【ELK】【docker】6.Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow
本章其实是ELK第二章的插入章节。
本章ES集群的多节点是docker启动在同一个虚拟机上
=====================================================================================
ELK系列的示例中,启动的是单个的ES节点。
系列文章:
【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
【ELK】【ElasticSearch】3.es入门基本操作
【ELK】4.spring boot 2.X集成ES spring-data-ES 进行CRUD操作 完整版+kibana管理ES的index操作
【ELK】5.spring boot日志集成ELK,搭建日志系统
【ELK】【docker】6.Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow
【ELK】7. elasticsearch linux上操作es命令详解
======================================================================================
一、单节点的问题描述----ES集群状态可能为yellow
单节点ES使用起来,没有多大的问题。
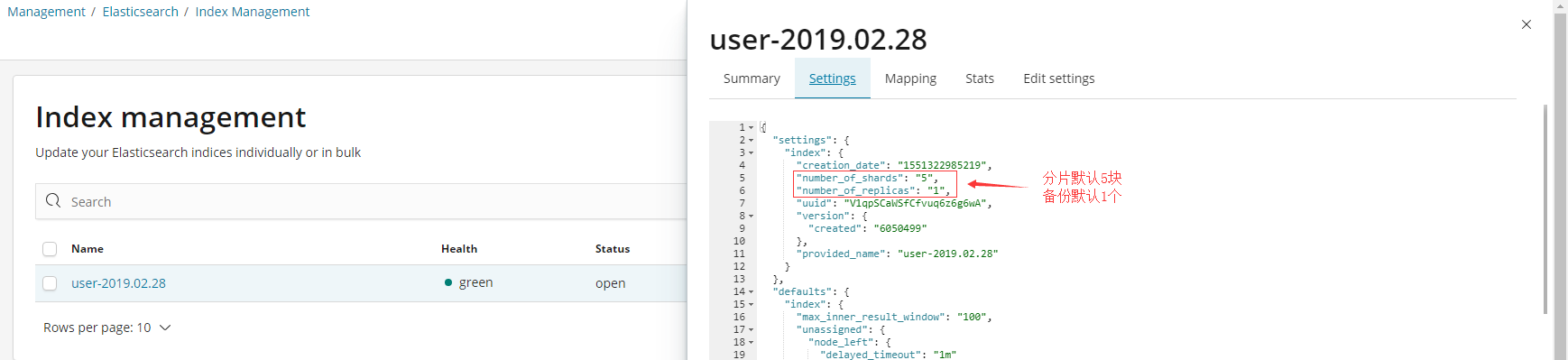
但有一点无法避免,即index创建多分片和多备份的话,会显示ES节点状态为yellow。
1.ES集群健康状态为yellow
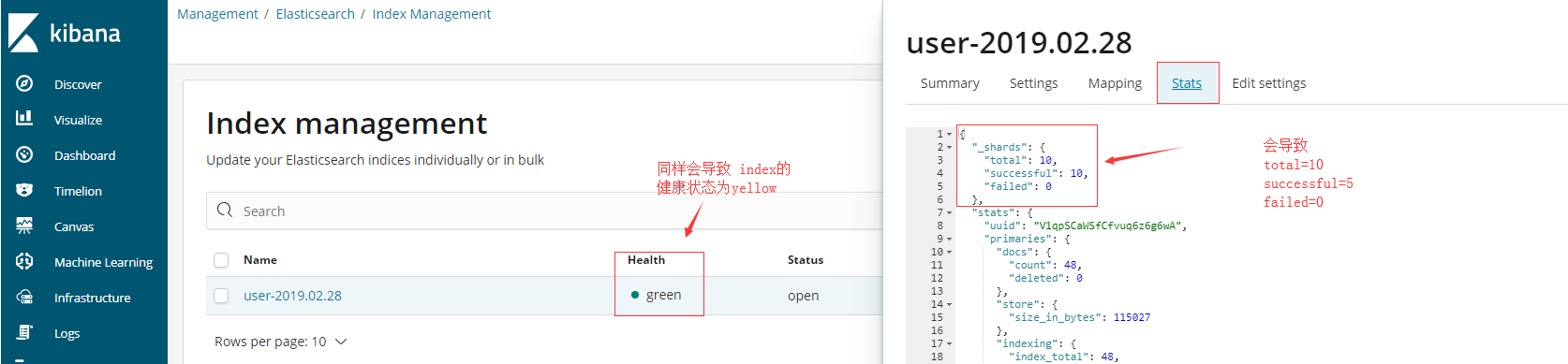
那,即图中所描述的:备份虽然设置为1 但是每个分片的备份其实都没有成功。因为没有另一个节点可以提供备份的场所。
最终导致的结果就是ES集群的健康状态为yellow。
而如果本ES节点挂掉,则数据完全丢失。

2.spring boot对接ES或spring boot日志对接ELK多数默认index的replicas为1
在前几章中,其实都是使用的ES单节点提供服务。
而spring boot中如果不是用自定义settings设置index的shards和replicas,那默认的index的shards=5,而replicas=1。
同样spring boot日志logback对接logstash,搭建ELK分布式日志系统,默认的index的shards=5,而replicas=1。
如果依旧启动的是单节点Nodes=1,那么就会导致
二、ElasticSearch 6.5.4版本启动集群
本章其实是ELK系列文章 第二章的插入章节。
1.前提步骤就是拉取镜像 和 跳转第一步一样
2.先分别启动es1和es2
docker run -d --name es1 -p 9200:9200 -p 9300:9300 --restart=always elasticsearch:6.5.4
docker run -d --name es2 -p 9201:9201 -p 9301:9301 --restart=always elasticsearch:6.5.4
注意:和启动单节点少了个参数
-e "discovery.type=single-node"
3.分别查询es1和es2容器的IP
docker inspect es1

docker inspect es2

4.分别进入es1和es2容器中,修改elasticsearch.yml文件内容
elasticsearch.yml文件路径
cd /usr/share/elasticsearch/config
文件原内容

分别修改elasticsearch.yml文件内容为:
cluster.name: "docker-cluster"
network.host: 0.0.0.0 # minimum_master_nodes need to be explicitly set when bound on a public IP
# set to 1 to allow single node clusters
# Details: https://github.com/elastic/elasticsearch/pull/17288
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: ["127.0.0.1","172.17.0.2:9200","172.17.0.7:9201","172.17.0.2:9300","172.17.0.7:9301"]
注释1:
discovery.zen.minimum_master_nodes: 2 是保证集群中的节点知道集群中有N个master资格的节点
注释2:
discovery.zen.ping.unicast.hosts: ["127.0.0.1","172.17.0.2:9200","172.17.0.7:9201","172.17.0.2:9300","172.17.0.7:9301"] 标明集群初始的master节点列表
需要注意的是,这里的IP是docker容器自己的IP,而不是宿主机的IP。【在同一台虚拟机上启动两个es实例的情况下】
注释3:
修改内容的说明可以参考elasticsearch.yml配置文件详解或者【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
这两篇中都有详细说明
注释4:
es1的配置文件和es2配置文件内容都修改为上面的内容即可
5.分别推出容器,分别重启es1和es2容器实例
exit
docker restart es1 es2
6.分别观察es1的启动日志和es2的启动日志,并查看集群健康状态
docker logs -f es1
其中一个节点启动后,一定会报错,提示目前集群中只有一个master节点但是配置文件中 need 2 需要两个。


而这种情况一直会持续到 另一个节点也启动成功,并且成功加入集群后, 集群的健康状态 会由 yellow变成 Green.
查看另外一个节点的启动日志,可以发现两个节点已经互相发现

当然,最后可以通过请求查看集群状态
curl '192.168.92.130:9200/_cluster/health?pretty'

7.如果成功安装kibana了,也可以查看ES的节点状况
kibana的安装以及ELK整个环境的搭建 还是得回到ELK系列文件的第二章节
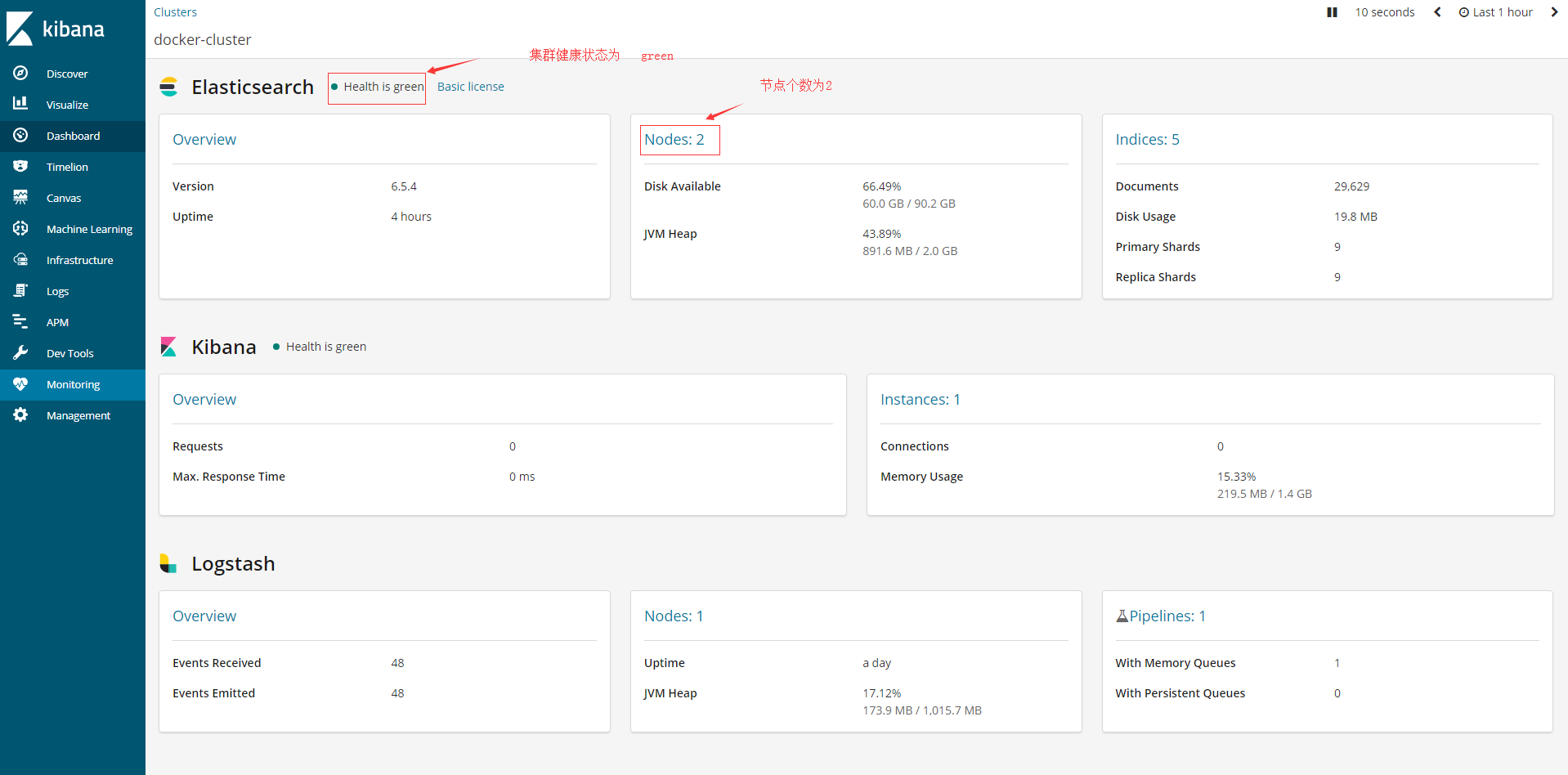

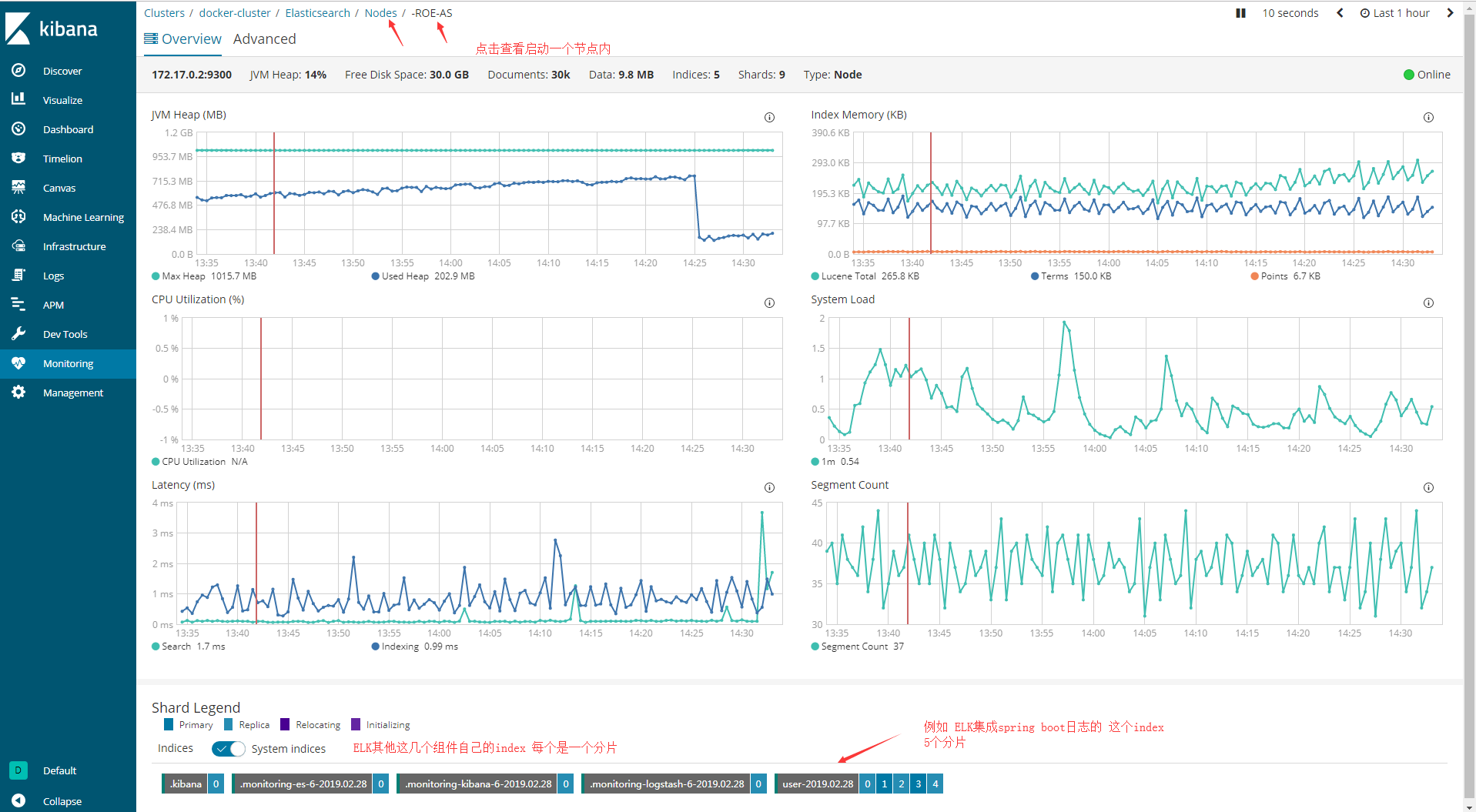

不仅上面这张图可以反映 创建集群成功后,一个Index分别设置shards=5 replicas=1 后,集群的health=Green
下面这张图更能清晰的看出来

8.最后要注意的
其实在第6步看到日志以后,就可以确定ES的集群启动成功了。
第7步只是在kibana上直观的可以感受到集群的分布。
最后需要注意的一点,就是es1和es2如果需要应用于业务,其实还需要将ik分词器,pinyin分词器,繁简体转换等插件分别安装完成。
这个安装的步骤,还是回到ELK系列 第二章去继续看吧。
==========================================================================结束=====================================================================
【ELK】【docker】6.Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow的更多相关文章
- Hadoop ha CDH5.15.1-hadoop集群启动后,集群容量不正确,莫慌,这是正常的表现!
Hadoop ha CDH5.15.1-hadoop集群启动后,集群容量不正确,莫慌,这是正常的表现! 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.集群启动顺序 1>. ...
- k8s集群启动了上万个容器(一个pod里放上百个容器,起百个pod就模拟出上万个容器)服务器超时,无法操作的解决办法
问题说明: 一个POD里放了百个容器,然后让K8S集群部署上百个POD,得到可运行上万个容器的实验目的. 实验环境:3台DELL裸机服务器,16核+64G,硬盘容量忽略吧,上T了,肯定够. 1.一开始 ...
- Hadoop的HA集群启动和停止流程
假设我们有3台虚拟机,主机名分别是hadoop01.hadoop02和hadoop03. 这3台虚拟机的Hadoop的HA集群部署计划如下: 3台虚拟机的Hadoop的HA集群部署计划 hadoop0 ...
- Hadoop集群启动之后,datanode节点未正常启动的问题
Hadoop集群启动之后,用JPS命令查看进程发现datanode节点上,只有TaskTracker进程.如下图所示 master的进程: 两个slave的节点进程 发现salve节点上竟然没有dat ...
- SQL Server AG集群启动不起来的临时自救大招
SQL Server AG集群启动不起来的临时自救大招 背景 前晚一朋友遇到AG集群发生来回切换不稳定的情况,情急之下,朋友在命令行使用命令重启WSFC集群 结果重启WSFC集群之后,非但没有好转,导 ...
- zookeeper源码 — 二、集群启动—leader选举
上一篇介绍了zookeeper的单机启动,集群模式下启动和单机启动有相似的地方,但是也有各自的特点.集群模式的配置方式和单机模式也是不一样的,这一篇主要包含以下内容: 概念介绍:角色,服务器状态 服务 ...
- Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式
Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一说起周五,想必大家都特别 ...
- 全网最详细的Hadoop HA集群启动后,两个namenode都是active的解决办法(图文详解)
不多说,直接上干货! 这个问题,跟 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解) 是大同小异. 欢迎大家,加入我的微信公众号:大数据躺过的坑 ...
- Storm集群启动流程分析
Storm集群启动流程分析 程序员 1.客户端运行storm nimbus时,会调用storm的python脚本,该脚本中为每个命令编写了一个方法,每个方法都可以生成一条相应的Java命令. 命令格式 ...
随机推荐
- jenkins执行构建任务报错之java.lang.NoSuchFieldError: DEFAULT_USER_SETTINGS_FILE
在执行创建工作空间时候,创建不成功,出现错误?? ......... java.lang.NoSuchFieldError: DEFAULT_USER_SETTINGS_FILE ......... ...
- 排序算法的JS实现
排序算法是基础算法,虽然关键在于算法的思想而不是语言,但还是决定借助算法可视化工具结合自己常用的语言实现一下 1.冒泡排序 基本思路:依次比较两两相邻的两个数,前面数比后面数小,不变.前面数比后面数大 ...
- 我的CSS命名规则
常见class关键词: 布局类:header, footer, container, main, content, aside, page, section 包裹类:wrap, inner 区块类:r ...
- js时间格式化函数(兼容IOS)
* 时间格式化 * @param {Object} dateObj 时间对象 * @param {String} fmt 格式化字符串 */ dateFormat(dateObj, fmt) { le ...
- Java编程的逻辑 (1) - 数据和变量
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http: ...
- svn导入项目和部署方面的相关问题
前一阵子忙于部署项目的事情,在这个过程之中遇到了一些问题,查阅了相关资料解决了问题于是就决定分享给大家,可能会对大家有一定的帮助.我在下面中可能会提到dubbo的一些问题,dubbo是用于分布式的系统 ...
- Eclipse代码注释模板-code template
参考帖子blog.csdn.net/security08/article/details/5588013 操作步骤:打开Window->Preferences->Java->Code ...
- Git(三)Git的远程仓库
一. 添加远程库 现在我们已经在本地创建了一个Git仓库,又想让其他人来协作开发,此时就可以把本地仓库同步到远程仓库,同时还增加了本地仓库的一个备份.常用的远程仓库就是github:https://g ...
- [USACO08FEB]修路Making the Grade
[USACO08FEB]修路Making the Grade比较难的dp,比赛时打的找LIS,然后其他的尽可能靠近,40分.先举个例子61 2 3 1 4 561 2 3 3 4 5第4个1要么改成3 ...
- Nginx 日志分析命令
查看日志存放目录 # find / -name access.log /var/log/nginx/access.log cd /var/log/nginx IP相关统计 统计IP访问量(独立ip访问 ...