Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)
背景:
需要在spark2.2.0更新broadcast中的内容,网上也搜索了不少文章,都在讲解spark streaming中如何更新,但没有spark structured streaming更新broadcast的用法,于是就这几天进行了反复测试。经过了一下两个测试::Spark Streaming更新broadcast、Spark Structured Streaming更新broadcast。
1)Spark Streaming更新broadcast(可行)
def sparkStreaming(): Unit = {
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.
val conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(15))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream(ipAddr, 19999)
val mro = lines.map(row => {
val fields = row.split(",")
Mro(fields(0), fields(1))
})
val cellJoinMro = mro.transform(row => {
if (1 < 3) {
println("更新broadcast..." + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new java.util.Date()))
BroadcastWrapper.update(ssc.sparkContext)
}
var broadcastCellRes = BroadcastWrapper.getInstance(ssc.sparkContext)
row.map(row => {
val int_id: String = row.int_id
val rsrp: String = row.rsrp
val findResult: String = String.join(",", broadcastCellRes.value.get(int_id).get)
val timeStamps: String = String.join(",", findResult)
CellJoinMro(int_id, rsrp, timeStamps)
})
})
cellJoinMro.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
import org.apache.spark.SparkContext
import org.apache.spark.broadcast.Broadcast
object BroadcastWrapper {
@volatile private var instance: Broadcast[Map[String, java.util.List[String]]] = null
private val baseDir = "/user/my/streaming/test/"
def loadData(): Map[String, java.util.List[String]] = {
val files = HdfsUtil.getFiles(baseDir)
var latest: String = null
for (key <- files.keySet) {
if (latest == null) latest = key
else if (latest.compareTo(key) <= 0) latest = key
}
val filePath = baseDir + latest
val map = HdfsUtil.getFileContent(filePath)
map
}
def update(sc: SparkContext, blocking: Boolean = false): Unit = {
if (instance != null)
instance.unpersist(blocking)
instance = sc.broadcast(loadData())
}
def getInstance(sc: SparkContext): Broadcast[Map[String, java.util.List[String]]] = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.broadcast(loadData)
}
}
}
instance
}
}
import java.io.{BufferedReader, InputStreamReader}
import java.text.SimpleDateFormat
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.fs.FileSystem
import scala.collection.mutable
object HdfsUtil {
private val sdf = new SimpleDateFormat("yyyy-MM-dd 00:00:00")
def getFiles(path: String): mutable.Map[String, String] = {
val fileItems = new mutable.LinkedHashMap[String, String]
val fs = FileSystem.get(new Configuration())
val files = fs.listStatus(new Path(path))
var pathStr: String = ""
for (file <- files) {
if (file.isFile) {
pathStr = file.getPath().getName()
fileItems.put(pathStr.split("/")(pathStr.split("/").length - 1), pathStr)
}
}
fs.close()
fileItems
}
def getFileContent(filePath: String): Map[String, java.util.List[String]] = {
val map = new mutable.LinkedHashMap[String, java.util.List[String]]
val fs = FileSystem.get(new Configuration())
val path = new Path(filePath)
if (fs.exists(path)) {
val bufferedReader = new BufferedReader(new InputStreamReader(fs.open(path)))
var line: String = null
line = bufferedReader.readLine()
while (line != null) {
val fields: Array[String] = line.split(",")
val int_id: String = fields(0)
val date = new java.util.Date(java.lang.Long.valueOf(fields(2)))
val time = sdf.format(date)
System.out.println(line + "(" + time + ")")
if (!map.keySet.contains(int_id))
map.put(int_id, new java.util.ArrayList[String])
map.get(int_id).get.add(time)
line = bufferedReader.readLine()
}
map.toMap
} else {
throw new RuntimeException("the file do not exists")
}
}
}
测试日志:
18/11/19 16:50:15 INFO scheduler.DAGScheduler: Job 2 finished: print at App.scala:59, took 0.080061 s
-------------------------------------------
Time: 1542617415000 ms
-------------------------------------------
CellJoinMro(2,333,2018-11-05 00:00:00)
。。。。
18/11/19 16:50:15 INFO storage.BlockManagerInfo: Removed input-0-1542617392400 on 10.60.0.11:1337 in memory (size: 12.0 B, free: 456.1 MB)
》》》》》》》》》》》》》》》》此时路径上传新资源文件》》》》》》》》》》》》》》》》》》》》》》
更新broadcast...2018-11-19 16:50:30
。。。
1,111,1541433600000(2018-11-06 00:00:00)
2,222,1541433600000(2018-11-06 00:00:00)
3,333,1541433600000(2018-11-06 00:00:00)
18/11/19 16:50:30 INFO memory.MemoryStore: Block broadcast_5 stored as values in memory (estimated size 688.0 B, free 456.1 MB)
。。
18/11/19 16:50:30 INFO scheduler.JobScheduler: Starting job streaming job 1542617430000 ms.0 from job set of time 1542617430000 ms
-------------------------------------------
Time: 1542617430000 ms
------------------------------------------- 18/11/19 16:50:30 INFO scheduler.JobScheduler: Finished job streaming job 1542617430000 ms.0 from job set of time 1542617430000 ms
。。。。
18/11/19 16:50:32 WARN storage.BlockManager: Block input-0-1542617432400 replicated to only 0 peer(s) instead of 1 peers
18/11/19 16:50:32 INFO receiver.BlockGenerator: Pushed block input-0-1542617432400
更新broadcast...2018-11-19 16:50:45
1,111,1541433600000(2018-11-06 00:00:00)
2,222,1541433600000(2018-11-06 00:00:00)
3,333,1541433600000(2018-11-06 00:00:00)
18/11/19 16:50:45 INFO memory.MemoryStore: Block broadcast_6 stored as values in memory (estimated size 688.0 B, free 456.1 MB)
。。。。
18/11/19 16:50:45 INFO scheduler.DAGScheduler: Job 3 finished: print at App.scala:59, took 0.066975 s
-------------------------------------------
Time: 1542617445000 ms
-------------------------------------------
CellJoinMro(3,4444,2018-11-06 00:00:00) 18/11/19 16:50:45 INFO scheduler.JobScheduler: Finished job streaming job 1542617445000 ms.0 from job set of time 1542617445000 ms
18/11/19 16:50:45 INFO scheduler.JobScheduler: Total delay: 0.367 s for time 1542617445000 ms (execution: 0.083 s)
18/11/19 16:50:45 INFO rdd.MapPartitionsRDD: Removing RDD 9 from persistence list
日志分析:
每个batch都执行transform中的更新broadcast代码,而且也执行了broadcast获取代码。因此,每次都可进行更新broadcast内容,并且获取到broadcast中的内容。
2)Spark Structured Streaming更新broadcast(不可行【可行】)
目前测试可行请参考《Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)》
def sparkStructuredStreaming(): Unit = {
val spark = SparkSession.builder.appName("Test_Broadcast_ByScala_App").getOrCreate()
spark.streams.addListener(new StreamingQueryListener {
override def onQueryStarted(event: StreamingQueryListener.QueryStartedEvent): Unit = {
println("*************** onQueryStarted ***************")
}
override def onQueryProgress(event: StreamingQueryListener.QueryProgressEvent): Unit = {
println("*************** onQueryProgress ***************")
// 这段代码可以把broadcast对象更新成功,但是spark structured streaming内部读取到的broadcast对象数据依然是老数据。
// BroadcastWrapper.update(spark.sparkContext, true)
println("*************** onQueryProgress update broadcast " + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new java.util.Date()))
}
override def onQueryTerminated(event: StreamingQueryListener.QueryTerminatedEvent): Unit = {
println("*************** onQueryTerminated ***************")
}
})
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream.format("socket").option("host", ipAddr).option("port", 19999).load()
import spark.implicits._
val mro = lines.as(Encoders.STRING).map(row => {
val fields = row.split(",")
Mro(fields(0), fields(1))
})
val cellJoinMro = mro.transform(row => {
// 这段代码在第一次触发时执行,之后触发就不再执行。
println("更新broadcast..." + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new java.util.Date()))
if (1 < 3) {
println("------------------------1111-----------------------------")
BroadcastWrapper.update(spark.sparkContext)
}
var broadcastCellRes = BroadcastWrapper.getInstance(spark.sparkContext)
row.map(row => {
val int_id: String = row.int_id
val rsrp: String = row.rsrp
val findResult: String = String.join(",", broadcastCellRes.value.get(int_id).get)
val timeStamps: String = String.join(",", findResult)
CellJoinMro(int_id, rsrp, timeStamps)
})
})
val query = cellJoinMro.writeStream.format("console")
.outputMode("update")
.trigger(Trigger.ProcessingTime(15, TimeUnit.SECONDS))
.start()
query.awaitTermination()
}
执行日志:
// :: INFO state.StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
// :: WARN streaming.TextSocketSourceProvider: The socket source should not be used for production applications! It does not support recovery.
更新broadcast...-- ::
-----------------------------------------------------
,,(-- ::)
,,(-- ::)
,,(-- ::)
.....
-------------------------------------------
Batch:
-------------------------------------------
// :: INFO codegen.CodeGenerator: Code generated in 82.760622 ms
。。。。
// :: INFO scheduler.DAGScheduler: Job finished: start at App.scala:, took 4.215709 s
+------+----+-------------------+
|int_id|rsrp| timestamp|
+------+----+-------------------+
| | |-- ::|
+------+----+-------------------+ // :: INFO streaming.StreamExecution: Committed offsets for batch . Metadata OffsetSeqMetadata(,,Map(spark.sql.shuffle.partitions -> )) 此时更新资源文件,附加2018-11-06的资源文件。
-------------------------------------------
Batch:
-------------------------------------------
// :: INFO spark.SparkContext: Starting job: start at App.scala:
。。。
// :: INFO scheduler.DAGScheduler: Job finished: start at App.scala:, took 3.068106 s
+------+----+-------------------+
|int_id|rsrp| timestamp|
+------+----+-------------------+
| | |-- ::|
+------+----+-------------------+
日志分析:
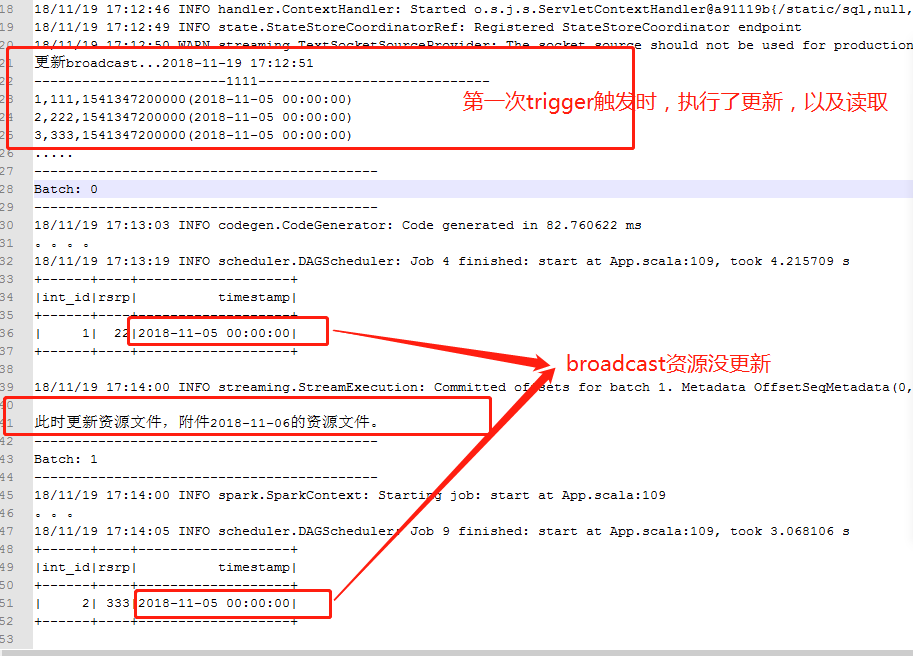
测试结论:
Spark Streaming更新broadcast(可行)、Spark Structured Streaming更新broadcast(不可行,也可行,如果按照上边spark streaming的方法是不行的,但是有其他方案),原因Spark Streaming的执行引擎是Spark Engine,是代码执行,在算子的构造函数中可以访问SparkContext,SparkSession,而且这些类构造函数是可以每次都执行的。
而Spark Structured Streaming的执行引擎是Spark Sql Engine,是把代码优化为Spark Sql Engine希望的格式去执行,不可以在每次trigger事件触发都执行执行块以外的代码,因此这些类构造函数块代码只能执行一次,执行块类似MapFunction的call()函数内,不允许访问SparkContext,SparkSession对象,因此无处进行每次trigger都进行broadcast更新。
那么,如何在Spark Struectured Streaming中实现更新broadcast的方案,升级spark版本,从spark2.3.0开始,spark structured streaming支持了stream join stream(请参考《Spark2.3(三十七):Stream join Stream(res文件每天更新一份)》)。
实际上,@2019-03-27测试结果中可以得到新的方案,也是使用broadcast方式更新得到方案。目前测试可行请参考《Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)》
Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)的更多相关文章
- Spark2.x(六十):在Structured Streaming流处理中是如何查找kafka的DataSourceProvider?
本章节根据源代码分析Spark Structured Streaming(Spark2.4)在进行DataSourceProvider查找的流程,首先,我们看下读取流数据源kafka的代码: Spar ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十九):推送avro格式数据到topic,并使用spark structured streaming接收topic解析avro数据
推送avro格式数据到topic 源代码:https://github.com/Neuw84/structured-streaming-avro-demo/blob/master/src/main/j ...
- Spark2.x(六十一):在Spark2.4 Structured Streaming中Dataset是如何执行加载数据源的?
本章主要讨论,在Spark2.4 Structured Streaming读取kafka数据源时,kafka的topic数据是如何被执行的过程进行分析. 以下边例子展开分析: SparkSession ...
- Structured Streaming Programming Guide结构化流编程指南
目录 Overview Quick Example Programming Model Basic Concepts Handling Event-time and Late Data Fault T ...
- Structured streaming
Structured streaming是spark 2.0以后新增的用于实时处理的技术.与spark streaming不同的是,Structured streaming打开了数据源到数据落地之间的 ...
- Structured Streaming编程 Programming Guide
Structured Streaming编程 Programming Guide Overview Quick Example Programming Model Basic Concepts Han ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
- Spark2.3(三十五)Spark Structured Streaming源代码剖析(从CSDN和Github中看到别人分析的源代码的文章值得收藏)
从CSDN中读取到关于spark structured streaming源代码分析不错的几篇文章 spark源码分析--事件总线LiveListenerBus spark事件总线的核心是LiveLi ...
随机推荐
- 【python】中文提取,判断,分词
参考: http://www.cnblogs.com/kaituorensheng/p/3595879.html https://github.com/fxsjy/jieba 判断是否包含中文 def ...
- composer卸载重装
$ composer remove phpunit/phpunit --dev $ composer require phpunit/phpunit --dev
- Jquery----对文档操作
jquery对css操作: 1.CSS .css() - .css("color") -> 获取color css值 - .css("color", &q ...
- 解析Linux下\r\n的问题(回车和换行)
http://www.jb51.net/article/37389.htm 深入解析Linux下\r\n的问题 http://www.ruanyifeng.com/blog/2006/04/post_ ...
- javah命令的使用
背景 java开发中如果使用到JNI,则难免需要使用javah来生成C++或C的头文件信息,下面小编就直接说说javah的命令: 第一种:直接cd到当前程序的target/class目录下(maven ...
- URAL - 1495 One-two, One-two 2
URAL - 1495 这是在dp的专题里写了,想了半天的dp,其实就是暴力... 题目大意:给你一个n,问你在30位以内有没有一个只由1或2 构成的数被 n 整除,如果 有则输出最小的那个,否则输出 ...
- Storm中关于Topology的设计
一:介绍Storm设计模型 1.Topology Storm对任务的抽象,其实 就是将实时数据分析任务 分解为 不同的阶段 点: 计算组件 Spout Bolt 边: 数据流向 数据从上 ...
- Session丢失的解决方法
1.修改配置文件 <sessionState mode="StateServer" stateConnectionString="tcpip=127.0.0.1:4 ...
- mysql-ubuntu卸载安装mysql
安装MySQL sudo apt-get install mysql-server mysql-client 查看状态 是否是运行中 sudo service mysql status 启动MySQL ...
- git 详细教程和常用操作指令
git 内部工作原理图 如上图,git 一般可以分为三个区:工作区.暂存区.版本库,通常类似 git add等命令都是与index 暂存区的交互,git commit指令则是 index 与版本库的交 ...