Leetcode: LFU Cache && Summary of various Sets: HashSet, TreeSet, LinkedHashSet
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the following operations: get and set. get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
set(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted. Follow up:
Could you do both operations in O(1) time complexity? Example: LFUCache cache = new LFUCache( 2 /* capacity */ ); cache.set(1, 1);
cache.set(2, 2);
cache.get(1); // returns 1
cache.set(3, 3); // evicts key 2
cache.get(2); // returns -1 (not found)
cache.get(3); // returns 3.
cache.set(4, 4); // evicts key 1.
cache.get(1); // returns -1 (not found)
cache.get(3); // returns 3
cache.get(4); // returns 4
referred to: https://discuss.leetcode.com/topic/69137/java-o-1-accept-solution-using-hashmap-doublelinkedlist-and-linkedhashset
Two HashMaps are used, one to store <key, value> pair, another store the <key, node>.
I use double linked list to keep the frequent of each key. In each double linked list node, keys with the same count are saved using java built in LinkedHashSet. This can keep the order.
Every time, one key is referenced, first find the current node corresponding to the key, If the following node exist and the frequent is larger by one, add key to the keys of the following node, else create a new node and add it following the current node.
All operations are guaranteed to be O(1).
public class LFUCache {
int cap;
ListNode head;
HashMap<Integer, Integer> valueMap;
HashMap<Integer, ListNode> nodeMap;
public LFUCache(int capacity) {
this.cap = capacity;
this.head = null;
this.valueMap = new HashMap<Integer, Integer>();
this.nodeMap = new HashMap<Integer, ListNode>();
}
public int get(int key) {
if (valueMap.containsKey(key)) {
increaseCount(key);
return valueMap.get(key);
}
return -1;
}
public void set(int key, int value) {
if (cap == 0) return;
if (valueMap.containsKey(key)) {
valueMap.put(key, value);
increaseCount(key);
}
else {
if (valueMap.size() < cap) {
valueMap.put(key, value);
addToHead(key);
}
else {
removeOld();
valueMap.put(key, value);
addToHead(key);
}
}
}
public void increaseCount(int key) {
ListNode node = nodeMap.get(key);
node.keys.remove(key);
if (node.next == null) {
node.next = new ListNode(node.count+1);
node.next.prev = node;
node.next.keys.add(key);
}
else if (node.next.count == node.count + 1) {
node.next.keys.add(key);
}
else {
ListNode newNode = new ListNode(node.count+1);
newNode.next = node.next;
node.next.prev = newNode;
newNode.prev = node;
node.next = newNode;
node.next.keys.add(key);
}
nodeMap.put(key, node.next);
if (node.keys.size() == 0) remove(node);
}
public void remove(ListNode node) {
if (node.next != null) {
node.next.prev = node.prev;
}
if (node.prev != null) {
node.prev.next = node.next;
}
else { // node is head
head = head.next;
}
}
public void addToHead(int key) {
if (head == null) {
head = new ListNode(1);
head.keys.add(key);
}
else if (head.count == 1) {
head.keys.add(key);
}
else {
ListNode newHead = new ListNode(1);
head.prev = newHead;
newHead.next = head;
head = newHead;
head.keys.add(key);
}
nodeMap.put(key, head);
}
public void removeOld() {
if (head == null) return;
int old = 0;
for (int keyInorder : head.keys) {
old = keyInorder;
break;
}
head.keys.remove(old);
if (head.keys.size() == 0) remove(head);
valueMap.remove(old);
nodeMap.remove(old);
}
public class ListNode {
int count;
ListNode prev, next;
LinkedHashSet<Integer> keys;
public ListNode(int freq) {
count = freq;
keys = new LinkedHashSet<Integer>();
prev = next = null;
}
}
}
/**
* Your LFUCache object will be instantiated and called as such:
* LFUCache obj = new LFUCache(capacity);
* int param_1 = obj.get(key);
* obj.set(key,value);
*/
Summary of LinkedHashSet: http://www.programcreek.com/2013/03/hashset-vs-treeset-vs-linkedhashset/
A Set contains no duplicate elements. That is one of the major reasons to use a set. There are 3 commonly used implementations of Set: HashSet, TreeSet and LinkedHashSet. When and which to use is an important question. In brief, if you need a fast set, you should use HashSet; if you need a sorted set, then TreeSet should be used; if you need a set that can be store the insertion order, LinkedHashSet should be used.
1. Set Interface
Set interface extends Collection interface. In a set, no duplicates are allowed. Every element in a set must be unique. You can simply add elements to a set, and duplicates will be removed automatically.
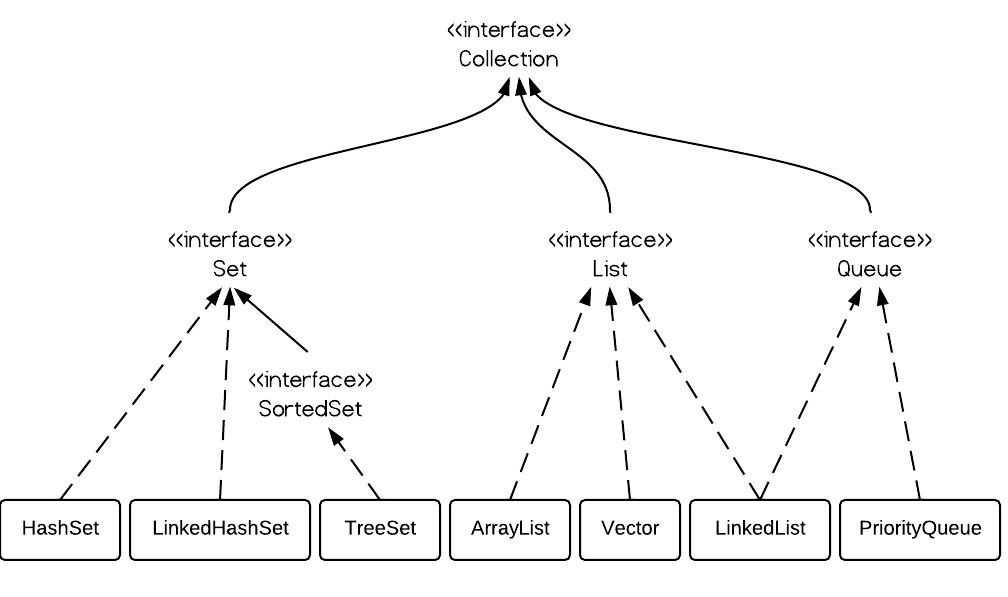
2. HashSet vs. TreeSet vs. LinkedHashSet
HashSet is Implemented using a hash table. Elements are not ordered. The add, remove, and contains methods have constant time complexity O(1).
TreeSet is implemented using a tree structure(red-black tree in algorithm book). The elements in a set are sorted, but the add, remove, and contains methods has time complexity of O(log (n)). It offers several methods to deal with the ordered set like first(), last(), headSet(), tailSet(), etc.
LinkedHashSet is between HashSet and TreeSet. It is implemented as a hash table with a linked list running through it, so it provides the order of insertion. The time complexity of basic methods is O(1).
3. TreeSet Example
TreeSet<Integer> tree = new TreeSet<Integer>(); |
Output is sorted as follows:
Tree set data: 12 34 45 63
4. HashSet Example
HashSet<Dog> dset = new HashSet<Dog>(); |
Output:
5 3 2 1 4
Note the order is not certain.
5. LinkedHashSet Example
LinkedHashSet<Dog> dset = new LinkedHashSet<Dog>(); |
The order of the output is certain and it is the insertion order:
2 1 3 5 4
Leetcode: LFU Cache && Summary of various Sets: HashSet, TreeSet, LinkedHashSet的更多相关文章
- Set集合[HashSet,TreeSet,LinkedHashSet],Map集合[HashMap,HashTable,TreeMap]
------------ Set ------------------- 有序: 根据添加元素顺序判定, 如果输出的结果和添加元素顺序是一样 无序: 根据添加元素顺序判定,如果输出的结果和添加元素的顺 ...
- [LeetCode] LFU Cache 最近最不常用页面置换缓存器
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the f ...
- LeetCode LFU Cache
原题链接在这里:https://leetcode.com/problems/lfu-cache/?tab=Description 题目: Design and implement a data str ...
- Java容器---Set: HashSet & TreeSet & LinkedHashSet
1.Set接口概述 Set 不保存重复的元素(如何判断元素相同呢?).如果你试图将相同对象的多个实例添加到Set中,那么它就会阻止这种重复现象. Set中最常被使用的是测试归属性,你可以 ...
- [LeetCode] 460. LFU Cache 最近最不常用页面置换缓存器
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the f ...
- leetcode 146. LRU Cache 、460. LFU Cache
LRU算法是首先淘汰最长时间未被使用的页面,而LFU是先淘汰一定时间内被访问次数最少的页面,如果存在使用频度相同的多个项目,则移除最近最少使用(Least Recently Used)的项目. LFU ...
- [LeetCode] LRU Cache 最近最少使用页面置换缓存器
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the fol ...
- LeetCode Monotone Stack Summary 单调栈小结
话说博主在写Max Chunks To Make Sorted II这篇帖子的解法四时,写到使用单调栈Monotone Stack的解法时,突然脑中触电一般,想起了之前曾经在此贴LeetCode Al ...
- LFU Cache
2018-11-06 20:06:04 LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”. ...
随机推荐
- [工作中的设计模式]迭代子模式Iterator
一.模式解析 迭代子模式又叫游标(Cursor)模式,是对象的行为模式.迭代子模式可以顺序地访问一个聚集中的元素而不必暴露聚集的内部表象 1.迭代子模式一般用于对集合框架的访问,常用的集合框架为lis ...
- iOS 应用内的系统复制粘贴菜单显示的语言非中文
在应用的 Info.plist 文件中添加以下代码: <key>CFBundleLocalizations</key> <array> <string> ...
- SOAPUI使用教程-验证SOAP服务
当soapUI创建一个功能性TestCase 一个很常见的场景是你想一些SOAP / WSDL服务验证响应检查返回正确的结果. 一旦你导入了您想要测试的WSDL服务这样做很容易: 添加一个新的SOAP ...
- mysql导入数据到oracle中
mysql导入数据到oracle中. 建立Oracle表: CREATE TABLE "GG_USER" ( "USERID" BYTE) NOT NULL, ...
- Java_动态编译总结
不多说直接上代码: 动态编译的主类: package com.lkb.autoCode.util; import com.lkb.autoCode.constant.AutoCodeConstant; ...
- java强制类型转换
在Java项目的实际开发和应用中,常常需要用到将对象转为String这一基本功能.本文将对常用的转换方法进行一个总结.常用的方法有Object.toString(),(String)要转换的对象,St ...
- 【转】 Camera模仿3D效果的小例子(图片无限旋转)
import android.content.Context; import android.graphics.Bitmap; import android.graphics.BitmapFactor ...
- HDU3371 最小生成树
Connect the Cities Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Other ...
- JavaScript之闭包就是个子公司
在计算机科学中,闭包(Closure)是词法闭包(Lexical Closure)的简称,是引用了自由变量的函数.这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外.所以,有 ...
- python 安装nltk,使用(英文分词处理,词干化等)(Green VPN)
安装pip命令之后: sudo pip install -U pyyaml nltk import nltk nltk.download() 等待ing 目前访问不了,故使用Green VPN htt ...