机器学习: 共轭梯度算法(PCG)
今天介绍数值计算和优化方法中非常有效的一种数值解法,共轭梯度法。我们知道,在解大型线性方程组的时候,很少会有一步到位的精确解析解,一般都需要通过迭代来进行逼近,而 PCG 就是这样一种迭代逼近算法。
我们先从一种特殊的线性方程组的定义开始,比如我们需要解如下的线性方程组:
这里的 A(n×n)" role="presentation" style="position: relative;">A(n×n)A(n×n) 是对称,正定矩阵, b(n×1)" role="presentation" style="position: relative;">b(n×1)b(n×1) 同样也是已知的列向量,我们需要通过 A" role="presentation" style="position: relative;">AA 和 b" role="presentation" style="position: relative;">bb 来求解 x(n×1)" role="presentation" style="position: relative;">x(n×1)x(n×1), 这其实是我们熟知的一些线性系统的表达式。
直接求解
首先,我们来看一种直观的解法,我们定义满足如下关系的向量为关于 矩阵 A" role="presentation" style="position: relative;">AA 的共轭向量,
因为矩阵 A" role="presentation" style="position: relative;">AA 是对称正定矩阵,所以矩阵 A" role="presentation" style="position: relative;">AA 定义了一个内积空间:
基于此,我们可以定义一组向量 P" role="presentation" style="position: relative;">PP
其中的向量 p1" role="presentation" style="position: relative;">p1p1 , p2" role="presentation" style="position: relative;">p2p2, … , pn" role="presentation" style="position: relative;">pnpn 都是互为共轭的,那么 P" role="presentation" style="position: relative;">PP 构成了 Rn" role="presentation" style="position: relative;">RnRn 空间的一个基,上述方程的解 x∗" role="presentation" style="position: relative;">x∗x∗ 可以表示成 P" role="presentation" style="position: relative;">PP 中向量的线性组合:
根据上面的表达式,我们可以得到:
这意味着:
所以,如果我们要直接求解的,可以先对矩阵 A" role="presentation" style="position: relative;">AA 进行特征值分解,求出一系列的共轭向量,然后求出系数,最后可以得到方程的解 x∗" role="presentation" style="position: relative;">x∗x∗
迭代求解
上面的方法已经说明,x∗" role="presentation" style="position: relative;">x∗x∗ 是一系列共轭向量 p" role="presentation" style="position: relative;">pp 的线性组合,学过 PCA 的都知道,可以用前面占比高的向量组合进行逼近,而不需要把所有的向量都组合到一起,PCG 也是用到了这种思想,通过仔细的挑选共轭向量 p" role="presentation" style="position: relative;">pp 来重建方程的解 x∗" role="presentation" style="position: relative;">x∗x∗。
我们先来看下面的一个方程:
对上面的方程求导,我们可以得到:
可以看到,方程的一阶导数就是我们需要解的线性方程组,令一阶导数为 0,那么我们需要解的就是这样一个线性方程组了。
假设我们随机定义 x" role="presentation" style="position: relative;">xx 的一个初始向量为 x0" role="presentation" style="position: relative;">x0x0,那么我们可以定义第一个共轭向量为 p0=b−Ax0" role="presentation" style="position: relative;">p0=b−Ax0p0=b−Ax0, 后续的基向量都是和梯度共轭的,所以称为共轭梯度法。
下面给出详细的算法流程:
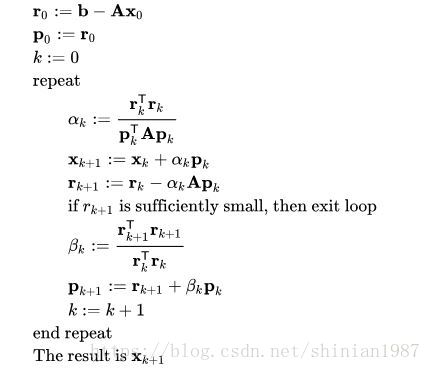
而 preconditioned conjugate gradient method 与共轭梯度法的不同之处在于预先定义了一个特殊矩阵 M" role="presentation" style="position: relative;">MM:

参考来源:wiki 百科
https://en.wikipedia.org/wiki/Conjugate_gradient_method#The_preconditioned_conjugate_gradient_method
机器学习: 共轭梯度算法(PCG)的更多相关文章
- 共轭梯度算法求最小值-scipy
# coding=utf-8 #共轭梯度算法求最小值 import numpy as np from scipy import optimize def f(x, *args): u, v = x a ...
- 机器学习中的算法-决策树模型组合之随机森林与GBDT
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT 版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使 ...
- [机器学习Lesson3] 梯度下降算法
1. Gradient Descent(梯度下降) 梯度下降算法是很常用的算法,可以将代价函数J最小化.它不仅被用在线性回归上,也被广泛应用于机器学习领域中的众多领域. 1.1 线性回归问题应用 我们 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- 机器学习十大算法之KNN(K最近邻,k-NearestNeighbor)算法
机器学习十大算法之KNN算法 前段时间一直在搞tkinter,机器学习荒废了一阵子.如今想重新写一个,发现遇到不少问题,不过最终还是解决了.希望与大家共同进步. 闲话少说,进入正题. KNN算法也称最 ...
- 机器学习十大算法 之 kNN(一)
机器学习十大算法 之 kNN(一) 最近在学习机器学习领域的十大经典算法,先从kNN开始吧. 简介 kNN是一种有监督学习方法,它的思想很简单,对于一个未分类的样本来说,通过距离它最近的k个" ...
- Mahout 系列之----共轭梯度
无预处理共轭梯度 要求解线性方程组 ,稳定双共轭梯度法从初始解 开始按以下步骤迭代: 任意选择向量 使得 ,例如, 对 若 足够精确则退出 预处理共轭梯度 预处理通常被用来加速迭代方法的收敛.要使用预 ...
随机推荐
- Spring循环依赖
Spring-bean的循环依赖以及解决方式 Spring里面Bean的生命周期和循环依赖问题 什么是循环依赖? 循环依赖其实就是循环引用,也就是两个或者两个以上的bean互相持有对方,最终形成闭环. ...
- ActiveMQ queue和topic,持久订阅和非持久订阅
消息的 destination 分为 queue 和 topic,而消费者称为 subscriber(订阅者).queue 中的消息只会发送给一个订阅者,而 topic 的消息,会发送给每一个订阅者. ...
- CAD绘制室外台阶步骤5.4
1.在CAD的平面上用PL命令绘制台阶,如图: 绘制好了之后.进入三维模型,“工具""移位”选择台阶,回车,"Z"回车,输入数值“-450”如图 2.输入命令“ ...
- html盒子水平和垂直居中
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- laravel的validation 中文 文件
使用方法: 直接替换resources/lang/en/validation.php中的内容 <?php return [ 'unique' => ':attribute 已存在', 'a ...
- 1-MAVEN 仓库
本地资源库 MAVEN的本地资源库是用来存储所有项目的依赖关系(插件和其他文件,这个文件被MAVEN 下载到本地文件中.) 可以通过修改MAVEN安装目录下conf/setting.xml配置 ...
- MyBatis 为什么需要通用 Mapper ?
一.通用 Mapper 的用途 ? 我个人最早用 MyBatis 时,先是完全手写,然后用上了 MyBatis 代码生成器(简称为 MBG),在使用 MBG 过程中,发现一个很麻烦的问题,如果数据库字 ...
- day06字典类型
基本使用: 1.用途:用来存多个(不同种类的)值 2定义方式:在{}内用逗号分隔开多个key:value的元素,其中value可以是任意数据类型,而key的功能通常是用来描述value的,所以key通 ...
- 初学Linux系统最应该做对的4件事情[长文]
“闲来无事,逛逛贴吧”已经是本人无事消磨时间的最佳选择了.五花八门的问题,各式各样的回答,总能给自己带来无限的欢乐.当然也有些问题值得自己去思考或者回答.之前就有人在贴吧里问到“Linux好难啊!该怎 ...
- Java反射《四》获取方法
package com.study.reflect; import java.lang.reflect.InvocationTargetException; import java.lang.refl ...