Python全栈-magedu-2018-笔记11
第三章 - Python 内置数据结构
简单选择排序
- 简单选择排序
- 属于选择排序
- 两两比较大小,找出极值(极大值或极小值)被放置在固定的位置,这个固定位置一般指的是某一端
- 结果分为升序和降序排列
- 降序
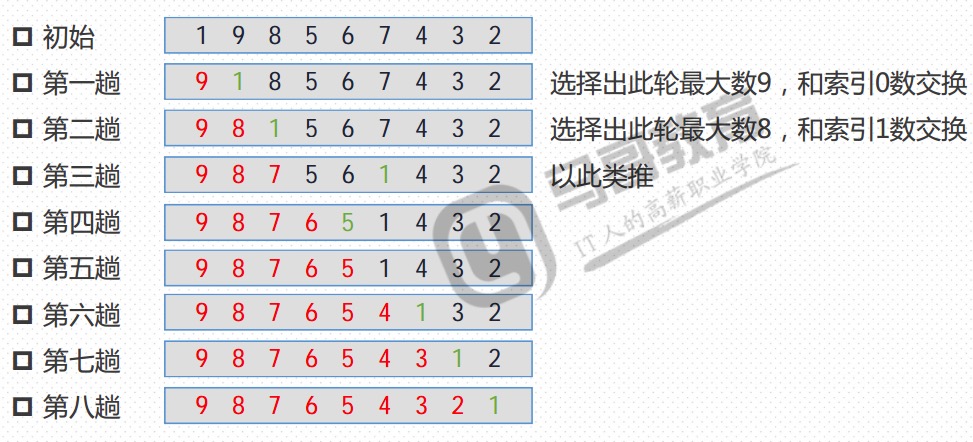
- n个数从左至右,索引从0开始到n-1,两两依次比较,记录大值索引,此轮所有数比较完毕,将大数和索引0数交换,如果大数就是索引1,不交换。第二轮,从1开始比较,找到最大值,将它和索引1位置交换,如果它就在索引1位置则不交换。依次类推,每次左边都会固定下一个大数。
- 升序
- 和降序相反
简单选择排序
简单选择排序代码实现(一)*
m_list = [
[1, 9, 8, 5, 6, 7, 4, 3, 2],
[1, 2, 3, 4, 5, 6, 7, 8, 9],
[9, 8, 7, 6, 5, 4, 3, 2, 1]
]
nums = m_list[1]
length = len(nums)
print(nums)
count_swap = 0
count_iter = 0
for i in range(length):
maxindex = i
for j in range(i + 1, length):
count_iter += 1
if nums[maxindex] < nums[j]:
maxindex = j
if i != maxindex:
tmp = nums[i]
nums[i] = nums[maxindex]
nums[maxindex] = tmp
count_swap += 1
print(nums, count_swap, count_iter)简单选择排序代码实现(二)
- 优化实现
二元选择排序
同时固定左边最大值和右边最小值
优点:
减少迭代元素的次数
1、length//2 整除,通过几次运算就可以发现规律
2、由于使用了负索引,所以条件中要增加
i == length + minindex
还有没有优化的可能?
count_swap = 0
count_iter = 0
# 二元选择排序
for i in range(length // 2):
maxindex = i
minindex = -i - 1
minorigin = minindex
for j in range(i + 1, length - i): # 每次左右都要少比较一个
count_iter += 1
if nums[maxindex] < nums[j]:
maxindex = j
if nums[minindex] > nums[-j - 1]:
minindex = -j - 1
# print(maxindex, minindex)
if i != maxindex:
tmp = nums[i]
nums[i] = nums[maxindex]
nums[maxindex] = tmp
count_swap += 1
# 如果最小值被交换过,要更新索引
if i == minindex or i == length + minindex:
minindex = maxindex
if minorigin != minindex:
tmp = nums[minorigin]
nums[minorigin] = nums[minindex]
nums[minindex] = tmp
count_swap += 1
print(nums, count_swap, count_iter)简单选择排序代码实现(二)
- 改进实现
如果一轮比较后,极大值、极小值的值相等,说明比较的序列元素全部相等
m_list = [
[1, 9, 8, 5, 6, 7, 4, 3, 2],
[1, 2, 3, 4, 5, 6, 7, 8, 9],
[9, 8, 7, 6, 5, 4, 3, 2, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]
]
nums = m_list[3]
length = len(nums)
print(nums)
count_swap = 0
count_iter = 0
# 二元选择排序
for i in range(length // 2):
maxindex = i
minindex = -i - 1
minorigin = minindex
for j in range(i + 1, length - i): # 每次左右都要少比较一个
count_iter += 1
if nums[maxindex] < nums[j]:
maxindex = j
if nums[minindex] > nums[-j - 1]:
minindex = -j - 1
# print(maxindex, minindex)
if nums[maxindex] == nums[minindex]: # 元素全相同
break
if i != maxindex:
tmp = nums[i]
nums[i] = nums[maxindex]
nums[maxindex] = tmp
count_swap += 1
# 如果最小值被交换过,要更新索引
if i == minindex or i == length + minindex:
minindex = maxindex
if minorigin != minindex:
tmp = nums[minorigin]
nums[minorigin] = nums[minindex]
nums[minindex] = tmp
count_swap += 1
print(nums, count_swap, count_iter)简单选择排序代码实现(二)
- 改进实现
[1, 1, 1, 1, 1, 1, 1, 1, 2] 这种情况,找到的最小值索引是-2,最大值索引8,上面的代码会交换2次,最小值两个1交换是无用功,所以,增加一个判断
m_list = [
[1, 9, 8, 5, 6, 7, 4, 3, 2],
[1, 2, 3, 4, 5, 6, 7, 8, 9],
[9, 8, 7, 6, 5, 4, 3, 2, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 2]
]
nums = m_list[4]
length = len(nums)
print(nums)
count_swap = 0
count_iter = 0
# 二元选择排序
for i in range(length // 2):
maxindex = i
minindex = -i - 1
minorigin = minindex
for j in range(i + 1, length - i): # 每次左右都要少比较一个
count_iter += 1
if nums[maxindex] < nums[j]:
maxindex = j
if nums[minindex] > nums[-j - 1]:
minindex = -j - 1
print(maxindex, minindex)
if nums[maxindex] == nums[minindex]: # 元素相同
break
if i != maxindex:
tmp = nums[i]
nums[i] = nums[maxindex]
nums[maxindex] = tmp
count_swap += 1
# 如果最小值被交换过,要更新索引
if i == minindex or i == length + minindex:
minindex = maxindex
# 最小值索引不同,但值相同就没有必要交换了
if minorigin != minindex and nums[minorigin] != nums[minindex]:
tmp = nums[minorigin]
nums[minorigin] = nums[minindex]
nums[minindex] = tmp
count_swap += 1
print(nums, count_swap, count_iter)简单选择排序总结
- 简单选择排序需要数据一轮轮比较,并在每一轮中发现极值
- 没有办法知道当前轮是否已经达到排序要求,但是可以知道极值是否在目标索引位置上
- 遍历次数1,...,n-1之和n(n-1)/2
- 时间复杂度O(n2)
- 减少了交换次数,提高了效率,性能略好于冒泡法
最后
本文的另外链接是:https://herodanny.github.io/python-magedu-2018-notes11.html
Python全栈-magedu-2018-笔记11的更多相关文章
- 自学Python全栈开发第一次笔记
我已经跟着视频自学好几天Python全栈开发了,今天决定听老师的,开始写blog,听说大神都回来写blog来记录自己的成长. 我特别认真的跟着这个视频来学习,(他们开课前的保证书,我也写 ...
- Python全栈之jQuery笔记
jQuery runnoob网址: http://www.runoob.com/jquery/jquery-tutorial.html jQuery API手册: http://www.runoob. ...
- python全栈开发之OS模块的总结
OS模块 1. os.name() 获取当前的系统 2.os.getcwd #获取当前的工作目录 import os cwd=os.getcwd() # dir=os.listdi ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
- python 全栈开发,Day43(python全栈11期月考题)
python全栈11期月考题 1.常用字符串格式化有哪些?并说明他们的区别 2.请手写一个单例模式(面试题) 3.利用 python 打印前一天的本地时间,格式为‘2018-01-30’(面试题) 4 ...
- 学习笔记之Python全栈开发/人工智能公开课_腾讯课堂
Python全栈开发/人工智能公开课_腾讯课堂 https://ke.qq.com/course/190378 https://github.com/haoran119/ke.qq.com.pytho ...
- 老男孩最新Python全栈开发视频教程(92天全)重点内容梳理笔记 看完就是全栈开发工程师
为什么要写这个系列博客呢? 说来讽刺,91年生人的我,同龄人大多有一份事业,或者有一个家庭了.而我,念了次985大学,年少轻狂,在大学期间迷信创业,觉得大学里的许多课程如同吃翔一样学了几乎一辈子都用不 ...
随机推荐
- 学习一个Vue模板项目
最开始学习Vue的时候,不建议直接使用模板,而应该自己从头写起.模板都是人写的,要坚信"人能我能".只有自己亲自实践,才能促进自己主动思考,才能对模板.框架有深刻的理解. 在Git ...
- android开发的童鞋们 你该学点C++
更多关于C++的知识点,请关注android开发应该学点C++(索引贴)android开发应该学点C++(其他) (*android开发论坛----android开发学习----android开发*) ...
- JS 引擎执行机制
JS JS 是单线程语音 JS 的 Event Loop 是 JS 的执行机制.类似于 Android Handler 消息分发机制 JS 单线程 技术的出现都跟现实世界里的应用场景密切相关 JS 单 ...
- 彻底理解js中的闭包
闭包是js的一个难点也是它的一个特色,是我们必须掌握的js高级特性,那么什么是闭包呢?它又有什么用呢? 我们都知道,js的作用域分两种,全局和局部,基于我们所熟悉的作用域链相关知识,我们知道在js作用 ...
- leetcode笔记:3Sum Closest
一.题目描写叙述 二.解题技巧 该题与3Sum的要求类似.不同的是要求选出的组合的和与目标值target最接近而不一定相等.但实际上,与3Sum的算法流程思路类似,先是进行排序.然后顺序选择数组A中的 ...
- C++:重载全局new/delete实现跨平台多线程内存检测
Reference: https://blog.csdn.net/u014023615/article/details/39551191 Reference: https://blog.csdn.ne ...
- PHP扩展类ZipArchive实现压缩解压Zip文件和文件打包下载
文章转载自:https://my.oschina.net/junn/blog/104464 PHP ZipArchive 是PHP自带的扩展类,可以轻松实现ZIP文件的压缩和解压,使用前首先要确保PH ...
- 国内AR行业现状研究之百度的AR
AR(Augmented Reality),中文翻译增强现实.按我原来的知识体系,VR/AR的技术构成是相同的,只是追求的方向不同.VR是虚拟笼罩现实.让虚拟就是现实:AR则让虚拟进入现实.二者最终看 ...
- mongo 删除内嵌数组元素
文档格式如下: { "_id" : ObjectId("56e2a92ccc6dd2271953e502"), "links": [ { & ...
- MyBatis XML转义字符
当我们需要通过xml格式处理sql语句时,经常会用到< ,<=,>,>=等符号,但是很容易引起xml格式的错误,这样会导致后台将xml字符串转换为xml文档时报错,从而导致程序 ...