python遍历目录os.walk(''d:\\test2",topdown=False)
os.walk(top, topdown=True, onerror=None, followlinks=False)遍历目录,topdown=false表示先返回目录,后返回文件
参数说明:
top:表示需要遍历的目录树的路径。
topdown的默认值是True,表示首先返回根目录树下的文件,然后遍历目录树下的子目录。值设为False时,则表示先遍历目录树下的子目录,返回子目录下的文件,最后返回根目录下的文件。
例子:可以看出,topdown设值不同,os.walk()返回的列表元素顺序不同(但不是相反),所以遍历后的结果也不同
topdown=False:
#encoding=utf-8
import os
r=os.walk('d:\\test2',topdown=False)
for i in r:
print i
结果:
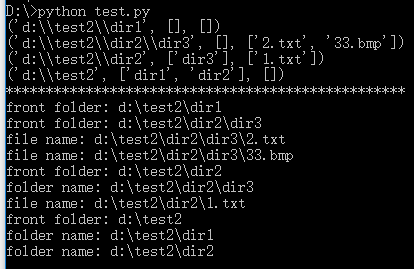
D:\>python test.py
('d:\\test2\\dir1', [], [])
('d:\\test2\\dir2\\dir3', [], ['2.txt', '33.bmp'])
('d:\\test2\\dir2', ['dir3'], ['1.txt'])
('d:\\test2', ['dir1', 'dir2'], [])
topdown=True:
import os
r=os.walk('d:\\test2',topdown=True)
for i in r:
print i
结果:
D:\>python test.py
('d:\\test2', ['dir1', 'dir2'], [])
('d:\\test2\\dir1', [], [])
('d:\\test2\\dir2', ['dir3'], ['1.txt'])
('d:\\test2\\dir2\\dir3', [], ['2.txt', '33.bmp'])
onerror的默认值是None,表示忽略文件遍历时产生的错误。如果不为空,则提供一个自定义函数提示错误信息后继续遍历或抛出异常中止遍历。
该函数返回一个列表,列表中的每一个元素都是一个元组,该元组有3个元素,分别表示每次遍历的路径名,目录列表和文件列表。
>>> r=os.walk('d:\\test2',topdown=False)
>>> r
<generator object walk at 0x0000000004C5D480>
>>> list(r)
[('d:\\test2\\dir1', [], []), ('d:\\test2\\dir2\\dir3', [], ['2.txt', '33.bmp']), ('d:\\test2\\dir2', ['dir3'], ['1.txt']), ('d:\\test2', ['dir1', 'dir2'], [])]
默认情况下,os.walk 不会遍历软链接指向的子目录,若有需要请将followlinks设定为true
用root,dirs,files三个变量遍历目录的的目录层级,目录层级的子目录,目录层级下的文件
for root,dirs,files in os.walk(r'd:\\test2',topdown=False):
root:表示当前遍历到哪一级目录了,目录的名字是谁
dirs:表示root下有哪些子目录
files:表示root下边有几个文件
topdown=False:
代码:
#encoding=utf-8
import os
r=os.walk('d:\\test2',topdown=False)
for i in r:
print i
print "*"*50
for root,dirs,files in os.walk('d:\\test2',topdown=False):
print "front folder:",root
for name in dirs:
print "folder name:",os.path.join(root,name)
for name in files:
print "file name:",os.path.join(root,name)
结果:
topdown=True:
代码:
#encoding=utf-8
import os
r=os.walk('d:\\test2',topdown=True)
for i in r:
print i
print "*"*50
for root,dirs,files in os.walk('d:\\test2',topdown=True):
print "front folder:",root
for name in dirs:
print "folder name:",os.path.join(root,name)
for name in files:
print "file name:",os.path.join(root,name)
结果:

python遍历目录os.walk(''d:\\test2",topdown=False)的更多相关文章
- python笔记4-遍历文件夹目录os.walk()
前言 如何遍历查找出某个文件夹内所有的子文件呢?并且找出某个后缀的所有文件 walk功能简介 1.os.walk() 方法用于通过在目录树种游走输出在目录中的文件名,向上或者向下. 2.walk()方 ...
- Python入门之os.walk()方法
os.walk方法,主要用来遍历一个目录内各个子目录和子文件. os.walk(top, topdown=True, onerror=None, followlinks=False) 可以得到一个三元 ...
- python中的os.walk
原文出处:https://www.jianshu.com/p/bbad16822eab python中os.walk是一个简单易用的文件.目录遍历器,可以帮助我们高效的处理文件.目录方面的事情. 1. ...
- 用Python遍历目录
用Python遍历指定目录下的文件,一般有两种常用方法,但它们都是基于Python的os模块.下面两种方法基于Python2.7,主要用到的函数如下: 1.os.listdir(path):列出目录下 ...
- python遍历目录文件脚本的示例
例子 自己写的一个Python遍历文件脚本,对查到的文件进行特定的处理.没啥技术含量,但是也记录一下吧. 代码如下 复制代码 #!/usr/bin/python# -*- coding: utf-8 ...
- Python遍历目录下xlsx文件
对指定目录下的指定类型文件进行遍历,可对文件名关键字进行条件筛选 返回值为文件地址的列表 import os # 定义一个函数,函数名字为get_all_excel,需要传入一个目录 def get_ ...
- Python遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例
遍历目录下所有文件的最后一行进行判断若错误及时邮件报警-案例: #-*- encoding: utf-8 -*- __author__ = 'liudong' import linecache,sys ...
- python学习之os.walk()
os.walk(top,topdown = True,onerror = None,followlinks = False) 参数 top -- 根目录下的每一个文件夹(包含它自己), 产生3-元组 ...
- Python 遍历目录下的子目录和文件
import os A: 遍历目录下的子目录和文件 for root,dirs ,files in os.walk(path) root:要访问的路径名 dirs:遍历目录下的子目录 files:遍历 ...
随机推荐
- 小程序支持打开APP了 还有小程序的标题栏也可以自定义
就在刚刚,小程序上线两个新能力——小程序支持打开APP了,小程序的标题栏区域开放自定义.用户可以在小程序里更方便地获取到APP的服务了——APP链接分享到微信,打开小程序页面后,用户从该小程序页面里, ...
- 浅谈IM软件client的断线重连、心跳和长在线
版权声明:原创文章,未经博主同意禁止转载.欢迎点击头像上方"郭晓东的专栏"查看专栏 https://blog.csdn.net/hherima/article/details/27 ...
- push到Git时常见的失败
之前学用git的时候,不想记命令,总是gui和bash交互的用,但是发现总出现push失败的问题,用gui来fetch的时候,显示下拉成功,但事实上并没有,这时候得在bash上用命令来下 ...
- C++ 常用算法
http://blog.csdn.net/jgzquanquan/article/details/77185711
- Jquery书写AJAX动态向页面form传数据,清空之前的数据
三种方式: 直接代码: 1.$("#mytable tr:gt(0)").remove(); 2.$("#mytable tr:not(:first)").em ...
- 堆(heap)、栈(stack)、方法区(method)
JVM内存分为3个区:堆(heap).栈(stack).方法区(method) 1.堆(heap):存储的全部对象,每个对象有个与之对应的class信息.即通过new关键字和构造器创建的对象.JVM只 ...
- Lua获取当前时间
更多好的文章就在 blog.haoitsoft.com,请大家多多支持! local getTime = os.date(“%c”); 其中的%c可以是以下的一种:(注意大小写) %a abbrevi ...
- 前端MD5加密【单向加密】
密码存储的方式: 密码该如何存储呢?按照安全性由低到高,有这样几种选择: 1.密码名文直接存储在系统中 2.密码经过对称加密后再存储 3.密码经过非对称加密后再存储 步骤: 1.用户端:用户提交用户名 ...
- JAVA代码MD5加密方法
PwdEncoder.java 接口类 package com.common.security.encoder; /** * 密码加密接口 */ public interface PwdEncoder ...
- [xdoj]1303jlz的刷题黑科技
先分析复杂度,给的数据是1e5的,那么我们至少需要一个nlogn的算法才可以.由于答案是一个数字,首先想到是二分法(一般答案是一个数字都可以通过二分法来完成) 下面是思路: 1.可以完成题目的条件是, ...