所以,对于String str=new String("abc"),如果常量池中原来没有"abc"则产生两个对象,否则产生一个对象。
而对于基础类型的变量和常量,变量和引用存储在栈中,常量存储在常量池中。例如:
int a1 = 1,a2 = 1,a3 = 1;
public static final int INT1 = 1;
public static final int INT1 = 1;
public static final int INT1 = 1;
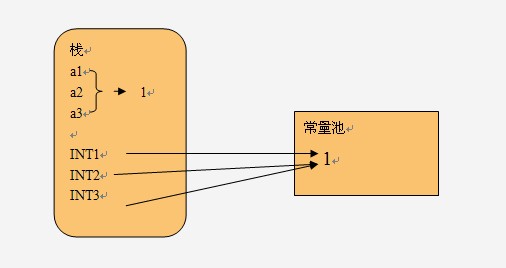
另外,局部变量(形式参数)的数据存储在栈中,并且它随方法的消失而消失
java中特殊的String类型###
Java中String是一个特殊的包装类数据有两种创建形式:
String s = "abc";
String s = new String("abc");
1.第一种先在栈中创建一个对String类的对象引用变量s,然后去查找"abc"是否被保存在字符串常量池中,如果没有则在栈中创建三个char型的值'a'、'b'、'c',然后在堆中创建一个String对象object,它的值是刚才在栈中创建的三个char型值组成的数组{'a'、'b'、'c'},接着这个String对象object被存放进字符串常量池,最后将s指向这个对象的地址,如果"abc"已经被保存在字符串常量池中,则在字符串常量池中找到值为"abc"的对象object,然后将s指向这个对象的地址。
第一种特点:JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。
2.第二种可以分解成两步1、String object = "abc";2、String s = new String(object);第一步参考第一种创建方式,而第二步由于"abc"已经被创建并保存到字符串常量池中,因此jvm只会在堆中新创建一个String对象,它的值共享栈中已有的三个char型值。
第二种特点:一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象。
==和equals的区别###
因为java所有类都继承于Object基类,而Object中equals用来实现,所以equals和是一样的,都是比较对象地址,java api里的类大部分都重写了equals方法,包括基本数据类型的封装类、String类等。对于String类==用于比较两个String对象的地址,equals则用于比较两个String对象的内容(值)。
例1.字符串常量池的使用####
String s0 = "abc";
String s1 = "abc";
System.out.println(s0==s1); //true 可以看出s0和s1是指向同一个对象的。
例2.String中==和equals的区别####
String s0 =new String ("abc");
String s1 =new String ("abc");
System.out.println(s0==s1); //false 可以看出用new的方式是生成不同的对象
System.out.println(s0.equals(s1)); //true 可以看出equals比较的是两个String对象的内容(值)
例3.编译期确定####
String s0="helloworld";
String s1="helloworld";
String s2="hello" + "word";
System.out.println( s0s1 ); //true 可以看出s0跟s1是同一个对象
System.out.println( s0s2 ); //true 可以看出s0跟s2是同一个对象
分析:因为例子中的 s0和s1中的"helloworld”都是字符串常量,它们在编译期就被确定了,所以s0s1为true;而"hello”和"world”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中"helloworld”的一个引用。所以我们得出s0s1==s2;
例4.编译期无法确定####
String s0="helloworld";
String s1=new String("helloworld");
String s2="hello" + new String("world");
System.out.println( s0s1 ); //false
System.out.println( s0s2 ); //false
System.out.println( s1==s2 ); //false
分析:用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
s0还是常量池中"helloworld”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象"helloworld”的引用,s2因为有后半部分new String(”world”)所以也无法在编译期确定,所以也是一个新创建对象"helloworld”的引用;
例5.编译期优化####
String s0 = "a1";
String s1 = "a" + 1;
System.out.println((s0 == s1)); //result = true
String s2 = "atrue";
String s3= "a" + "true";
System.out.println((s2 == s3)); //result = true
String s4 = "a3.4";
String s5 = "a" + 3.4;
System.out.println((a == b)); //result = true
分析:在程序编译期,JVM就将常量字符串的"+"连接优化为连接后的值,拿"a" + 1来说,经编译器优化后在class中就已经是a1。在编译期其字符串常量的值就确定下来,故上面程序最终的结果都为true。
例6.编译期无法确定####
String s0 = "ab";
String s1 = "b";
String s2 = "a" + s1;
System.out.println((s0 == s2)); //result = false
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + s1无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s2。所以上面程序的结果也就为false。
例7.编译期确定####
String s0 = "ab";
final String s1 = "b";
String s2 = "a" + s1;
System.out.println((s0 == s2)); //result = true
分析:和[6]中唯一不同的是s1字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量 池中或嵌入到它的字节码流中。所以此时的"a" + s1和"a" + "b"效果是一样的。故上面程序的结果为true。
例8.编译期无法确定####
String s0 = "ab";
final String s1 = getS1();
String s2 = "a" + s1;
System.out.println((s0 == s2)); //result = false
private static String getS1() { return "b"; }
分析:JVM对于字符串引用s1,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为s2,故上面 程序的结果为false。
关于String的不可变设计###
String是不可改变类(记:基本类型的包装类都是不可改变的)的典型代表,也是Immutable设计模式的典型应用,String变量一旦初始化后就不能更改,禁止改变对象的状态,从而增加共享对象的坚固性、减少对象访问的错误,同时还避免了在多线程共享时进行同步的需要。
Immutable模式的实现主要有以下两个要点:
1.除了构造函数之外,不应该有其它任何函数(至少是任何public函数)修改任何成员变量。
2.任何使成员变量获得新值的函数都应该将新的值保存在新的对象中,而保持原来的对象不被修改。
String的不可变性导致字符串变量使用+号的代价:
例9:####
String s = "a" + "b" + "c";
String s1 = "a";
String s2 = "b";
String s3 = "c";
String s4 = s1 + s2 + s3;
分析:变量s的创建等价于 String s = “abc”; 由上面例子可知编译器进行了优化,这里只创建了一个对象。由上面的例子也可以知道s4不能在编译期进行优化,其对象创建相当于:
StringBuffer temp = new StringBuffer();
temp.append(s1).append(s2).append(s3);
String s = temp.toString();
由上面的分析结果,可就不难推断出String 采用连接运算符(+)效率低下原因分析,形如这样的代码:

每做一次 + 就产生个StringBuffer对象,然后append后就扔掉。下次循环再到达时重新产生个StringBuffer对象,然后append 字符串,如此循环直至结束。如果我们直接采用StringBuffer对象进行append的话,我们可以节省N - 1次创建和销毁对象的时间。所以对于在循环中要进行字符串连接的应用,一般都是用StringBuffer或StringBulider对象来进行append操作。
java中的堆、栈、常量池以及String类型的两种声明的更多相关文章
- Java堆/栈/常量池以及String的详细详解(转)------经典易懂系统
一:在JAVA中,有六个不同的地方可以存储数据: 1. 寄存器(register). 这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部.但是寄存器的数量极其有限,所以寄存器由编译器根据 ...
- 基本数据类型的常量池与String类型常量池解析
抛出样例: Integer a1 = new Integer(123); Integer a2 = new Integer(123); System.out.print ...
- Java String引起的常量池、String类型传参、“==”、“equals”、“hashCode”问题 细节分析
在学习javase的过程中,总是会遇到关于String的各种细节问题,而这些问题往往会出现在Java攻城狮面试中,今天想写一篇随笔,简单记录下我的一些想法.话不多说,直接进入正题. 1.String常 ...
- 【转载】 Java中String类型的两种创建方式
本文转载自 https://www.cnblogs.com/fguozhu/articles/2661055.html Java中String是一个特殊的包装类数据有两种创建形式: String s ...
- java 堆 栈 常量池
java 堆中保存new 出来的对象(每个对象都包含一个与之对应的class的信息,[class信息存放在方法区]),堆中分配的内存,有虚拟机的自动垃圾回收器管理,栈内存只对其所属线程可见. java ...
- java中的堆、栈、常量池
java中的堆.栈.常量池 分类: java2010-01-15 03:03 4248人阅读 评论(5) 收藏 举报 javastring编译器jvm存储equals Java内存分配: 1. 寄存器 ...
- java中的堆、栈和常量池简介
一.它们各自存放的数据类型: 堆:存放所有new出来的对象. 栈:存放基本类型的变量数据和对象的应用,对象(new出来的对象)本身并不存在栈中,而是存放在堆中或者常量池中(字符串常量对象存放在常量池中 ...
- 详细介绍Java中的堆、栈和常量池
下面主要介绍JAVA中的堆.栈和常量池: 1.寄存器 最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制. 2. 栈 存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在 ...
- java内存管理--栈、堆和常量池
今天有朋友问java中String[] str = s.split(",")的内存分析,于是开始查资料并测试.首先,发现在java的内存管理中"常量池"是个很奇 ...
随机推荐
- asp.net ToString()格式汇总
C 货币 2.5.ToString("C") ¥2.50 D 十进制数 25.ToString("D5") 00025 E 科学型 25000.ToString ...
- arcgis显示其他国家语言
接手一个韩国的项目,需要在arcmap中配置一个韩国地图并发布到arcserver中进行切图,给的韩国地图的shapefile文件中属性字段都是韩文的,在中文的系统中,arcMap中显示的韩文都是乱码 ...
- python字典中的元素类型
python字典默认的是string item={"browser " : 'webdriver.irefox()', 'url' : 'http://xxx.com'} 如果这样 ...
- Think Python - Chapter 15 - Classes and objects
15.1 User-defined typesWe have used many of Python’s built-in types; now we are going to define a ne ...
- linux/lib/string.c
/** * strlen - Find the length of a string * @s: The string to be sized */ size_t strlen(const char ...
- 解决SimpleCursorAdapter不能自动更新的问题
假设场景是这样的:你使用SimpleCursorAdapter显示数据,并监听数据的变化:在数据发生变化的时候,调用cursor的requery,期待UI显示也跟着变化. 但是,你可能会发现,UI并没 ...
- MySQL数据库恢复的经历。
蛋疼,定时任务设置错误.把数据给删除了.还有一次是服务器时间不对,也把数据给删除了. 还好,开启了二进制日志,才算把数据找回,但是速度效率也太低. 痛定思变.在把一切交由电脑工作的时候,也要做好一定的 ...
- 徹底刪除atom
rm -f ~/.atom rm -f /usr/local/bin/atom rm -f /usr/local/bin/apm rm -f /Applications/Atom.app rm -f ...
- SQL注入测试平台 SQLol -2.SELECT注入测试
前面,我们已经安装好了SQLol,打开http://localhost/sql/,首先跳转到http://localhost/sql/select.php,我们先从select模块进行测试. 一条完成 ...
- ✡ leetcode 156. Binary Tree Upside Down 旋转树 --------- java
156. Binary Tree Upside Down Add to List QuestionEditorial Solution My Submissions Total Accepted: ...