4、Python文件对象及os、os.path和pickle模块(0530)
文件系统和文件
1、文件系统是OS用于明确磁盘或分区上的文件的方法和数据结构---即在磁盘上组织文件的方法;
- 文件系统模块:os
2、计算机文件(称文件、电脑档案、档案),是存储在某种长期储存设备或临时存储设备中的一段数据流,并且归属于计算机文件系统管理之下;
3、概括来讲:
- 文件是计算机中由OS管理的具有名字的存储区域;
- 在Linux系统上,文件被看做是字节序列

python打开文件
1、python内置函数open()用于打开文件和创建文件对象
- open('/var/log/message.log','r')
2、open方法可以接收三个参数:文件名、模式和缓冲区参数
- open函数返回的是一个文件对象
- mode:指定文件的打开模式
- bufsize:定义输出缓存
- 0:表示无输出缓存
- 1:表示使用缓冲
- 负数:表示使用系统默认设置
- 正数:表示使用近似指定大小缓冲
文件方法


创建对象后返回的是一个内存地址,通常需要一个变量名来引用这个内存地址
文件的打开模式:
1、简单模式
- r:只读
- open('/var/log/message.log','r') //以只读模式打开文件
- w:写入 //从文件指针出开始覆盖
- a:附加 //从文件尾部
2、在模式后使用“+”表示同时支持输入、输出操作
- 如r+、w+和a+ //比如w+表示读写模式的写操作,本来是写操作,也可以读
3、在模式后附加“b”表示以二进制方式打开
- 如rb、wb+
文件对象:文本都是字节序列
var_name = open (file_name[mode,[bufsize]])
- mode:
- r、w、ad、r+、w+、a+
- b表示以二进制模式打开文件
- rb、wb、ab、rb+、wb+、ab+
- 缓存:
- 0:禁用,表示不使用缓存
- 负数:表示使用系统默认的缓存
- 1:表示使用缓存,只缓冲一行数据
- 2+:指定缓冲空间大小,整数表示使用大小的缓冲区




如何移动指针
file.seek(offset[whence])
whence:起点(从什么地方开始偏移)
- 0:从文件头,默认
- 1:从当前位置
- 2:从文件尾
offset:偏移量

read表示读多少个字节的,readline表示读行的

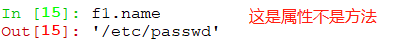


flush 刷写缓冲区 close关闭文件
练习:输入1到10之间所有正整数平方的结果写到一个文件



 、
、
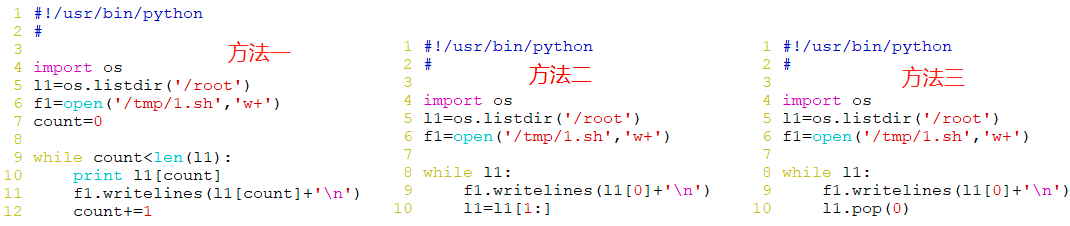
readlines

迭代的方式是不会移动指针的,比如next,只是一次返回一个行对象
但是readline却可以移动指针


truncate 做文件截取
定义保留10个字节 如果想要截取文件,只保留当前光标所在位置以前的值,把指针以后的值全部删除


closed 是属性,不是方法,显示文件是否关闭
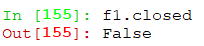
name 表示列表中保存的文件名

encoding 保存文件的编码格式,如果无显示则是默认编码
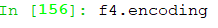
mode 获取当前文件打开的模式
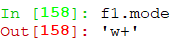
newlines 行结束字串
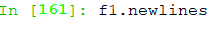
softspace 软空间,其中1表示在输出一段数据后要加上一个空格符,0表示不加
上面writeline写入文件中没有空格
f1.softspace = 1 //可以赋值
python文件对象访问指的是文件,这种文件是非目录以外的其他部分,而目录不可以,目录是文件系统的组成部分,不是文件内容的组成部分,如果要使用目录还要使用文件系统,
跟文件系统打交道,文件系统模块:os
目录:
chdir(): 切换工作目录
chroot(): 设定当前进程的根目录
listdir(): 列出指定目录下的所有文件名
mkdir(): 创建指定目录
makedirs(): 创建多级目录 os.makedirs('x/y/z')
getcwd(): 获取工作目录
rmdir(): 删除目录
removedirs():删除多级目录
编程文件系统交互接口API

文件:
mkfifo():创建管道
mknod():创建设备文件 mknod(filename [, mode=0600, device])
remove():删除文件
unlink():删除链接文件
rename():重命名
stat():返回文件的状态信息
symlink():创建符号链接 symlink(src, dst)

utime():更新时间戳
tmpfile():创建并打开(w+b)一个新的临时文件
walk():创建目录树

访问权限相关的
access():检验某个用户或用户组的权限模式
chmod():修改权限
chown():修改属主和属组
umask():设置默认权限模式
access

chmod
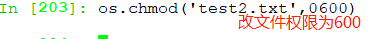
chown

文件描述符:
open():底层操作系统的open(),相当于库中的open()函数
read():较底层IO的读操作
write():较底层IO的写操作
设备文件:
makedev():创建设备文件
major():获取主设备号
minor():获取次设备号
import os.path:路径管理:
basename():路径基名
dirname():路径目录名
join():整合文件名
split():分割,返回dirname(),basename()元组
splitext():返回(filename,extension)元组,把文件名和扩展名切割开
join


split
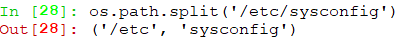
- 信息:
getatime():返回指定文件最近一次的访问时间
getctime():
getmtime():
getsize():返回文件的大小

- 查询
exists():判断指定文件是否存在
isabs():判断指定的路径是否为绝对路径
isdir():是否为目录
isfile():是否存在为文件
islink():是否为符号链接
ismount():是否为挂载点
samefile():两个路径是否指向了同一个文件

练习:
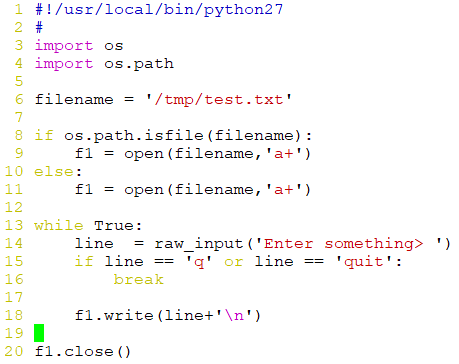
判断文件是否存在,存在则打开;让用户通过键盘反复输入多行数据;追加保存至此文件中
使用一种机制,把对象做流式化, 流式化的结果要求是:如果后期再把流式化结果载入回来的时候还是原来的样子;
因此想要保存原有数据的结构,就必须使用流式化工具(扁平化工具)转换成数据流保存在文件中,还可以再读回来,这种功能就叫对象的持久储存;
要实现对象的持久储存,要使用专门的模块来实现。
对象持久存储(模块)
1、把对象储存到文件中的模块
- pickle
- marshal
2、数据管理系统
- DBM接口:把数据存到数据库中(python没有自带能够把数据存到MySQL中的API)
DBM接口仅仅能将数据写道DBM数据库中去,但没有办法实现流式化
3、既能实现流式化又能往数据库中存
- shaelve模块
基于pickle模块直接将python原生对象存在文件中(这里是将字典存到文件中去)
help(pickle.dump)
dump(obj, file, protocol=None)

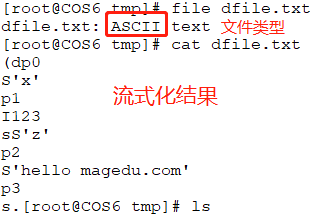
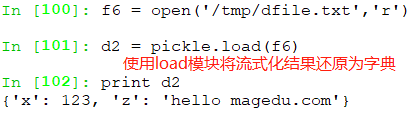
使用load模块将将流式化结果还原回来,仍然用字典模式显示
4、Python文件对象及os、os.path和pickle模块(0530)的更多相关文章
- Python 文件对象
Python 文件对象 1) 内置函数 open() 用于打开和创建文件对象 open(name,[,mode[,bufsize]]) 文件名.模式.缓冲区参数 mode: r 只读 w 写入 a 附 ...
- Python 文件对象和方法
Python文件对象和方法 1.打开和关闭文件 Python提供了必要的函数和方法进行默认情况下的文件基本操作,我们可以用file对象做大部分文件操作. open()方法 我们必须先用Python内置 ...
- Python(正则 Time datatime os sys random json pickle模块)
正则表达式: import re #导入模块名 p = re.compile(-]代表匹配0至9的任意一个数字, 所以这里的意思是对传进来的字符串进行匹配,如果这个字符串的开头第一个字符是数字,就代表 ...
- python文件对象几种操作模式区别——文件操作方法详解
文件对象的字节模式/b模式(以utf-8编码为例) 读操作 写操作 指针操作 ASCII字节 返回bytes/字节类型的Ascii 写入bytes类型字节 例如:b'This is ascii' 使用 ...
- Python文件对象方法
使用open()函数创建一个文件对象,这里是可以在这个对象上调用的函数的列表 - 编号 方法名称 描述 1 file.close() 关闭文件,无法读取或写入关闭的文件. 2 file.flush() ...
- Python文件对象的访问模式
- (原创)Python文件与文件系统系列(5)——stat模块
stat模块中定义了许多的常量和函数,可以帮助解释 os.stat().os.fstat().os.lstat()等函数返回的 st_result 类型的对象. 通常使用 os.path.is*() ...
- 关于python 文件操作os.fdopen(), os.close(), tempfile.mkstemp()
嗯.最近在弄的东西也跟这个有关系,由于c基础渣渣.现在基本上都忘记得差不多的情况下,是需要花点功夫才能弄明白. 每个语言都有相关的文件操作. 今天在flask 的例子里看到这样一句话.拉开了文件操作折 ...
- Python自动化运维之4、格式化输出、文件对象
Python格式化输出: Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存.[P ...
随机推荐
- TensorFlow 1.2.0新版本完美支持Python3.6,windows在cmd中输入pip install tensorflow就能下载应用最新tensorflow
TensorFlow 1.2.0新版本完美支持Python3.6,windows在cmd中输入pip install tensorflow就能下载应用最新tensorflow 只需在cmd中输入pip ...
- activiti 报 next dbid
记录一下吧. 今天将生产环境的几个服务节点改成集群模式,其中包含activiti审批服务节点,其中各个服务几点间数据通信采用MQ(与本文无关). 然后报出如题错误. 究其原因就是,在启动activit ...
- webService入门理解
最近可能开始要搞关于远程接口调用的玩意儿,所以上网查了一些关于远程调用额东西,其中有很多写得很不错,我把其中的比较好的几个整理一下,整理到一块儿,变成个人的理解写出来. 关于所谓的webService ...
- emmm
#include <stdio.h> #include <stdlib.h> #include <iostream> using namespace std; st ...
- Autel MaxiSys Pro MS908P Software Update Gudie
This article aims to guide on how to update software for Autel MaxiSys Pro. (Suitable for MaxiDiag E ...
- Compare AURO OtoSys IM100 with OtoSys IM600
The main difference lies in Mercedes-Benz, VW, Audi software and adapters to work with. Software dif ...
- 计算概论(A)/基础编程练习(数据成分)/2:奥运奖牌计数
#include<stdio.h> int main() { // n天的决赛项目 int n; scanf("%d",&n); ] = {}; while ( ...
- BIOS备忘录之通过Windbg来追踪ASL code的运行
通过Windbg来追踪ASL code的运行: 目标机的配置: 第一步: 在BIOS Setup下面 disable secure boot(不然下面debug on 命令会失败):关闭防火墙. 第二 ...
- JS使用onscroll、scrollTop实现图片懒加载
今天做到项目中的图片展示,由于每一页的图片数量都很多,因此需要为图片的展示设计一种懒加载的功能. 第一要做的当然就是给程序添加滚动监听事件. //触发拉取图片开关,保证正在拉取时不能再次触发 var ...
- 如何通过 Vue+Webpack 来做通用的前端组件化架构设计
目录: 1. 架构选型 2. 架构目录介绍 3. 架构说明 4. 招聘消息 目前如果要说比较流行的前端架构哪家强,屈指可数:reactjs.angularjs.emberj ...