php使用solr全文搜索引擎
前言
本来以为网上已经有了类似博文,不想重复,可是一圈搜下来,都是一些内容不甚明了的文章,或者solr版本太过老,参考价值不高,更有甚者,直接拷贝的别人的内容。一篇博客,各大平台都能看到,也不见转载链接。有人说百度搜索不到内容,用谷歌,把责任推到百度身上,但这是百度的原因吗?在国内网络的资源整体质量不高低,并且内容太多重复的情况下,百度能够提供什么高质量的内容给你。
也有我搜索资源的时候,会看到IBM开者中心的翻译文档,在文章的最后,都会附上参考文章,但是在国内,显有这种情况。那些拷贝别人博文的人,有没有想过,写一篇博文的不易?同样,博文作者是否也想过这个问题?话不多说,进入正题。
声明:因为本人不是从事java开发,而且技术不高,英语也很差,如果文章中存在错误的解说,望谅。
参考文章:
window环境
1,安装solr
下载solr,选择相应版本,注意:因为solr对是基于java的,所以必需安装jre。每个版本的 solr对jre版本要求不一样,下载时请注意solr的版本。
编写这篇博文时,solr的最新版本是6.6,文章也是基于6.6版本写的,其要求1.8版本或以上的jre。jre的安装,这些就不列出了,因为太过简单。
Window用户请下载zip包
将压缩包解压到相应目录
使用命令行工具,进入解压后的solr目录的bin目录
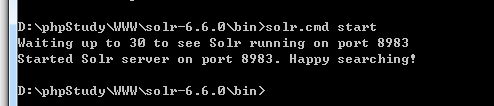
启动solr
运行命令: bin\solr.cmd start
注意:solr有两种模式:core,collection,如果要使用collection,请加-c或者-cloud,启用solrClund。两者之间的区别,我不敢妄下定论。从搜索的资料综合分析,一个是单机,一个是集群,此处仅供参考,可能存在错误。
solr默认监听的是8983端口
更多命令用法,请使用solr -help,如果solr已经启动,请使用solr start -help。
如果启动成功,可以在浏览器中打开:http://localhost:8983/solr/,使用其web管理客户端。
2,查看solr范例
先停止solr实例
bin\solr.cmd stop
再启用solr范例
bin\solr.cmd -e techproducts
打开web管理客户端:http://localhost:8983/solr/,查看结果
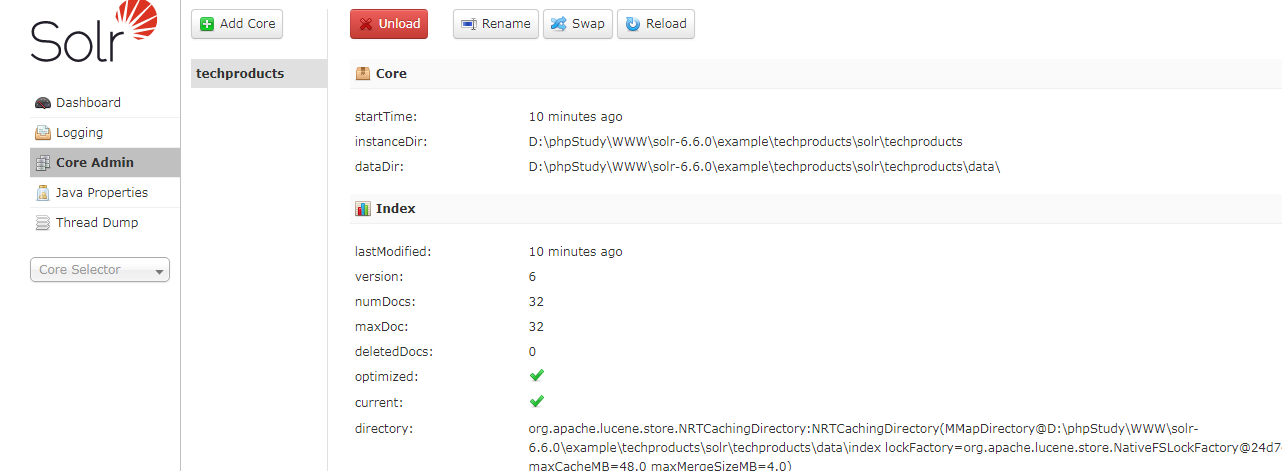
根据结果,可知道,techproducts范例中共有32篇文章。
现在可以尝试他的查询功能。
我在q输入框中输入了Samsung,其得到的结果如下图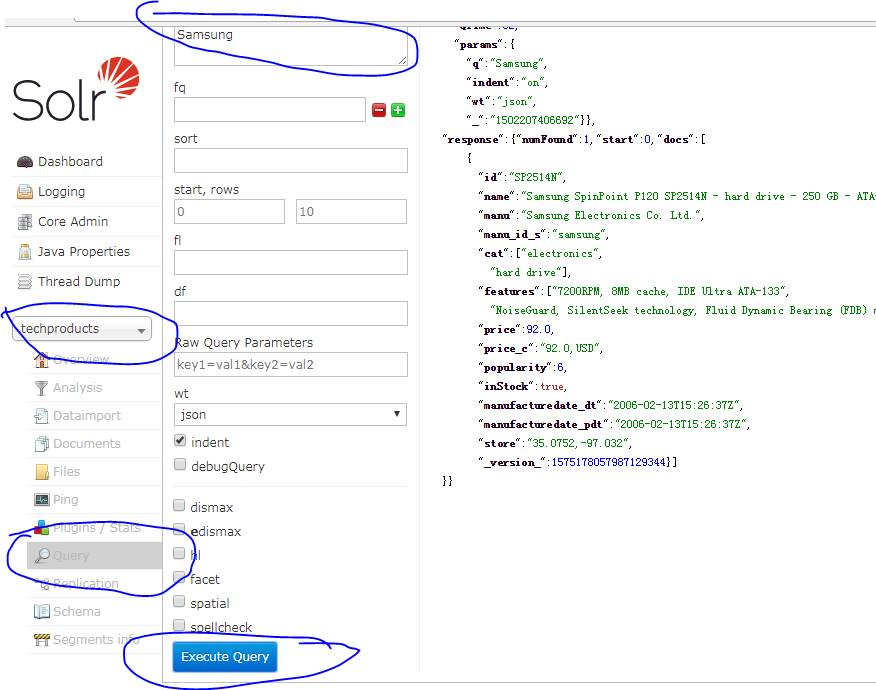
3,添加文档
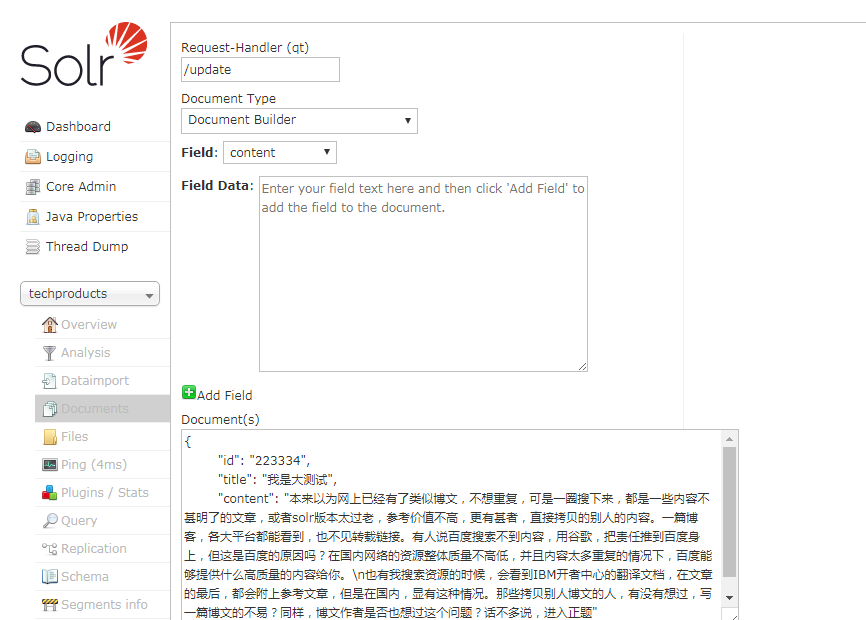

添加好后,进入查询界面,看能否查到这篇文档
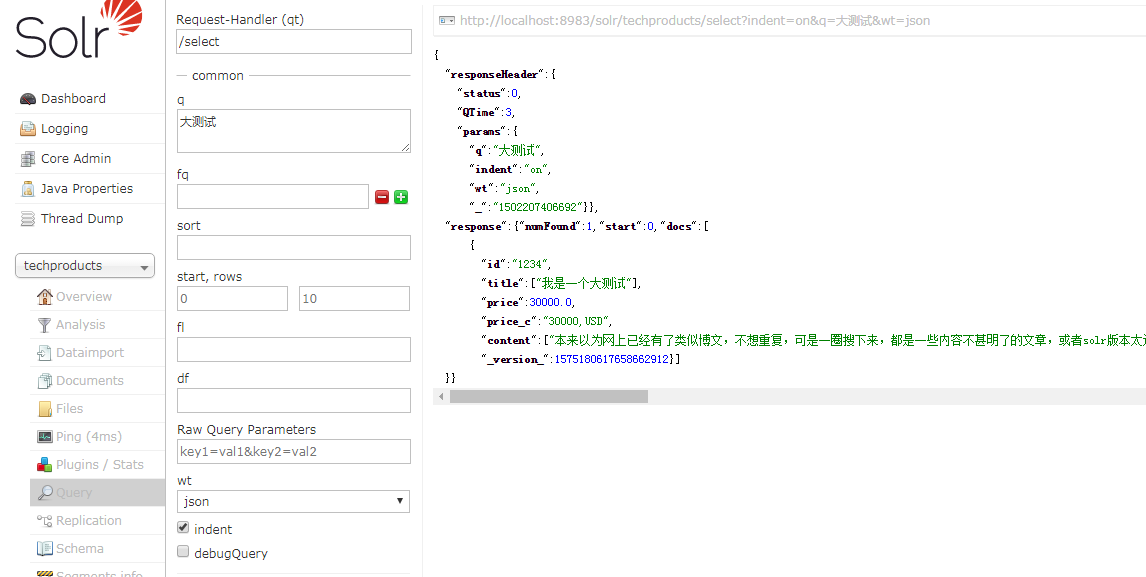
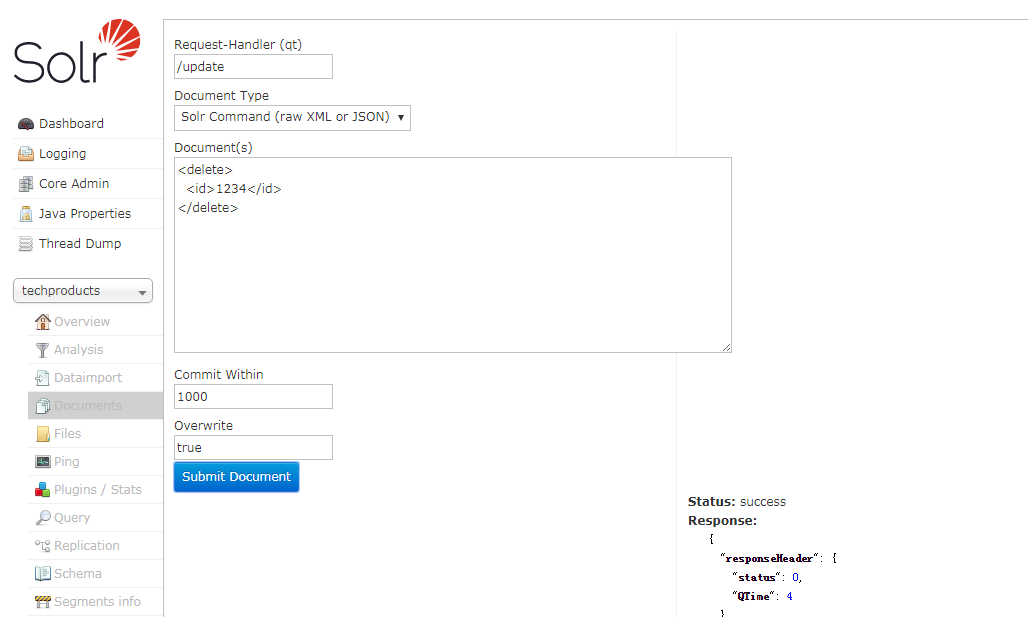
4,删除文档
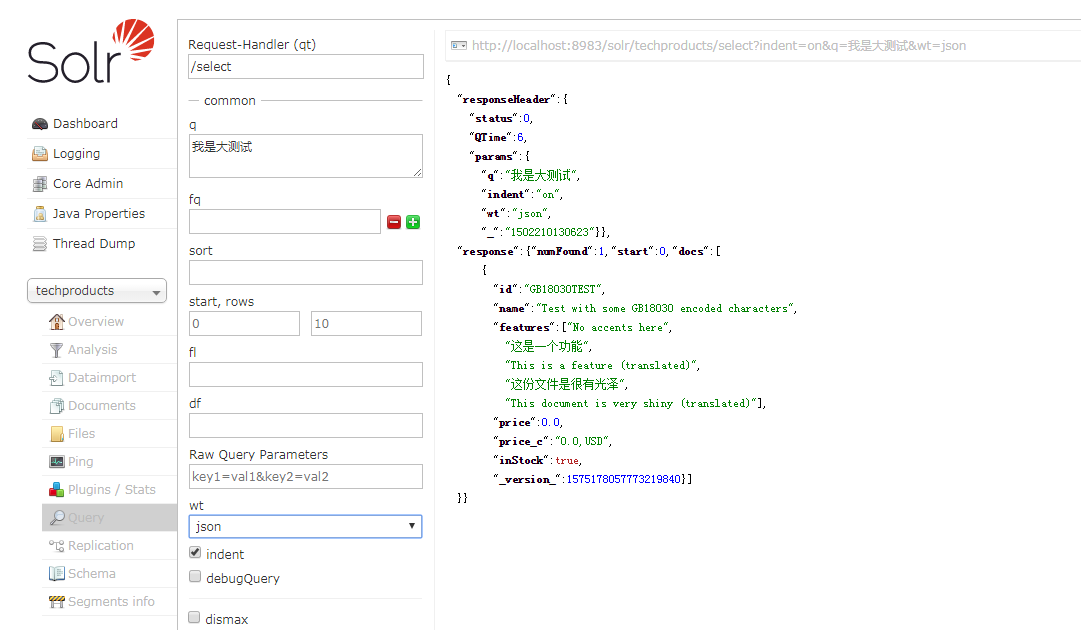
返回查询界面,查询删除后的结果
solr是通过Request-Handler指令操作文档的,solr项目所有的Request-Handler指令都定义在项目目录的conf文件夹下的solrconfig.xml文件里requestHandler标签中。
关于文档操作更详细的说明请参考:
Indexing and Basic Data Operations
Uploading Data with Index Handlers
5,创建solr项目
现在学会一些基本的操作,可以自己创建一个项目录了。
先把停止solr
solr.cmd stop -all
solr是一个实例可以有多个core或collection,如果不先停止,创建的core将会添加到启用的techproducts实例中
solr.cmd create -c test
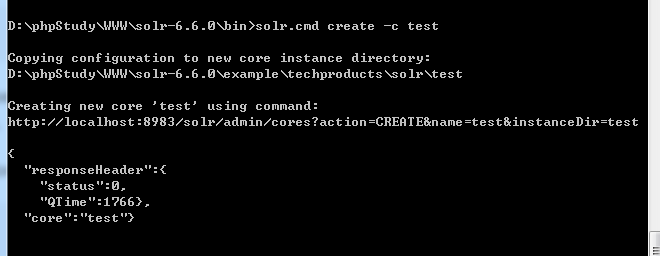
重新刷新web客户端

6,下载php的solr扩展
现在开始使用php和solr交互了,所以必需安装solr扩展,下载地址
下载解压之后,将其中的dll文件放到php的扩展目录,对于php扩展所在目录,然后在php.ini开启solr扩展,再通phpinfo查看是否正常安装。
我默认所有读者都知道php扩展配置方式,所有这里不详细描述。
注意:php有Thread Safe和NoneThread Safe之分,下载之前,请先确定你安装的php是哪种类型。
7,使用php脚本添加文档
$options = array
(
'hostname' => "localhost",
'path' => 'solr/test',
'port' => '8983',
); $client = new SolrClient($options);
$data = array(
array(
'id' => 'EN80922032',
'name' => '男士打磨直筒休闲牛仔裤',
'brand' => 'ENERGIE',
'cat' => '牛仔裤',
'price' => '1870.00'
),
array(
'id' => 'EN70906025',
'name' => '品牌LOGO翻领拉链外套',
'brand' => 'ENERGIE',
'cat' => '外套',
'price' => '1680.00'
),
); foreach($data as $key => $value) {
$doc = new SolrInputDocument();
foreach($value as $key2 =>$value2) {
$doc->addField($key2,$value2);
}
$client->addDocument($doc); }
$client->commit();
在solr的web客户端查询的结果
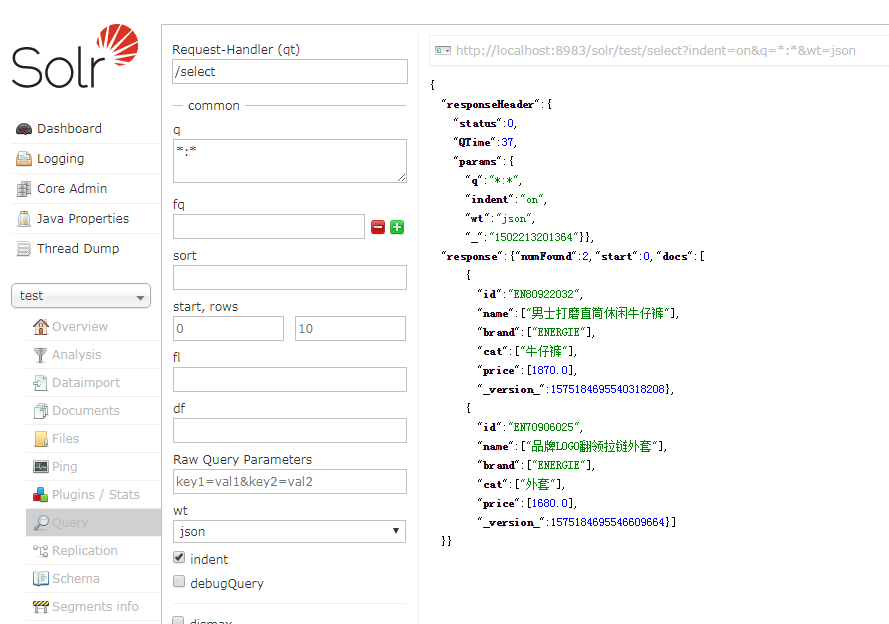
更多实例请见:php的solr扩展官方文档
注意:参考官方文档时,注意其连接参数,依其博文必需有path参数,path参数是"solr/",加上你用solr创建的core名称。
9,使用php脚本查询文档
$options = array
(
'hostname' => "localhost",
'path' => 'solr/test',
'port' => '8983',
); $client = new SolrClient($options);
$query = new SolrQuery(); $query->setQuery('打磨'); $query->setStart(0); $query->setRows(50); $query->addField('name'); $query_response = $client->query($query); $response = $query_response->getResponse(); print_r($response);
输入的结果
SolrObject Object
(
[responseHeader] => SolrObject Object
(
[status] => 0
[QTime] => 3
[params] => SolrObject Object
(
[q] => 打磨
[indent] => on
[fl] => name
[start] => 0
[rows] => 50
[version] => 2.2
[wt] => xml
) ) [response] => SolrObject Object
(
[numFound] => 1
[start] => 0
[docs] => Array
(
[0] => SolrObject Object
(
[name] => Array
(
[0] => 男士打磨直筒休闲牛仔裤
) ) ) ) )
10,使用php脚本删除文档
$client->deleteByQuery('id:EN80922032');
$result = $client->commit();
print_r($result);
输出的结果不易看懂
可以使用第九条“使用php脚本查询文档”,查看删除后的结果,也可以用web客户端查看结果。
11,更新文档
更新文档和添加文档一样,只要在数据中指定要更新的id即可。
12,添加搜索建议
在添加的core的conf文件里sorlconfig.xml中新增一搜索建议组件。依本博文,目录地址为:solr-6.6.0\server\solr\test\conf\solrconfig.xml
配置只在solr6.6上经过测试,不能保证可在其他solr版本中使用
<searchComponent name="suggest" class="solr.SuggestComponent">
<str name="queryAnalyzerFieldType">string</str>
<lst name="suggester">
<str name="name">suggest</str> <str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookupFactory</str>
<str name="field">title</str>
<str name="buildOnOptimize">true</str>
<str name="buildOnCommit">true</str>
</lst>
</searchComponent> <requestHandler name="/suggest" class="solr.SearchHandler"
startup="lazy" >
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.dictionary">suggest</str>
<str name="suggest.count">10</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
23,添加中文分词
solr自带了中文分词功能,依本博文,目录地址为:solr-6.6.0\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-6.6.0 .jar。
首先查看sorlconfig.xml配置文件是否已经配置了这个分配库的地址
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
如果没有,请配置分词库的地址。
在managed-schema文件中新增一个字段类型
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
然后将相应字段的类型设置成text_cn,例如,本博文中将name设为text_cn类型
<field name="title" type="text_cn" indexed="true" stored="true" required="true" multiValued="true"/>
在后台选择相应的core,点击【analysis】菜单,在字段值中输入相应中文,在Fieldname/FieldType中选择相应设置了字段类型为text_cn的字段,或者直接选择text_cn字段类型,点击【analysis】查看分词效果
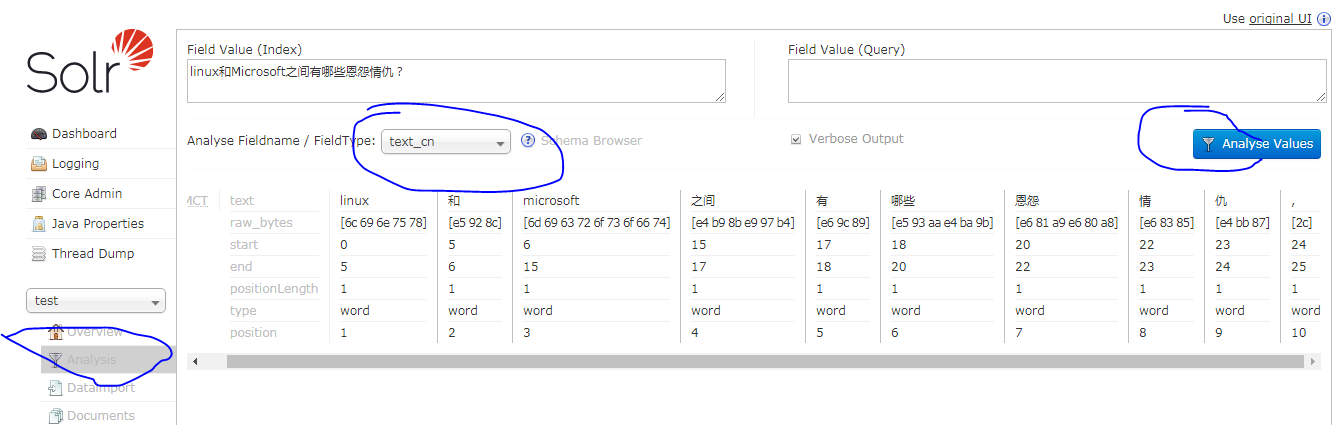
为什么要设置中文分词呢?
在说原因之前,我们先查看使用其他字段类型分析结果。
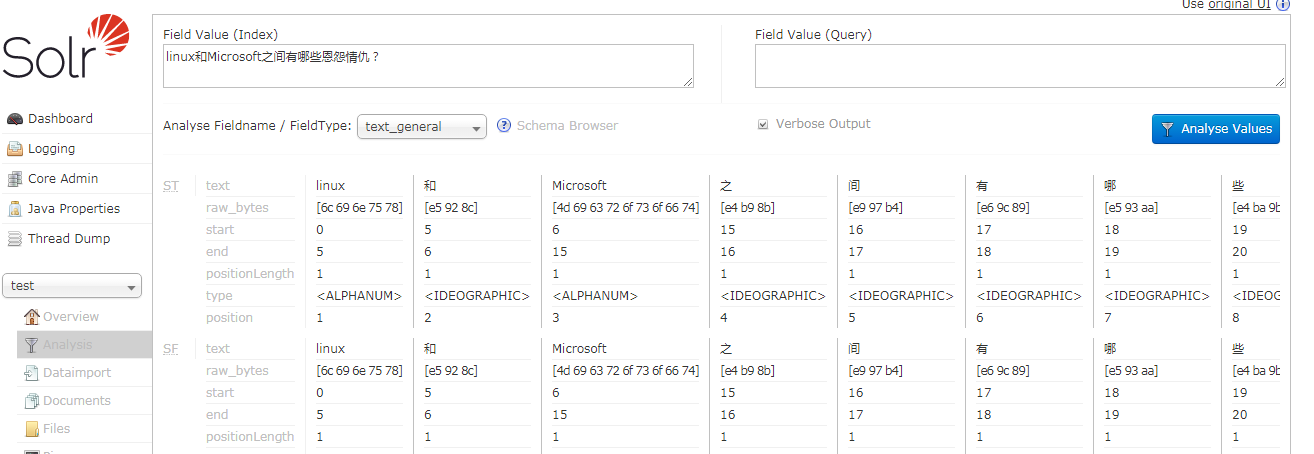
solr因为不支持中文,将会对内容时行最小分割,一个词一个索引,如果不使用中文分词,将产生大量的索引,以满足中文的搜索需求。(此为个人观点,未佐证,请务盲目相信)。
另外,如果不使用中文分词,那搜索建议只能返回单个中文字。新增一条文档记录,测试搜索建议的结果是否真是如此。
注意:测试这个功能时,请将含有中文的字段改为未设置中文分词的字段类型,更改后重启solr,并重新添加一条文档,文档中的中文词汇必需是 solr现有文档中不存在的词汇。
新增文档
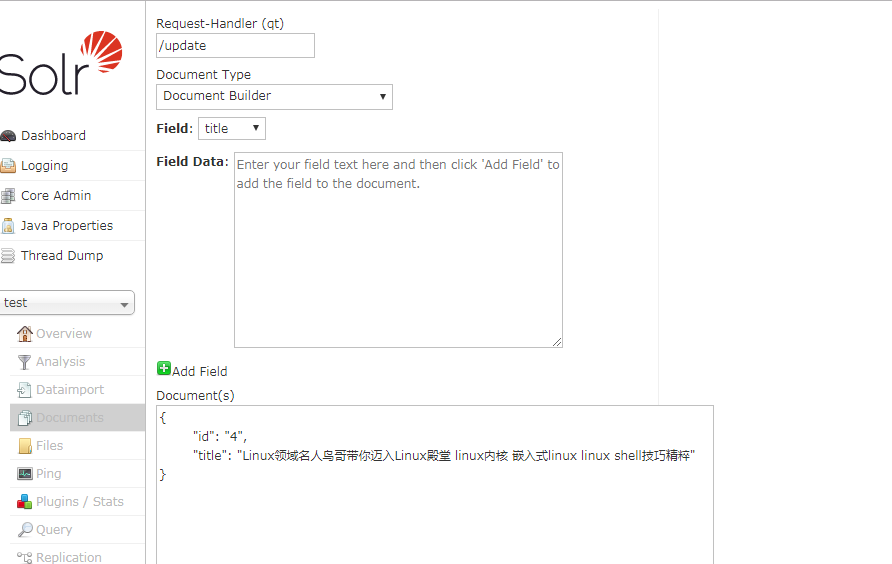
以下是浏览器搜索结果
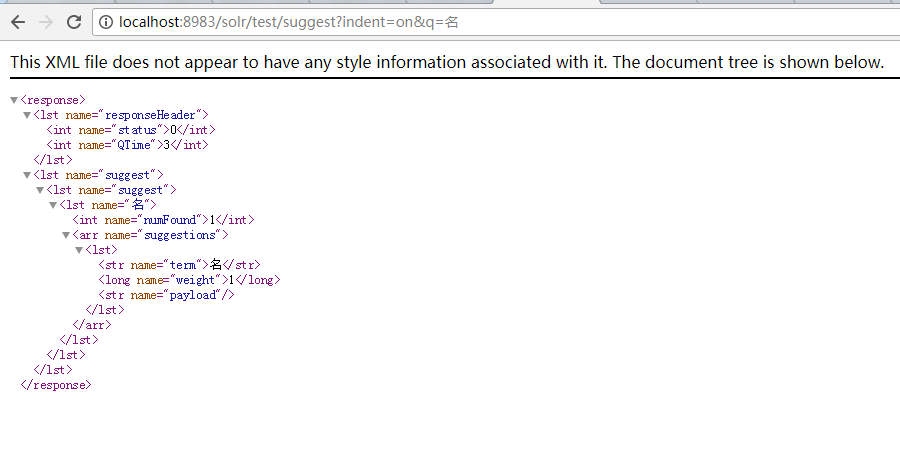
测试成功,我们将此文档删除,并重新添加这个文档,将字段类型更为中文分词类型,即本博文中新增的 text_cn 。
注意:删除文档之后,最好查询一下,solr中是还存在此文档,以防重复文档未被删除.
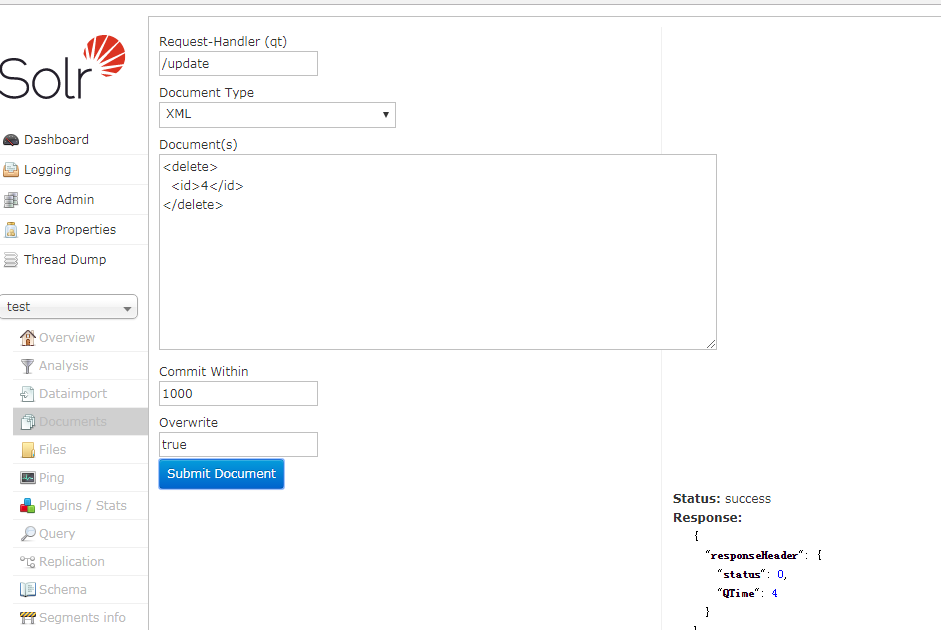
再次搜索
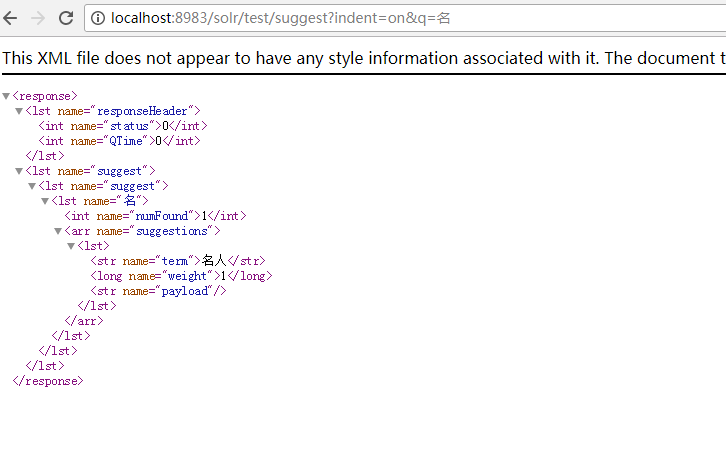
结语:水平有限,只能写这么多。如果有时间,我将持续更新此博文。
php使用solr全文搜索引擎的更多相关文章
- 指尖上的电商---(2)Solr全文搜索引擎的准备工作
Solr是一个基于Lucene的全文搜索引擎.提供了更丰富的搜索语言.更灵活的配置.更高的查询效率. 一句话.与Lucene相比.有过之而无不及.这一节里, 主要谈论两个知识点:Jdk的安装和Tomc ...
- 指尖上的电商---(3)Solr全文搜索引擎的配置
接上篇,Solr的准备工作完毕后,本节主要介绍Solr的安装,事实上Solr不须要安装.直接下载就能够了 1.Solr配置 下载地址 :http://lucene.apache.org/so ...
- 全文搜索引擎 ElasticSearch 还是 Solr?
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索 Solr,但是该 Solr 搜索云项目不稳定,经常查询不出来数据,需要手动全量同步,而且是其他团队在维护,依赖性太强,导致 Solr 服务 ...
- Spring Boot 全文搜索引擎 ElasticSearch
参考 全文搜索引擎ElasticSearch 还是Solr? - JaJian - 博客园
- 利用Lucene与Nutch构建简单的全文搜索引擎
文章地址 1.简介 本次实现分为两个部分,第一个部分是利用Lucene构建一个全文的搜索引擎,另外一部分则是利用Nutch实现同样的功能.由于Lucene并不是一个可以直接运行的程序,且不具备爬虫和文 ...
- 为什么要用全文搜索引擎:全文搜索引擎 VS 数据库管理系统
正文一:Full Text Search Engines vs. DBMS 发表于2009年 正文二:Elasticsearch - A High-Performance Full-Text Sea ...
- ElasticSearch全文搜索引擎
一.ElasticSearch简介 1.1 什么是ElasticSearch ElasticSearch简称ES,其中Elastic 从名字里我们可以知道,ES的特点就在于灵活的搜索,其实E ...
- 全文搜索引擎Elasticsearch详细介绍
我们生活中的数据总体分为两种:结构化数据 和 非结构化数据. 结构化数据:也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理.指具有固 ...
- net core 3.1使用ElasticSearch 全文搜索引擎
ElasticSearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上. Lucene 可以说是当下最先进.高性能.全功能的搜索引擎库,无论是开源还是私有. ...
随机推荐
- Spark LogisticRegression 逻辑回归之简介
LogisticRegression简介
- 7.5爬取猫眼Top100电影名单
2018-7-5 20:22:57 还有有一丢丢成就感!以后可以爬取简单网站了!比如妹子图片,只是现在不知道咋下载! 正则还是刚看,要多去用正则!正则很强大的东西! #!/usr/bin/env py ...
- vscode 的 vue模板
12 { "Print to console": { "prefix": "vue", "body": [ " ...
- Android所有Demo资源汇总,太全了(申明:来源于网络)
Android所有Demo资源汇总,太全了(申明:来源于网络) 地址:http://bbs.csdn.net/topics/391928947
- http://linux-mtd.infradead.org/doc/nand.html nand
http://linux-mtd.infradead.org/doc/nand.html
- Ansible自动化运维之介绍安装与简单使用
参考:http://blog.51cto.com/191226139/2066936 Ansible是什么 Ansible 简单的说是一个配置管理系统(configuration management ...
- oracle中如何生成awr报告
oracle中如何生成awr报告 1.进入数据库 sqlplus / as sysdba 2.查看用户 show parameter db_name 3.开始压测后执行 exec DBMS_WOR ...
- 精彩看点 | GIAC大会PPT+视频合集全量放送!
GIAC是中国互联网技术领域的行业盛事,每年从互联网架构最热门的系统架构设计.人工智能.机器学习.工程效率.区块链.分布式架构等领域甄选前沿有典型代表的技术创新及研发实践的架构案例,分享他们在本年度最 ...
- cadence xbl封装转AD
下载一个 软件 免费试用 导出到ad,出现一个脚本,脚本工程直接拉到ad里面,然后 有这两个文件,启动是有顺序的,顺序一旦错误就会产生大问题,没有任何反应 设置工程启动顺序,再次启动,出现打开文件窗口 ...
- [No0000178]改善C#程序的建议1:非用ICloneable不可的理由
好吧,我承认,这是一个反标题,实际的情况是:我找不到一个非用ICloneable不可的理由.事实上,接口ICloneable还会带来误解,因为它只有一个Clone方法. 我们都知道,对象的拷贝分为:浅 ...