Q他中的乱码再理解
Qt版本有用4的版本的也有用5的版本,并且还有windows与linux跨平台的需求。
经常出现个问题是windows的解决了,源代码放到linux上编译不通过或者中文会乱码,本文主要是得出一个解决方案能解决Qt的中文问题,并支持不同平台与不同版本。
测试:
#include <QtGui/QApplication>
#include <QtGui/QLabel> int main(int argc, char **argv)
{
QApplication app(argc, argv);
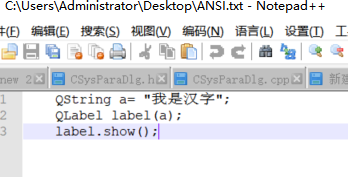
QString a= "我是汉字";
QLabel label(a);
label.show();
return app.exec();
}
编码,保存,编译,运行,一切都很顺利,可是结果呢:
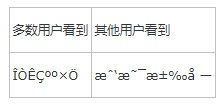
出现乱码!!!
1. 使用场景
Qt版本: Qt5.1.0_VS2012
操作系统: win7
CPP文件编码: UTF8—无BOM格式
CPP部分代码如下:
QTextCodec::setCodecForLocale(QTextCodec::codecForName("UTF8"));
QString strMessage = QString::fromLocal8Bit("我是UTF8编码的文件:"));
qDebug() << strMessage;
试着编译下你会发现编译出错:error C2001: newline in constant
为什么呢?因为UTF8分为UTF8-无BOM和UTF8-BOM
UTF8-BOM其实就是比UTF8-无BOM多了几个字节的文件头,用于和UTF-16与UTF-32区分的。
而:windows识别的UTF8是指UTF-BOM(你可以使用记事本另存为UTF8格式后查看)。
因为有中文冒号:的存在故此UTF8-无BOM文件格式使用VS的Cl编译器是无法识别为UTF8的格式,只能当成ANSI来读取解析编译,故编译出错。
那就有人会说那我就把CPP的文件格式改为:UTF8—BOM格式。
因此对于源码文件.cpp,.h 文件,如果用NodePad++ 打开。(1)如果用UTF-8无BOM格式编码打开保存,则导致再VS2013中编译后的Q他程序,通过:QString::fromLocal8Bit(“中国人民”),则会出现乱码。(2)如果通过UTF-8格式编码,则,可以顺利通过编译QString::fromLocal8Bit(“中国人民”), 没有乱码。

2. 编译器对不同编码的处理
我们只列举大家最常用的3个编译器(微软VS的中的cl,Mingw中的g++,Linux下的g++),源代码分别采用GBK 和不带BOM的UTF-8 以及 带BOM的UTF-8 这3中编码进行保存。

3种不同编码保存的源代码文件,分别用3种不同的编译器编译,形成9种组合,除掉一种不能工作的情况,两种乱码出现的情况各占一半。
从中我们也可以看出,乱码和操作系统原本是没有关系的。
注意:
Windows 一般用的GBK
linux一般用的是不带BOM的UTF-8。如果我们只考虑带*的情况,也可以说两种乱码和系统有关。
3. 深层次理解
QString 为什么会乱码呢?我们可以问问自己,我们抱怨的对象是不是搞错了?
(1)明确概念1:
"我是汉字" 是C语言中的字符串,它是char型的窄字符串。上面的例子可写为
const char * str = "我是汉字";
QString a= str;
或者
char str[] = "我是汉字";
QString a= str;
(2)明确概念2
源文件是有编码的,但是这种纯文本文件却不会记录自己采用的编码
实验验证:
这个是问题的根源,不妨做个试验,将前面的源代码保存成GBK编码,用16进制编辑器能看到引号内是ce d2 ca c7 ba ba d7 d6这样8个字节。
用文本工具,另存为:UTF-8格式另存:
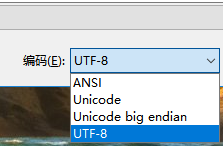
将该文件在: 欧洲人的Windows系统中的记事本打开;则显示:
...
QString a= "ÎÒÊǺº×Ö";
QLabel label(a);
label.show();
...
将该文件在: 繁体字的的Windows系统中的记事本打开;则显
...
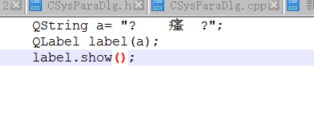
QString a= "扂岆犖趼";
QLabel label(a);
label.show();
...
同一个文件,未做任何修改,但其中的8个字节ce d2 ca c7 ba ba d7 d6,对用GBK的大陆人,用BIG5的港澳台同胞,以及用Latin-1的欧洲人看来,看到的却是完全不同的文字。
UTF-8(含有BOM)以及(没有BOM)显示图下:
BIG5显示,如下图:
ANSI编码格式打开:

明确概念3:
GBK编码下的
const char * str = "我是汉字"
等价于
const char * str = "\xce\xd2\xca\xc7\xba\xba\xd7\xd6";
当用UTF-8编码时,等价于 const char * str = "\xe6\x88\x91\xe6\x98\xaf\xe6\xb1\x89\xe5\xad\x97";
注意:这个说法不全对,比如保存成带BOM的UTF-8,用cl编译器时,汉字本身是UTF-8编码,但程序内保存时却是对应的GBK编码。
明确概念4:QString 内部采用的是Unicode。
QString内部采用的是 Unicode,它可以同时存放GBK中的字符"我是汉字",BIG5中的字符"扂岆犖趼" 以及Latin-1中的字符"ÎÒÊǺº×Ö"。
一个问题是,源代码中的这8个字节"\xce\xd2\xca\xc7\xba\xba\xd7\xd6",该怎么转换成Unicode并存到 QString 内?按照GBK、BIG5、Latin-1还是其他方式...???
在你不告诉它的情况下,它默认选择了Latin-1,于是8个字符"ÎÒÊǺº×Ö"的unicode码被存进了QString中。最终,8个Latin字符出现在你期盼看到4中文字符的地方,所谓的乱码出现了!!!
乱码的产生!!!
4. QString 工作方式
const char * str = "我是汉字";
QString a= str;
其实很简单的一个问题,当你需要从窄字符串 char* 转成Unicode的QString字符串的,你需要告诉QString你的这串char* 中究竟是什么编码?GBK、BIG5、Latin-1
理想情况就是:将char* 传给QString时,同时告诉QString自己的编码是什么
就像下面的函数一样,QString的成员函数知道按照何种编码来处理 C 字符串
QString QString::fromAscii ( const char * str, int size = - )
QString QString::fromLatin1 ( const char * str, int size = - )
QString QString::fromLocal8Bit ( const char * str, int size = - )
QString QString::fromUtf8 ( const char * str, int size = - )
单QString 只提供了这几个成员函数,远远满足不了大家的需求,比如,在简体中文Windows下,local8Bit是GBK,可是有一个char串是 BIG5 或 Latin-2怎么办?
那就动用强大的QTextCodec吧,首先QTextCodec肯定知道自己所负责的编码的,然后你把一个char串送给它,它就能正确将其转成Unicode了。
QString QTextCodec::toUnicode ( const char * chars ) const
可是这个调用太麻烦了,我就想直接
QString a= str;
或
QString a(str);
这样用怎么办?
这样一来肯定没办法同时告诉 QString 你的str是何种编码了,只能通过其他方式了。这也就是开头提到的
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GBK"));
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8"));
设置QString默认采用的编码。而究竟采用哪一个,一般来说就是源代码是GBK,就用GBK,源代码是UTF-8就用UTF-8。但有一个例外,如果你保存成了带BOM的UTF-8而且用的微软的cl编译器,此时仍是GBK。
endl;
Q他中的乱码再理解的更多相关文章
- $q -- AngularJS中的服务(理解)
描述 译者注: 看到了一篇非常好的文章,如果你有兴趣,可以查看: Promises与Javascript异步编程 , 里面对Promises规范和使用情景,好处讲的非常好透彻,个人觉得简单易懂. ...
- javaweb中的乱码问题
0.为什么需要编码,解码, 无论是图片,文档,声音,在网络IO,磁盘io中都是以字节流的方式存在及传递的,但是我们拿到字节流怎么解析呢?这句话就涉及了编码,解码两个过程,从字符数据转化为字节数据就是编 ...
- SpringBoot-04-自动配置原理再理解
4. 自动配置原理再理解 配置文件到底能写什么?怎么写?SpringBoot官方文档有大量的配置,但是难以全部记住. 分析自动配置原理 官方文档 我们以HttpEncodingAutoCo ...
- SQL SERVER 2005/2008 中关于架构的理解(二)
本文上接SQL SERVER 2005/2008 中关于架构的理解(一) 架构的作用与示例 用户与架构(schema)分开,让数据库内各对象不再绑在某个用户账号上,可以解决SQL SERVE ...
- SQL SERVER 2005/2008 中关于架构的理解(一)
SQL SERVER 2005/2008 中关于架构的理解(一) 在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询, ...
- Javaweb编程中的乱码问题
程序中的乱码问题,主要出现在我们处理中文数据的过程中出现.从浏览器向服务器请求数据,服务器返回的数据在浏览器中显示为乱码.或者是服务器中的java文件用到中文,也有可能会出现乱码.数据库在处理数据的时 ...
- Java中线程同步的理解 - 其实应该叫做Java线程排队
Java中线程同步的理解 我们可以在计算机上运行各种计算机软件程序.每一个运行的程序可能包括多个独立运行的线程(Thread). 线程(Thread)是一份独立运行的程序,有自己专用的运行栈.线程有可 ...
- OpenGL中的像素包装理解
OpenGL中的像素包装理解 像素包装 位图和像素图很少会被紧密包装到内存中.在许多硬件平台上,考虑到性能的原因位图和像素图的每一行的数据会从特殊的字节对齐地址开始.绝大多数编译 器会自动把变量和缓冲 ...
- SVM问题再理解与分析——我的角度
SVM问题再理解与分析--我的角度 欢迎关注我的博客:http://www.cnblogs.com/xujianqing/ 支持向量机问题 问题先按照几何间隔最大化的原则引出他的问题为 上面的约束条件 ...
随机推荐
- find和find_if,value_type
find算法:返回 [first,end)中第一个值等于value元素的位置 线性复杂度:最多比较次数:元素的总个数 find函数的最后一个参数,必须是string,float,char,double ...
- OSGI引入Spring DM实现对服务对象的管理
一.异同 熟悉Spring的应该也都了解它的IOC的功能,那么对于在OSGI开发环境下,在使用IOC功能时有什么不同呢?最重要的一点就是Spring上下文对象,每个Spring-Powered Bun ...
- ROC曲线 Receiver Operating Characteristic
ROC曲线与AUC值 本文根据以下文章整理而成,链接: (1)http://blog.csdn.net/ice110956/article/details/20288239 (2)http://b ...
- Python编程笔记(第二篇)二进制、字符编码、数据类型
一.二进制 bin() 在python中可以用bin()内置函数获取一个十进制的数的二进制 计算机容量单位 8bit = 1 bytes 字节,最小的存储单位,1bytes缩写为1B 1KB = 10 ...
- 记录点复习题目和linux学习
哈希怎么底层.key放数组哪部分里面 HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体. 开网页怎么获取页面 linux 看进程的cpu 和内存占用率 看哪个端口被占用 ...
- SQL 将一个表中的所有记录插入到一个临时表中
insert into #tempTable select * from TempTable WHERE + 查询条件
- 查看Android应用所需权限(uses-permission)
http://www.tuicool.com/articles/zq2meq MainActivity如下: package cc.testusespermission; import android ...
- Magpie
https://github.com/LLNL/magpie Magpie contains a number of scripts for running Big Data software in ...
- Java往hbase写数据
接上篇读HDFS 上面读完了HDFS,当然还有写了. 先上代码: WriteHBase public class WriteHBase { public static void writeHbase( ...
- 负载均衡下 tomcat session 共享
概述 在分布式部署的情况下,每台tomcat 都会有自己的session ,这样如果 用户A 在tomcat1 下登录,在tomcat2 下并没有session信息.如果 tomcat1宕机,tomc ...