Elasticsearch 常见问题的解决思路
本文为es性能监控基础的扩展,大家可以先看下性能监控基础,熟悉下es的基本原理。为翻译性质文档,感谢原作者,原始文档地址
类似于汽车的运行方式,Elasticsearch旨在让用户快速上手和运行,而无需了解其所有的内部工作。然而我们在使用过程中,总会遇到这样那样的问题。下文将介绍Elasticsearch使用时经常遇到的一些挑战,以及我们如何应对这些挑战。如下列举了5个常见问题:
一、我的es集群是红色或者黄色的,我该如何处理?

正如性能监控基础中所讲,如果缺少一个或多个主分片(及其副本),则集群状态将报告为红色,如果缺少一个或多个副本分片,则集群状态将呈黄色。通常情况下,当某个节点由于某种原因(硬件故障,较长的垃圾收集时间等)而退出群集时,会发生这种情况。一旦节点回复,其分片在转为active之前会处于initializing。(这个在head中可以通过观察分片颜色得到)
当节点重新加入群集时,initializing 分片的数量会达到峰值,然后随着分片转为active,峰值回落。如下图:
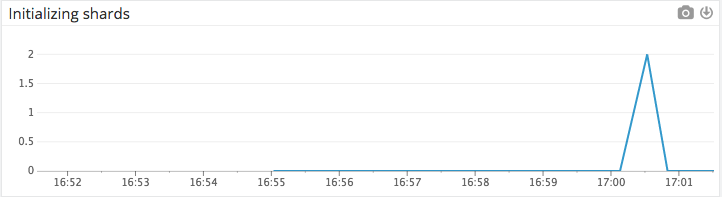
在此initializing 期间,集群状态可能会从绿色转换为黄色或红色,直到恢复节点上的分片重新转为active。 在许多情况下,黄色或红色的简单状态更改可能不需要您采取任何行动。
但是,如果您注意到群集状态长时间处于红色或黄色状态,请检查集群节点的数量。
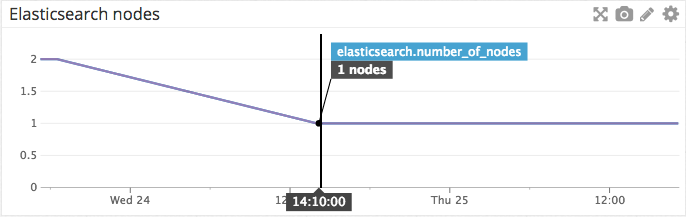
如果活动节点的数量低于预期,则表示至少有一个节点丢失连接,并且无法重新加入群集。 要查找离开集群的节点,请检查类似于以下行的日志(默认位于Elasticsearch主目录的logs文件夹中)。
[TIMESTAMP] ... Cluster health status changed from [GREEN] to [RED] (reason: [[{<NODE_NAME>}...] left])
节点故障的原因可能会有所不同,从硬件或管理程序故障,到内存不足错误。检查节点失败的同一时间发生的任何性能指标异常。例如当前搜索速率或索引请求突然增加,如果确认是请求增加导致,那么这是一个暂时的故障,可以尝试让该断开的节点重新加入集群。如果你无法恢复该节点,则可以添加新节点,并让Elasticsearch从任何可用的副本分片恢复; 副本分片可以升级到主分片,并重新分发到刚刚添加的新节点上。
如果主分片和副分片都丢失了,则可以使用Elasticsearch的快照和还原模块尽可能多地恢复丢失的数据。但是,如果您丢失了分片的主副本和副本副本,则可以使用Elasticsearch的快照和还原模块尽可能多地恢复丢失的数据。 如果您还不熟悉此模块,则可以将其用于在远程存储库中存储索引的快照以进行备份。
二、数据节点磁盘空间不够了

如果所有数据节点的磁盘空间不足,将需要在集群中添加更多的数据节点。 还需要确保您的索引具有足够的主分片,以便能够在所有这些节点之间平衡其数据。
然而,如果只有某些节点的磁盘空间不足,这通常是索引分片太少的一个标志。 如果一个索引由几个非常大的分片组成,那么Elasticsearch很难在各数据节点之间进行数据均衡。
将分片分发给各节点时,Elasticsearch会考虑各个节点的磁盘可用空间。默认情况下,不会将分片分发给磁盘使用率超过85%的节点。在Datadog中,您可以设置阈值警报,以便在任何单个数据节点的磁盘空间使用率达到80%时通知您,以便足够的时间采取行动。
低磁盘使用空间有两种补救措施。 (1)删除过时的数据。 这对所有用户来说可能不是一个可行的选择,但是如果您正在存储基于时间的数据,则可以存储旧索引数据的快照,用于备份,同时更新索引设置以关闭这些过时索引的副本功能。(2)如果你需要所有的数据都存在集群中备用,要么升级硬件资源(vertically scale )、要么水平扩展集群(horizontally scale增加节点,这个是比较合适的)。为了更好适应数据不断的增长,应该要多指定主分片的个数。
水平扩展集群的另外一个方法是创建一个新的索引并使用一个别名to join the two indices together under one namespace. 虽然单个分片存储数据无技术意义上的上限,但是一般建议每个分片不超过50GB。
三、我的搜索执行时间过长怎么办?
根据正在搜索的数据类型和每个查询的结构方式,搜索性能有很大差异。根据您的数据的组织方式,你可能需要尝试几种不同的方法,以便找到一个能提高搜索性能的方法。这里介绍两个:自定义路由和强制合并
通常,当节点接收到搜索请求时,它需要将该请求传达给索引中每个分片的副本。 自定义路由允许将相关数据存储在相同的分片上,以便您只需搜索单个分片来满足查询。
例如,您可以通过在索引blog_index中的mapping中指定_routing值,将所有blogger1的数据存储在同一个分片上。
curl -XPUT "localhost:9200/blog_index" -d '
{
"mappings": {
"blogger": {
"_routing": {
"required": true
}
}
}
}'
当您准备索引与blogger1相关的文档时,请指定路由值:
curl -XPUT "localhost:9200/blog_index/blogger/1?routing=blogger1" -d '
{
"comment": "blogger1 made this cool comment"
}'
现在,为了搜索blogger1的注释,您需要记住在查询中指定路由值,如下所示:
curl -XGET "localhost:9200/blog_index/_search?routing=blogger1" -d '
{
"query": {
"match": {
"comment": {
"query": "cool comment"
}
}
}
}'
在Elasticsearch中,每个搜索请求必须检查所命中的每个分片的每个segment。还可以通过在一个或多个索引上触发Force Merge API来减少每个分片的segment数。 Force Merge API(或2.1.0之前的版本中的Optimize API)将提示索引中的segment继续合并,直到每个碎片的segment计数减少为max_num_segments(默认为1)。如果大量触发merges的成本相对降低,这种方法可以进行尝试。
当分片上segment的数量很多时,强制merge segment将非常浪费。例如,强制将一个索引中的10000个segments压缩到5000个并不耗费太多时间。但是,如果将这10000个segments压缩为1个,将耗费数个小时的时间。The more merging that must occur, the more resources you take away from fulfilling search requests,这可能背离你的初衷。因此通常在非高峰时段(午夜)安排强制合并。
四、如何加快我的index速度
Elasticsearch预先配置了许多设置,尝试确保您保留足够的资源来搜索和索引数据。但是,如果您使用Elasticsearch严重偏向写入,则可能会发现调整某些设置以提高索引性能是有意义的,即使这意味着丢失一些搜索性能或副本数据。 下面,我们将探讨一些方法来优化用例来进行索引,而不是搜索数据。(预设值是兼顾搜索和索引)
- 分片分配: 如果你要创建一个更新频繁的索引,请确保指定足够的主分片,以便您可以在所有节点间均匀分布索引负载。一般建议是每个集群中的节点分配一个主分片。如果你的CPU和磁盘够用,2个或者更多的主分片是可行的(注意:这个是对单个索引来描述的)。但是,请记住,分片过度分配会增加开销,并可能会对搜索产生负面影响,因为搜索请求需要打到索引中的每个分片。另一方面,如果分配的分片数少于节点数,you may create hotspots?因为包含这些分片的节点需要处理比不包含任何索引分片的节点更多的索引请求。
- 禁止 merge throttling: merge throttling是elasticsearch的一个自动机制:当es检测到合并速度落后于索引速度时,es会throttle 索引请求。 如果要优化索引性能,而不是搜索性能,可以通过更新集群设置来禁止掉merge throttling(通过将indices.store.throttle.type设置为“none”)。You can make this change persistent (meaning it will persist after a cluster restart) or transient (resets back to default upon restart), based on your use case.
- 增加indexing buffer的大小: 这个index-level 设置(indices.memory.index_buffer_size)决定了在将文档写入到磁盘上的segment之前buffer的总大小。默认为总heap的10%,以便为索引请求预留更多的heap,which doesn’t help you if you’re using Elasticsearch primarily for indexing.??
- 先index,后replicate: 初始化索引时,在索引设置中指定零个复本分片,并在索引完成后添加副本。 这将提高索引性能。但是有一定的风险。
- 刷新间隔拉长: 增加Index Settings API中的刷新间隔。 默认情况下,索引刷新过程每秒都会发生一次,但是在较大的索引期间,降低刷新频率可以帮助减轻部分工作量。
- 调整translog设置: 从版本2.0开始,Elasticsearch将在每次请求后将Translog数据刷新到磁盘,从而降低硬件故障时数据丢失的风险。如果你中索引性能,并且不太担心潜在的数据丢失的可能,您可以将index.translog.durability更改为异步。 有了这一点,索引只会在每个sync_interval上提交写入磁盘,而不是在每个请求之后提交写入磁盘,从而使其更多的富余资源可以提供索引请求。
五、如何处理buik thread pool rejections ?
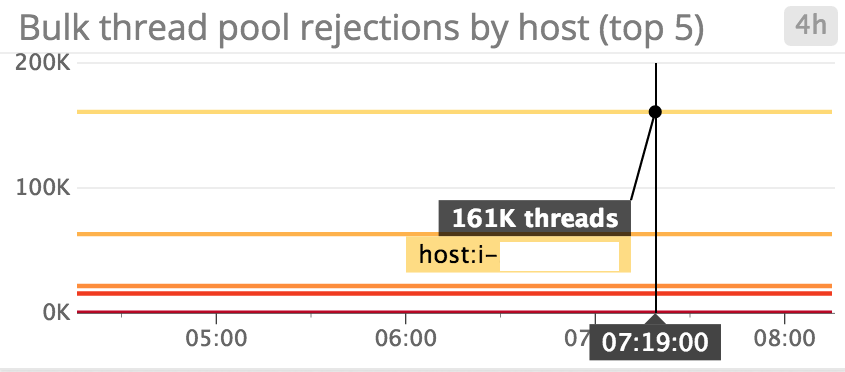
Thread pool rejections 通常是发送过多过快请求的标志。如果这是一个暂时故障(例如,您本周必须索引异常大量的数据,并且您预计很快就会恢复正常),你可以尝试减慢请求的速度。 但是,如果希望集群能够维持当前的请求速率,则可能需要通过添加更多的数据节点来扩展集群。为了利用增加节点数的处理能力,您还应确保您的索引包含足够的分片,以便能够均匀地将所有节点的负载分散。
总结:
由于优化结果将根据您的具体用例和设置而有所不同,您可以测试不同的设置和索引/查询策略,以确定哪些方法对您的集群最有效。
总之寻找合适自己场景的优化和解决办法,避重就轻、合理选择。
Elasticsearch 常见问题的解决思路的更多相关文章
- rsync @ERROR: auth failed on module backup 解决思路及附录rsync常见问题及解决办法
昨晚小版本上线,使用rsync往服务器上传文件时,client报如下异常: @ERROR: auth failed on module backup rsync error: error starti ...
- RSYNC @ERROR: AUTH FAILED ON MODULE XXX 解决思路及附录RSYNC常见问题及解决办法
使用rsync往服务器上传文件时,client报如下异常: @ERROR: auth failed on module XXX rsync error: error starting client-s ...
- fetch使用的常见问题及其解决办法
摘自: https://segmentfault.com/a/1190000008484070 fetch使用的常见问题及其解决办法 javascript wonyun 2月25日发布 | 0 收 ...
- fetch的常见问题及其解决办法
摘要: 玩转fetch. 作者:wonyun 原文:fetch使用的常见问题及其解决办法 Fundebug经授权转载,版权归原作者所有. 首先声明一下,本文不是要讲解fetch的具体用法,不清楚的可以 ...
- Flink on YARN(下):常见问题与排查思路
Flink 支持 Standalone 独立部署和 YARN.Kubernetes.Mesos 等集群部署模式,其中 YARN 集群部署模式在国内的应用越来越广泛.Flink 社区将推出 Flink ...
- ElasticSearch 常见问题
ElasticSearch 常见问题 丈夫有泪不轻弹,只因未到伤心处. 1.说说 es 的一些调优手段. 仅索引层面调优手段: 1.1.设计阶段调优 (1)根据业务增量需求,采取基于日期模板创建索引, ...
- NHibernate常见问题及解决方法
NHibernate常见问题及解决方法 曾经学过NHibernate的,但是自从工作到现在快一年了却从未用到过,近来要巩固一下却发现忘记了许多,一个"in expected: <end ...
- Jquery UI - DatePicker 在Dialog中无法自动隐藏的解决思路
通过Jquery UI Dialog模态展示如下的一个员工编辑页面,但是遇到一个奇怪的问题:点击Start Date的input元素后,其无法失去焦点.从而导致DatePicker控件在选择日期后无法 ...
- WebView加载本地html、js文件常见问题及解决办法
声明:基于android studio平台,php语言搭建服务器 目录: 一.JavaScript脚本语言没有反应 二.alert无法弹出 三.html页面之间不能跳转 四.屏幕缩放没有达到预期效果 ...
随机推荐
- 使用canvas实现一个圆球的触壁反弹
HTML <canvas id="canvas" width="500" height="500" style="borde ...
- 利用 John the Ripper 破解用户登录密码
一.什么是 John the Ripper ? 看到这个标题,想必大家都很好奇,John the Ripper 是个什么东西呢?如果直译其名字的话就是: John 的撕裂者(工具). 相比大家都会觉得 ...
- VMware vSphere虚拟化-VMware ESXi 5.5组件安装过程记录
几种主要的虚拟化 ESXi是VMware公司研发的虚拟机服务器,ESXi已经实现了与Virtual Appliance Marketplace的直接整合,使用户能够即刻下载并运行虚拟设备.这为 即插即 ...
- Python下操作Memcache/Redis/RabbitMQ说明
一.MemcacheMemcache是一套分布式的高速缓存系统,由LiveJournal的Brad Fitzpatrick开发,但目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的.需要频繁访 ...
- 《Linux内核设计与实现》第3章读书整理
第三章.进程管理 3.1进程 1.进程就是处于执行期的程序,但进程并不仅仅局限于一段可执行程序代码 2.执行线程: 简称线程,是在进程中活动的对象.每个线程都拥有一个独立的程序计数器.进程栈和一组进程 ...
- Linux课题实践四——ELF文件格式分析
2.4 ELF文件格式分析 20135318 刘浩晨 ELF全称Executable and Linkable Format,可执行连接格式,ELF格式的文件用于存储Linux程序.ELF文件(目 ...
- Linux实践四:ELF文件格式分析
一.分析ELF文件头 二.通过文件头找到section header table,理解内容 三.通过section header table 找到各section 四.理解常见.text .strta ...
- 20135337——Linux实践二:模块
一.编译&生成&测试&删除 1.编写模块代码,查看如下 gedit 1.c(编写) cat 1.c(查看) MODULE_AUTHOR("Z") MODUL ...
- git 使用ssh密钥
一.查看仓库支持的传输协议 1.1查看仓库支持的传输协议 使用命令 git remote -v 查看你当前的 remote url root@zengyue:/home/yuanGit# git re ...
- docker安装后启动出现错误
重启报错: [root@localhost ~]# systemctl restart docker Job for docker.service failed because the control ...