lucene简单搜索demo
方法类
package com.wxf.Test;
import com.wxf.pojo.Goods;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.IOException;
import java.nio.file.Paths; /**
* @Auther: wxf
* @Date: 2018/6/29 15:40
*/
public class IndexCRUD {
private Directory dir;
{
try {
dir = FSDirectory.open(Paths.get( System.getProperty("user.dir")+"\\src\\main\\resources\\index"));
} catch (IOException e) {
e.printStackTrace();
}
} /**
* 获取IndexWriter实例
* @return
* @throws Exception
*/
public IndexWriter getWriter()throws Exception{
//中文分词器
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
IndexWriterConfig iwc=new IndexWriterConfig(standardAnalyzer);
IndexWriter writer=new IndexWriter(dir, iwc);
return writer;
} public void setUp() throws Exception {
Goods goods=new Goods("123","红色强化门",360);
Goods goods2=new Goods("223","黑色强化门",370);
Goods goods3=new Goods("333","白色强化门",380);
String skuid[]={"123","223","333"};
String name[]={"红色强化门","黑色强化门","白色强化门"};
Object obj[]={goods,goods2,goods3};
IndexWriter writer=getWriter();
for(int i=0;i<skuid.length;i++){
Document doc=new Document();
doc.add(new StringField("skuid", skuid[i], Field.Store.YES));
doc.add(new TextField("name",name[i],Field.Store.YES));
doc.add(new TextField("obj", obj[i].toString(), Field.Store.YES));
writer.addDocument(doc); // 添加文档
}
writer.close();
} /**
* 测试写了几个文档
* @throws Exception
*/
public void testIndexWriter()throws Exception{
IndexWriter writer=getWriter();
System.out.println("写入了"+writer.numDocs()+"个文档");
writer.close();
} /**
* 测试读取文档
* @throws Exception
*/
public void testIndexReader()throws Exception{
IndexReader reader=DirectoryReader.open(dir);
System.out.println("最大文档数:"+reader.maxDoc());
System.out.println("实际文档数:"+reader.numDocs());
reader.close();
} /**
* 查询
* @return
*/
public void select(String str1,String str2) throws IOException, ParseException {
//得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(System.getProperty("user.dir")+"\\src\\main\\resources\\index"));
IndexReader ireader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(ireader);
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
/**
* 第一个参数是要查询的字段;
* 第二个参数是分析器Analyzer
* */
QueryParser parser = new QueryParser(str1, standardAnalyzer);
//根据传进来的str2查找
Query query = parser.parse(str2);
//计算索引开始时间
long start = System.currentTimeMillis();
/**
* 第一个参数是通过传过来的参数来查找得到的query;
* 第二个参数是要出查询的行数
* */
TopDocs rs = searcher.search(query, 10);
long end = System.currentTimeMillis();
System.out.println("匹配"+str2+",总共花费了"+(end-start)+"毫秒,共查到"+rs.totalHits+"条记录。");
for (int i = 0; i < rs.scoreDocs.length; i++) {
Document doc = searcher.doc(rs.scoreDocs[i].doc);
System.out.println("skuid:" + doc.getField("skuid").stringValue());
System.out.println("name:" + doc.getField("name").stringValue());
System.out.println("obj:" + doc.getField("obj").stringValue());
}
}
}
测试类
package com.wxf.Test;
/**
* @Auther: wxf
* @Date: 2018/6/29 15:46
*/
public class Test {
public static void main(String[] args) throws Exception {
IndexCRUD indexCRUD=new IndexCRUD();
// indexCRUD.setUp();
indexCRUD.testIndexWriter();
indexCRUD.testIndexReader();
indexCRUD.select("name", "黑");
}
}
indexCRUD.setUp() 这个方法 调一次就可以了
结果如下

这次换个范围大的查询参数
public class Test {
public static void main(String[] args) throws Exception {
IndexCRUD indexCRUD=new IndexCRUD();
// indexCRUD.setUp();
indexCRUD.testIndexWriter();
indexCRUD.testIndexReader();
indexCRUD.select("name", "强化");
}
}
结果如下:
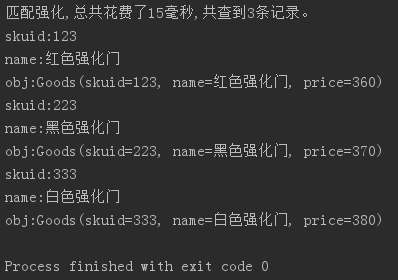
这里采用一元分词 可以随意匹配
lucene简单搜索demo的更多相关文章
- lucene简单使用demo
测试结构目录: 1.索引库.分词器 Configuration.java package com.test.www.web.lucene; import java.io.File; import or ...
- lucene 简单搜索步骤
1.创建IndexReader实例: Directory dir = FSDirectory.open(new File(indexDir)); IndexReader reader = Direct ...
- [MyBean说明书]-如何进行最简单的DEMO
MyBean是轻量级的.绿色的框架,不需要安装任何的组件和携带任何的其他文件,前 期步骤已经相当精简了,仔细阅读完下面简单的五个步骤,就可以编写基于MyBean的插件: 1.加入Delphi的搜索路径 ...
- ElasticSearch 5学习(4)——简单搜索笔记
空搜索: GET /_search hits: total 总数 hits 前10条数据 hits 数组中的每个结果都包含_index._type和文档的_id字段,被加入到_source字段中这意味 ...
- C#可扩展编程之MEF学习笔记(一):MEF简介及简单的Demo
在文章开始之前,首先简单介绍一下什么是MEF,MEF,全称Managed Extensibility Framework(托管可扩展框架).单从名字我们不难发现:MEF是专门致力于解决扩展性问题的框架 ...
- nyoj 284 坦克大战 简单搜索
题目链接:http://acm.nyist.net/JudgeOnline/problem.php?pid=284 题意:在一个给定图中,铁墙,河流不可走,砖墙走的话,多花费时间1,问从起点到终点至少 ...
- Maven+Spring+Hibernate+Shiro+Mysql简单的demo框架(二)
然后是项目下的文件:完整的项目请看 上一篇 Maven+Spring+Hibernate+Shiro+Mysql简单的demo框架(一) 项目下的springmvc-servlet.xml配置文件: ...
- MEF简介及简单的Demo
MEF简介及简单的Demo 文章开始之前,首先简单介绍一下什么是MEF,MEF,全称Managed Extensibility Framework(托管可扩展框架).单从名字我们不难发现:MEF是专门 ...
- 分布式搜索ElasticSearch构建集群与简单搜索实例应用
分布式搜索ElasticSearch构建集群与简单搜索实例应用 关于ElasticSearch不介绍了,直接说应用. 分布式ElasticSearch集群构建的方法. 1.通过在程序中创建一个嵌入es ...
随机推荐
- 三 分析easyswoole源码(启动服务&TableManager,略提及Cache工具的原理)
前文连接,讲了es是如何启动swoole服务的. 里面有一个工具类TableManager.这个类为了处理进程间数据共享.是对swoole_table的一层封装swoole_table一个基于共享内存 ...
- 记一次python的任务调度模块apscheduler只在首次执行任务的情况
最近需要写个日更新的程序,用time.sleep()不能很好的控制任务的执行时间 于是,就使用了python的任务调度模块apscheduler,这个模块功能真的是很强大 具体的就不多讲了 将任务程序 ...
- NCUAP 利用java自带方法实现导入excel取数据
final JComponent parent = getModel().getContext().getEntranceUI(); JFileChooser chooser = new JFileC ...
- IoGetRelatedDeviceObject学习
PDEVICE_OBJECT IoGetRelatedDeviceObject( IN PFILE_OBJECT FileObject ) /*++ Routine Description: This ...
- php.ini 配置详解
这个文件必须命名为''php.ini''并放置在httpd.conf中的PHPIniDir指令指定的目录中.最新版本的php.ini可以在下面两个位置查看:http://cvs.php.net/vie ...
- tensorflow学习之(二)Seesion的两种打开模式
#Seesion的两种打开模式 import tensorflow as tf matrix1 = tf.constant([[3,3]])#一行两列的一个矩阵 matrix2 = tf.consta ...
- __LINE__的用法
简单的说,__LINE__可以获取当前代码的函数,结合__FUNCTION__可以打印调试信息,比如函数出错时运行的函数名,及行号,例如 #define p_err_fun , os_time_get ...
- Solidity合约记录——(三)如何在合约中对操作进行权限控制
合约中一般会有多种针对不同数据的操作:例如对于存证内容的增加.更新及查询,若不进行一套符合要求的权限控制,事实上整个合约在真实环境下是没有多少使用价值的.那么应当如何对合约的权限进行划分?我们针对So ...
- python之路(六)-函数相关
在没有学习函数之前我们的程序是面向过程的,不停的判断,不停的循环,同样的代码重复出现在我们的代码里.函数可以更好的提高我们的 代码质量,避免同样的代码重复出现,而只需要在用的时候调用函数即可执行.此为 ...
- No趴笨小分队
这星期完成了小组的取名这一项重大的活动. 正所谓“名字是一个好开头”,取这个名义有以下的意义: 希望之后的学习以及工作能一帆风顺: 祝福各位小组成员之后的路能顺顺利利: 希望能在组员磨合的过程中可以愉 ...