GBDT原理
| 样本编号 | 花萼长度(cm) | 花萼宽度(cm) | 花瓣长度(cm) | 花瓣宽度 | 花的种类 |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | 山鸢尾 |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | 山鸢尾 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 | 杂色鸢尾 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 | 杂色鸢尾 |
| 5 | 6.3 | 3.3 | 6.0 | 2.5 | 维吉尼亚鸢尾 |
| 6 | 5.8 | 2.7 | 5.1 | 1.9 | 维吉尼亚鸢尾 |
6个样本的三分类问题:
(1)三维向量标志样本的label:
[1,0,0] 表示样本属于山鸢尾,
[0,1,0] 表示样本属于杂色鸢尾,
[0,0,1] 表示属于维吉尼亚鸢尾
(2) 对每一个类训练一个CART Tree 模型: 三个树相互独立
山鸢尾类别训练一个 CART Tree 1。
杂色鸢尾训练一个 CART Tree 2 。
维吉尼亚鸢尾训练一个CART Tree 3
(3) 以样本1为例
针对CART Tree 1,训练样本是[5.1,3.5,1.4,0.2],label 是 1,最终输入到模型当中的为[5.1,3.5,1.4,0.2,1]
针对CART Tree 2,训练样本是[5.1,3.5,1.4,0.2],label 是 1,最终输入到模型当中的为[5.1,3.5,1.4,0.2,0]
针对CART Tree 3,训练样本是[5.1,3.5,1.4,0.2],label 是 1,最终输入到模型当中的为[5.1,3.5,1.4,0.2,0]
(4)CART Tree1生成:哪个特征最合适? 这个特征的什么特征值作为切分点?以CART Tree 1为例
1. 从这四个特征中找一个特征做为CART Tree1 的节点,遍历所有的可能值
1.1 第一个特征【长度】的第一个特征值【5.1cm】为例。
R1 为所有样本中花萼长度小于 5.1 cm 的样本集合,
R2 为所有样本当中花萼长度大于等于 5.1cm 的样本集合。

y1为R1样本的label均值:y1=1/1=1
y2为R2样本的label均值:y2=(1+0+0+0+0)/5=0.2
样本1属于R2的值为:(1-0.2)^2
样本2属于R1的值为:(1-1)^2
样本3属于R2的值为(0-0.2)^2
样本4属于R2的值为(0-0.2)^2
样本5属于R2的值为(0-0.2)^2
样本6属于R2的值为(0-0.2)^2
CART Tree 1在第一个特征【长度】的第一个特征值【5.1cm】的损失值为:(1-0.2)^2+ (1-1)^2 + (0-0.2)^2+(0-0.2)^2+(0-0.2)^2 +(0-0.2)^2= 0.84
1.2 第一个特征【长度】的第二个特征值【4.9cm】计算,损失值为:2.244189
1.3 遍历所有特征的特征值,查找最小的特征及特征值,特征花萼长度,特征值为5.1 cm。这个时候损失函数最小为 0.8
2. 预测函数
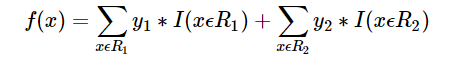
R1 = {2},R2 = {1,3,4,5,6},y1 = 1,y2 = 0.2
样本属于类别山鸢尾类别的预测值f1(x)=1+0.2∗5=2f1(x)=1+0.2∗5=2
同理我们可以得到对样本属于类别2,3的预测值f2(x)f2(x),f3(x)f3(x).样本属于类别1的概率 即为
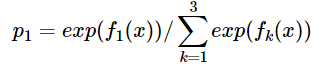
GBDT原理的更多相关文章
- GBDT原理及利用GBDT构造新的特征-Python实现
1. 背景 1.1 Gradient Boosting Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向.损失函数是 ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- XGBoost,GBDT原理详解,与lightgbm比较
xgb原理: https://www.jianshu.com/p/7467e616f227 https://blog.csdn.net/a819825294/article/details/51206 ...
- 手撸GBDT原理(未完成)
一直对GBDT里面的具体计算逻辑不太清楚,在网上发现了一篇好博客. 先上总结的关系图 GBDT对类别变量是怎么处理的? 这些东西都是在网上发现的,讲的挺好的. GBDT原理与Sklearn源码分析-回 ...
- 机器学习入门:极度舒适的GBDT原理拆解
机器学习入门:极度舒适的GBDT拆解 本文旨用小例子+可视化的方式拆解GBDT原理中的每个步骤,使大家可以彻底理解GBDT Boosting→Gradient Boosting Boosting是集成 ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- GBDT原理实例演示 1
考虑一个简单的例子来演示GBDT算法原理 下面是一个二分类问题,1表示可以考虑的相亲对象,0表示不考虑的相亲对象 特征维度有3个维度,分别对象 身高,金钱,颜值 cat dating.txt ...
- GBDT原理学习
首先推荐 刘建平 的博客学习算法原理推导,这位老师的讲解都很详细,不过GBDT的原理讲解我没看明白, 而是1.先看的https://blog.csdn.net/zpalyq110/article/de ...
- GBDT原理实例演示 2
一开始我们设定F(x)也就是每个样本的预测值是0(也可以做一定的随机化) Scores = { 0, 0, 0, 0, 0, 0, 0, 0} 那么我们先计算当前情况下的梯度值 ...
- GBDT原理详解
从提升树出发,——>回归提升树.二元分类.多元分类三个GBDT常见算法. 提升树 梯度提升树 回归提升树 二元分类 多元分类 面经 提升树 在说GBDT之前,先说说提升树(boosting tr ...
随机推荐
- ajax+js数据模板+后台
.net 后台,ajax+js模板引擎的数据填充,制作无刷新分页 js模板用laytpl 待续...
- CSS3 Backgrounds相关介绍
CSS3 Backgrounds相关介绍 1.背景图片(background images)是在padding-box的左上角落脚安家的,我们可以使用background-position属性改变默认 ...
- [1.16更新B14特征处理]津南数字制造题目解读及部分思路~~有趣的特征
[1.16更新B14特征处理]津南数字制造题目解读及部分思路--有趣的特征 Article onion啦啦啦 2019-01-17 16:03:38 11 1790 11 首先声明,我并不能保证这些特 ...
- 文本工具 TextUtils 字符串
常用方法: isEmpty:判断字符串是否为空值 getTrimmedLength:获取字符串去除头尾空格之后的长度 isDigitsOnly:判断字符串是否全部由数字组成 ellipsize:如果字 ...
- (mysql数据库报错)The user specified as a definer ('root'@'%') does not exist
权限问题,授权 给 root 所有sql 权限 解决办法: (1)登录MYSQL 以管理员身份运行cmd >mysql -u root -p >密码 (2)更改权限 ...
- Adb logcat 抓日志
http://blog.csdn.net/hujiachun1234/article/details/43271149 http://www.cnblogs.com/medsonk/p/6344373 ...
- JavaScript各种继承方式(二):借用构造函数继承(constructor stealing)
一 原理 在子类的构造函数中,通过call ( ) 或 apply ( ) 的形式,调用父类的构造函数来实现继承. function Fruit(name){ this.name = name; th ...
- bbs项目富文本编辑器实现上传文件到media目录
media目录是在project的settings中设置的,static目录是django自己使用的静态文件的上传目录,media目录是用户自定义上传文件的目录 # Django用户上传的文件都放在m ...
- python+selenium环境安装
目前 selenium 版本已经升级到 3.7了,网上的大部分教程是基于 2.x写的,所 以在学习前先要弄清楚版本号,这点非常重要.本系列依然以 selenium2 为基础, 目前 selenium3 ...
- 成为JAVA架构师必看书籍推荐
原创文章 “学习的最好途径就是看书“,这是我自己学习并且小有了一定的积累之后的第一体会.个人认为看书有两点好处: 1.能出版出来的书一定是经过反复的思考.雕琢和审核的,因此从专业性的角度来说,一本好书 ...