GEO数据下载分析(SRA、SRR、GEM、SRX、SAMN、SRS、SRP、PRJNA全面解析)
很多时候我们需要从GEO(https://www.ncbi.nlm.nih.gov/geo/)下载RNA-seq数据,一个典型的下载页面是https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE76381(搜 GSE76381)。
这里你会看到数据的总览:
GSM2268339 1772067089_A01
GSM2268340 1772067089_A02
GSM2268341 1772067089_A03
……
Supplementary file Size Download File type/resource
SRP/SRP067/SRP067844 (ftp) SRA Study
GSE76381_ESMoleculeCounts.cef.txt.gz 5.9 Mb (ftp)(http) TXT
GSE76381_EmbryoMoleculeCounts.cef.txt.gz 5.3 Mb (ftp)(http) TXT
GSE76381_MouseAdultDAMoleculeCounts.cef.txt.gz 1.0 Mb (ftp)(http) TXT
GSE76381_MouseEmbryoMoleculeCounts.cef.txt.gz 6.1 Mb (ftp)(http) TXT
GSE76381_iPSMoleculeCounts.cef.txt.gz 1001.2 Kb (ftp)(http) TXT
现在我们已经从ftp上下载了该文章的所有sra数据。
名称 大小 修改日期
[上级目录]
SRR4055063/ 2016/8/24 上午8:00:00
SRR4055064/ 2016/8/24 上午8:00:00
SRR4055065/ 2016/8/24 上午8:00:00
SRR4055066/ 2016/8/24 上午8:00:00
......
里面每一个文件夹里对应一个或多个sra文件。
比对,SRR4061391.sra文件是一个二进制文件,需要使用sra工具来转化为fastq。
转换之后的fastq如下:
@SRR4061391.sra.1 Run0289_BC69A1ACXX_L7_T1101_C8 length=51
ATTCAAGGGAGTTATAAGCAGAGTCAATAATGAATTTCTTCCTGCGTCTCC
+SRR4061391.sra.1 Run0289_BC69A1ACXX_L7_T1101_C8 length=51
CCCFFFFFHDHFHIJJJJJGJIIEHHIJJJJIIIIJJIIJIJJJIJJJJJJ
@SRR4061391.sra.2 Run0289_BC69A1ACXX_L7_T1101_C18 length=51
TTGATTGGGCACCTAGAAGCCAAGGACTCTCTAAGTCCTAGTCTGTTTGGT
+SRR4061391.sra.2 Run0289_BC69A1ACXX_L7_T1101_C18 length=51
CCCFFFFFHHHHHJJJGIJIIJJJJJJJJJJJJJJIIJJIIIJJJJJJJJF
可以看到,fastq文件里没有任何有价值的样品信息(物种、样品名、细胞名、组织)。
此时你只能去文章里找相关信息:

文章里真正实用的信息很少,
The molar concentrations of the libraries was determined with KAPA Library Quant qPCR (Kapa Biosystems) and size distribution was evaluated after PCR (12cycles) using an Agilent BioAnalyzer. Sequencing was performed on an Illumina HiSeq 2000 with C1-P1-PCR2 as read 1 primer and C1-TN5-U as index read primer. Reads of 50 bp as well as 8 bp index reads corresponding to the cell-specific barcodes were generated. Reads were mapped using bowtie and processed as described previously (Zeisel et al., 2015), adding the more strict criteria for UMI counting: we removed all singletons (molecules supported by a single read).
也没说太清楚,下载的数据中找不到那8bp的barcode,说明数据已经按照barcode拆好了。
Reads of 50 bp were generated along with 8 bp index reads corresponding to the cell-specific barcode. Each read was expected to start with a 6 bp unique molecular identifier (UMI), followed by 3-5 guanines, followed by the 5’ end of the transcript.
绕了一大圈,真正有价值的信息原来在引文中,所以现在的大牛真是喜欢拽,非要别人去读他之前的文章。
总结:到此,该文献的全部数据是下下来了,也已经转换为fastq,知道fastq的格式信息,但是我们还不知道没一个fastq的样品信息。
回到开始的页面,貌似有样品的信息:
GSM2268339 1772067089_A01
GSM2268340 1772067089_A02
GSM2268341 1772067089_A03
这是全部的信息:

确实是样品信息,样品编号,物种信息。
点击GSM2268340会发现一些更详细的样品信息:
Status Public on Oct 06, 2016
Title 1772067089_A02
Sample type SRA Source name ventral midbrain
Organism Homo sapiens
Characteristics tissue: ventral midbrain
Sex: pooled male and female
age: 7w
inferred cell type: hRgl2a
总结:但是到目前我们还是找不到SRR文件的样品信息,只是找到了GSM的。
那么怎么找SRR和GSM之间的关系呢?
直接在GEO搜索SRR4061391,结果如下:
终于找到了对应关系,SRX2050530: GSM2274293: 1772096111_A02; Mus musculus; RNA-Seq
GSM2274293包含了两个SRR文件。

总结:到目前为止,已经能手动查找到下载的SRR文件对应的样品信息了。但总共有6k多个,不可能这么手动查吧。
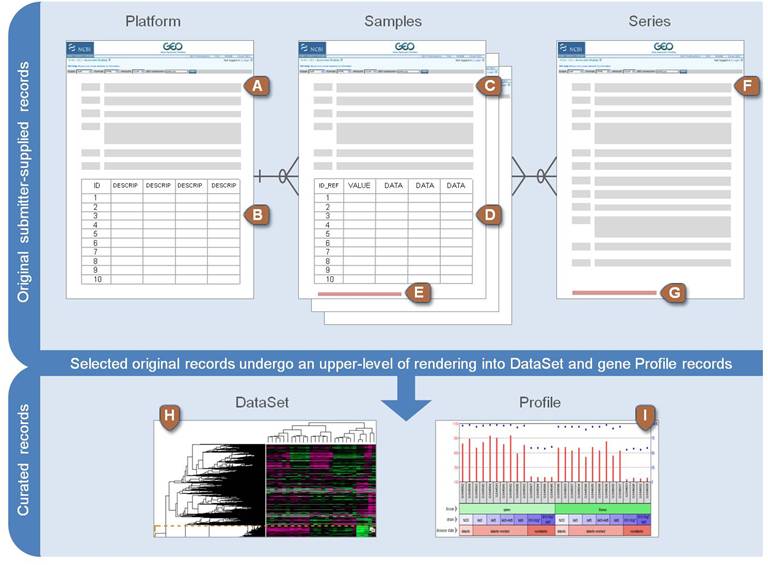
开始科普:About GEO DataSets
Lists the DataSet (GDS), Series (GSE) or Platform (GPL) accession number, followed by title and organism.
lists the Sample accessions numbers (GSM) and titles.
GDS编号:数据集
GSE编号:系列
GPL编号:平台
GSM编号:样品登陆号
Google了很多,最后发现还是用Biopython比较靠谱,Biopython现在做得不错了哦,维护的人变多了。
参考:
Question: From A Geo Gsm Id, How To Obtain The Corresponding Raw File(S) Hosted On Sra?
GEO数据下载分析(SRA、SRR、GEM、SRX、SAMN、SRS、SRP、PRJNA全面解析)的更多相关文章
- 8、SRR数据下载https://ftp-trace.ncbi.nlm.nih.gov/sra/sdk/2.8.2/
1.prefetch SRRxxxxxx -/ncbi/public/sra 2.fastq-dump --split-files xxxxxxsra 3.SRA.SAM以及Fastq ...
- 使用GEOquery下载GEO数据--转载
最近需要下载一大批GEO上的数据,问题是我要下载的Methylation数据根本就没有sra文件,换言之不能使用Aspera之类的数据进行下载.但是后来我发现了GEOquery这个不错的R包,不知道是 ...
- <二代測序> 下载 NCBI sra 文件
本文近期更新地址: http://blog.csdn.net/tanzuozhev/article/details/51077222 随着測序技术的不断提高.二代測序数据成指数增长. NCBI提供了S ...
- WireShark数据包分析数据封装
WireShark数据包分析数据封装 数据封装(Data Encapsulation)是指将协议数据单元(PDU)封装在一组协议头和尾中的过程.在OSI七层参考模型中,每层主要负责与其它机器上的对等层 ...
- CSDN泄漏数据完整分析
CSDN泄漏数据完整分析 2011-12-22 08:59:26 53391 次阅读 0 条评论 感谢mayee的投递 昨天CSDN的用户数据库被人在网上公布.我下载分析了下里面的数据,得出了一些很有 ...
- 在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析
在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析 低成本的Blob存储是一个强大的.通用的Hadoop兼容Azure存储解决方式无缝集成HDInsight.通过Hadoop分布式 ...
- Elasticsearch(GEO)数据写入和空间检索
Elasticsearch简介 什么是 Elasticsearch? Elasticsearch 是一个开源的分布式 RESTful搜索和分析引擎,能够解决越来越多不同的应用场景. 本文内容 本文主要 ...
- mapReduce 大数据离线分析
数据分析一般分为两种,一种是在线一种是离线 流程: 一般都是对于日志文件的采集和分析 场景实例(某个电商网站产生的用户访问日志(access.log)进行离线处理与分析的过程) 1.需求: 基于Map ...
- 气象netCDF数据可视化分析
气象netCDF数据可视化分析 2019-09-19 15:34:22 自走棋 阅读数 162更多 分类专栏: web前端 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载 ...
随机推荐
- py4CV例子3Mnist识别和ANN
1.什么是mnist数据集: , , ], ,,,,,,,,]], ., ., , , ], ,,,,,,,,]], ., ., , , ])) animals_net.setTermCriteri ...
- 20145325张梓靖 《网络对抗技术》 Web安全基础实践
20145325张梓靖 <网络对抗技术> Web安全基础实践 实验内容 使用webgoat进行XSS攻击.CSRF攻击.SQL注入 XSS攻击:Stored XSS Attacks.Ref ...
- 神经网络优化算法如何选择Adam,SGD
之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下: o ...
- Codeforces Round #427 (Div. 2) Problem C Star sky (Codeforces 835C) - 前缀和
The Cartesian coordinate system is set in the sky. There you can see n stars, the i-th has coordinat ...
- topcoder srm 707 div1
1 构造一个棋盘,长宽n,m不超过50,每个格子为障碍或者非障碍两种,使得从(0,0)到(n-1,m-1)的最短路为给定的值k. 思路:如果k小于等于98,那么一定存在没有障碍的棋盘满足要求.否则,最 ...
- (转)Nginx学习
(二期)15.负载均衡nginx [课程15]nginx安装.xmind0.2MB [课程15]Nginx能做什么.xmind0.1MB [课程15]负载均衡nginx.xmind96.7KB [课程 ...
- 3. Elements of a Test Plan
https://jmeter.apache.org/usermanual/test_plan.html This section describes the different parts of a ...
- Trimmomatic过滤Illumina低质量序列
1. 下载安装 直接去官网下载二进制软件,解压后的trimmomatic-0.36.jar即为我们需要的软件 官网: http://www.usadellab.org/cms/index.php?pa ...
- vs 附加进程 iis进程显示
- 【AI】微软人工智能学习笔记(二)
微软Azure机器学习服务 01|机器学习概述 首先上一张图, 这个图里面的大神是谁我也不清楚反正,但是看起来这句话说得很有哲理就贴出来了. 所以在人工智能领域下面的这个机器学习,到底是一个什么样的概 ...