SSM框架、Druid连接池实现多数据源配置(已上线使用)
总体大概流程:
1、配置数据源、账密(账密一致,文章不多阐述)
driverClassName = com.mysql.jdbc.Driver
validationQuery = SELECT 1 FROM DUAL
# 腕表
jdbc_url = jdbc:mysql://127.0.0.1:3306/do_wave_new?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true # 车机
jdbc_url2 = jdbc:mysql://127.0.0.1:3306/car_internet?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true jdbc_username = root
jdbc_password = dowave!@#888
jdbc_initialSize = 2 jdbc_minIdle = 1 jdbc_maxActive = 500 jdbc_maxWait = 1800000
2、Mybytis.xml 配置数据源
<!-- 配置数据源 -->
<bean name="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="${driverClassName}" />
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_username}" />
<property name="password" value="${jdbc_password}" /> <!-- 初始化连接大小 -->
<property name="initialSize" value="${jdbc_initialSize}" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="${jdbc_maxActive}" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="${jdbc_minIdle}" />
<!-- 获取连接最大等待时间 毫秒-->
<property name="maxWait" value="${jdbc_maxWait}" /> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="33" /> <property name="validationQuery" value="${validationQuery}" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" /> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" /> <!-- 超过时间限制是否回收: 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 超时时间:1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" /> <!-- 监控数据库 -->
<!-- <property name="filters" value="mergeStat" /> -->
<property name="filters" value="stat" /> <!-- 非公平锁 -->
<property name="useUnfairLock" value="true" />
</bean> <!-- 配置数据源 -->
<bean name="dataSource2" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="${driverClassName}" />
<property name="url" value="${jdbc_url2}" />
<property name="username" value="${jdbc_username}" />
<property name="password" value="${jdbc_password}" /> <!-- 初始化连接大小 -->
<property name="initialSize" value="${jdbc_initialSize}" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="${jdbc_maxActive}" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="${jdbc_minIdle}" />
<!-- 获取连接最大等待时间 毫秒-->
<property name="maxWait" value="${jdbc_maxWait}" /> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize" value="33" /> <property name="validationQuery" value="${validationQuery}" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" /> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" /> <!-- 超过时间限制是否回收: 打开removeAbandoned功能 -->
<property name="removeAbandoned" value="true" />
<!-- 超时时间:1800秒,也就是30分钟 -->
<property name="removeAbandonedTimeout" value="1800" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" /> <!-- 监控数据库 -->
<!-- <property name="filters" value="mergeStat" /> -->
<property name="filters" value="stat" /> <!-- 非公平锁 -->
<property name="useUnfairLock" value="true" />
</bean> <bean id="dynamicDataSource" class="com.dowave.datasource.DynamicDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- 主库-腕表 -->
<entry key="ds1" value-ref="dataSource"/>
<!-- 副库-车机 -->
<entry key="ds2" value-ref="dataSource2"/>
</map>
</property>
<!--默认数据源-->
<property name="defaultTargetDataSource" ref="dataSource"/>
</bean> <!-- myBatis文件 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dynamicDataSource" />
<!-- 自动扫描entity目录, 省掉Configuration.xml里的手工配置 -->
<property name="mapperLocations" value="classpath:com/XXXXXX/entity/mapper/*.xml" />
</bean>
3、数据源切换工具类
枚举类:代表对应的数据源
public enum DataSourceEnum {
DS1("ds1"), DS2("ds2");
private String key;
DataSourceEnum(String key) {
this.key = key;
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
}
创建创建 DynamicDataHolder 用于持有当前线程中使用的数据源标识
public class DataSourceHolder {
private static final ThreadLocal<String> dataSources = new ThreadLocal<String>();
public static void setDataSources(String dataSource) {
dataSources.set(dataSource);
}
public static String getDataSources() {
return dataSources.get();
}
}
创建DynamicDataSource的类,继承AbstractRoutingDataSource并重写determineCurrentLookupKey方法
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceHolder.getDataSources();
}
}
4、自动切换数据源,利用AOP,进行自动切换数据源
创建切面类 DataSourceExchange,切面的规则可以自定义,根据自己的项目做自己的规则,我这边用 citn 表示不同的数据源。
public class DataSourceExchange {
public void before(JoinPoint point) {
// 获取目标对象的类类型
Class<?> aClass = point.getTarget().getClass();
String c = aClass.getName();
String[] s = c.split("\\.");
// 获取包名用于区分不同数据源
String packageName = s[3];
if ("citn".equals(packageName)) {
DataSourceHolder.setDataSources(DataSourceEnum.DS2.getKey());
System.out.println("数据源:" + DataSourceEnum.DS2.getKey());
} else {
DataSourceHolder.setDataSources(DataSourceEnum.DS1.getKey());
System.out.println("数据源:" + DataSourceEnum.DS1.getKey());
}
}
/**
* 执行后将数据源置为默认
*/
public void after() {
DataSourceHolder.setDataSources(DataSourceEnum.DS1.getKey());
}
}
5、Spring.xml 配置AOP切面,expression 为切入点,根据自己项目调整。
<bean id="dataSourceExchange" class="com.dowave.datasource.DataSourceExchange" />
<aop:config>
<aop:aspect ref="dataSourceExchange">
<aop:pointcut id="dataSourcePointcut" expression="execution(* com.XXXXXX.**.service.impl.*ServiceImpl.*(..))" />
<aop:before pointcut-ref="dataSourcePointcut" method="before" />
<aop:after pointcut-ref="dataSourcePointcut" method="after" />
</aop:aspect>
</aop:config>
6、需要使用其他数据源在 *ServiceImpl 的位置切换数据源即可
@Service
public class AdminServiceImpl implements IAdminService {
@Autowired
private AdminDao adminDao;
@Autowired
private AgentDao agentDao;
@Autowired
private AdminAgentDao adminAgentDao; @Override
public Admin login(AdminForm form) {
DataSourceHolder.setDataSources(DataSourceEnum.DS2.getKey());
return adminDao.login(form);
}
}
附:结构目录
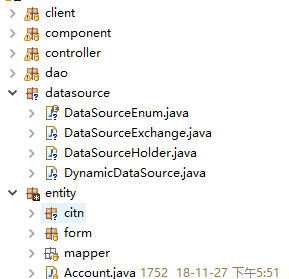

SSM框架、Druid连接池实现多数据源配置(已上线使用)的更多相关文章
- SpringBoot框架:通过AOP和自定义注解完成druid连接池的动态数据源切换(三)
一.引入依赖 引入数据库连接池的依赖--druid和面向切面编程的依赖--aop,如下所示: <!-- druid --> <dependency> <groupId&g ...
- (二)SpringBoot整合常用框架Druid连接池
一,在Pom.xml文件加入依赖 找到<dependencies></dependencies>标签,在标签中添加Druid依赖 <dependency> < ...
- springboot整合druid连接池、mybatis实现多数据源动态切换
demo环境: JDK 1.8 ,Spring boot 1.5.14 一 整合durid 1.添加druid连接池maven依赖 <dependency> <groupId> ...
- Druid连接池和springJDbc框架-Java(新手)
Druid连接池: Druid 由阿里提供 安装步骤: 导包 durid1.0.9 jar包 定义配置文件 properties文件 名字任意位置也任意 加载文件 获得数据库连接池对象 通过Durid ...
- Druid连接池(无框架)
关于连接池有不少技术可以用,例如c3p0,druid等等,因为druid有监控平台,性能在同类产品中算top0的.所以我采用的事druid连接池. 首先熟悉一个技术,我们要搞明白,为什么要用他, 他能 ...
- spring+mybatis+c3p0数据库连接池或druid连接池使用配置整理
在系统性能优化的时候,或者说在进行代码开发的时候,多数人应该都知道一个很基本的原则,那就是保证功能正常良好的情况下,要尽量减少对数据库的操作. 据我所知,原因大概有这样两个: 一个是,一般情况下系统服 ...
- spring下,druid,c3p0,proxool,dbcp四个数据连接池的使用和配置
由于那天Oracle的数据连接是只能使用dbcp的数据库连接池才连接上了,所以决定试一下当下所有得数据库连接池连接orcale和mysql,先上代码 配置文件的代码 #================ ...
- SpringBoot2.0 基础案例(07):集成Druid连接池,配置监控界面
一.Druid连接池 1.druid简介 Druid连接池是阿里巴巴开源的数据库连接池项目.Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能.功能强大,能防SQL注入,内置Login ...
- druid连接池获取不到连接的一种情况
数据源一开始配置: jdbc.initialSize=1jdbc.minIdle=1jdbc.maxActive=5 程序运行一段时间后,执行查询抛如下异常: exception=org.mybati ...
随机推荐
- Spring Boot 启动(二) Environment 加载
Spring Boot 启动(二) Environment 加载 Spring 系列目录(https://www.cnblogs.com/binarylei/p/10198698.html) 上一节中 ...
- 1.4eigen中的块运算
1.4 块运算 块是矩阵或数组的一个矩形部分.块表达式既可以做左值也可以作右值.和矩阵表达式一样,块分解具有零运行时间成本,对你的程序进行优化. 1.使用块运算 最常用的块运算是.block()成员函 ...
- 关于git 命令的一些事
克隆代码命令 http://www.yiibai.com/git/git_clone.html 关键:得实现新建本地仓库文件夹 ==> git clone 远程网址 git 上传主要代码:htt ...
- Codeforces Round #536 (Div. 2) E dp + set
https://codeforces.com/contest/1106/problem/E 题意 一共有k个红包,每个红包在\([s_i,t_i]\)时间可以领取,假如领取了第i个红包,那么在\(d_ ...
- 整理python小爬虫
编码使我快乐!!! 我也不知道为什么,遇到自己喜欢的事情,就越想做下去,可以一个月不出门,但是不能一天没有电脑 掌握程度:对python有了一个更清晰的认识,自动化运维,也许可以用python实现呢, ...
- 关于esp32的系统初始化启动过程及设计学习方法
对于esp32,其开发程序中有且只能有一个app_main函数,该函数是用户程序的入口,这在没有调用FreeRTOS的系统中相当于函数main,但其实在app_main之前,系统还有一段初始化的过程, ...
- 有关C++模板inline的高性能在lambda与function的体现
前两天在群里跟人讨论到写库时对于lambda和function的取舍,跑了写测试查了些资料后基本得出结论: 如果没有自由变量的情况下,一般不要用function. 如果有自由变量的话,C++中的lam ...
- Presto + Superset 数据仓库及BI
基于Presto和superset搭建数据分析平台. Presto可以作为数据仓库,能够连接多种数据库和NoSql,同时查询性能很高: Superset提供了Presto连接,方便数据可视化和dash ...
- ASP.NET Core 统一异常处理和返回
业务场景: 业务需求要求,需要对 ASP.NET Core 异常进行统一处理和返回,比如出现 500 错误和业务服务错误进行不同的处理和返回. 具体实现: using Microsoft.AspNet ...
- 背水一战 Windows 10 (81) - 全球化
[源码下载] 背水一战 Windows 10 (81) - 全球化 作者:webabcd 介绍背水一战 Windows 10 之 全球化 Demo 格式化数字 示例1.演示全球化的基本应用Locali ...