kafka零数据丢失的配置方案
讨论一下kafka参数的配置
1、acks 参数配置
acks这个参数有三个值:0,1,-1,但是不用的参数对应的含义不同,那如果我们想要保证数据不丢失,acks 值应该设置为哪个参数呢?
0:代表生产者只要把消息发送出去以后就认为消息发送成功了,这种方式有可能会导致数据丢失,因为有可能消息发送到服务端以后服务端存储失败了。
1:代表生产者把消息发送到服务端,服务端的 leader replica 副本写成功以后,就返回生产者消息发送成功了,这种方式也有可能导致丢数据,因为有可能刚好
数据写入到leader replica,然后返回处理成功的响应给生产者,假如这个时候leader replica 在的服务器出问题了,follower replica 还没来得及同步数据,这个时候是会
丢失数据的。
-1(all):代表生产者把消息发送到服务端,服务端的ISR列表里所有的 replica都写入成功以后,才会返回成功响应给生产者。
假设ISR列表里面有该分区的三个replica(一个leader replica,两个follower replica ),那么acks=-1 就意味着消息要写入到 leader replica,并且两个 follower replica从
leader replica 上同步数据成功,服务端才会给生产者发送消息 发送成功的响应。
所以ISR列表里面的replica 就非常关键。如果我们想要保证数据不丢,那么acks的值设置为-1,并且还需要保证ISR列表里面是1个副本以上。
所以 acks的值要设置为-1。
2、ISR到底指的是什么东西?
既然大家已经知道了Partition的多副本同步数据的机制了,那么就可以来看看ISR是什么了。
ISR全称是 "In-Sync Replicas",也就是保持同步的副本,它的含义就是,跟leader 始终保持同步的 follower有哪些。
大家可以想一下,如果说某个follower所在的broker因为JVM Full GC之类的问题,导致自己卡顿了,无法及时从Leader拉取同步数据,那么是不是会导致Follower
数据被Leader要落后很多?
所以这个时候,就意味着follower已经跟leader不再处于同步的关系了。但是只要follower一直及时从leader同步数据,就可以保证他们是处于同步的关系的。
所以每个Partition 都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的follower,也会在ISR里。
3、kafka的存储机制
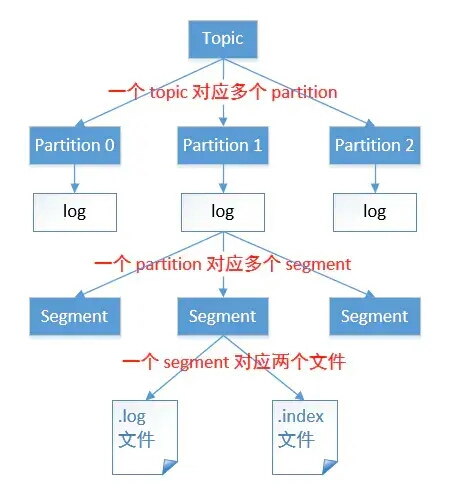
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,kafka采取了分片和索引机制。
它将每个partition 分为多个 segment,每个segment对应两个文件:".index"索引文件和 ".log" 数据文件。(一个分区下面有多个log文件,每个log文件大概有1G)
这些文件位于同一文件下,该文件夹的命名规则为 topic 名 - 分区号。
例如:first 这个topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。
index和log 文件以当前 segment 的第一条消息的 offset命名。下图为 index文件和log文件的机构示意图:
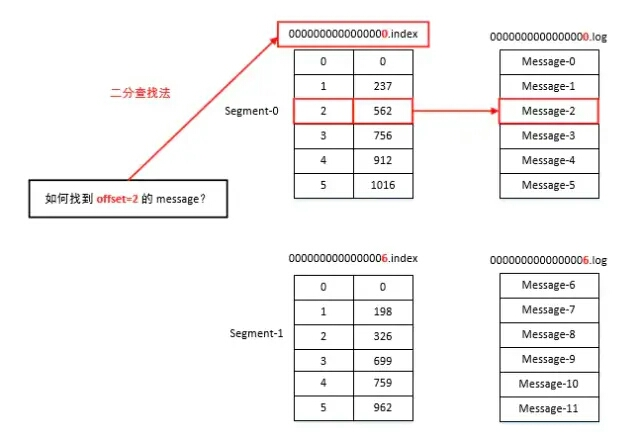
.index 文件存储大量的索引信息, .log文件存储大量的数据,索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
4、kafka的 zero-copy 零拷贝技术
在kafka中消息存储模式中,数据存储在底层文件系统中。当有Consumer订阅了相应的topic消息,数据需要从磁盘中读取然后将数据写回到套接字中(socket)。
此动作看似只需较少的cpu活动,但它的效率非常低。首先内核读出全盘数据,然后将数据跨越内核用户推到应用程序,然后应用程序再次跨越内核用户将数据推回,
写出到套接字。应用程序实际上在这里担当了一个不怎么高效的中介角色,将磁盘文件的数据转入套接字。
数据每遍历用户内核一次,就要被拷贝一次,这会消耗CPU周期和内存带宽。幸运的是,您可以通过一个 零拷贝 的技巧来消除这些拷贝。
使用零拷贝的应用程序要求内核直接将数从磁盘文件拷贝到套接字,而无需通过应用程序。零拷贝不仅大大的提高了应用程序的性能,
而且还减少了内核与用户模式间的上下文切换。
java 类库通过 java.nio.channels.FileChannel 中的 transferTo() 方法来在 Linux和Unix系统上支持零拷贝。可以使用transferTo() 方法直接将
字节从它被调用的通道上传输到另外一个可写字节通道上,数据无需流经应用程序。
kafka零数据丢失的配置方案的更多相关文章
- Spark Streaming容错的改进和零数据丢失
本文来自Spark Streaming项目带头人 Tathagata Das的博客文章,他现在就职于Databricks公司.过去曾在UC Berkeley的AMPLab实验室进行大数据和Spark ...
- Kafka设计解析(十一)Kafka无消息丢失配置
转载自 huxihx,原文链接 Kafka无消息丢失配置 目录 一.Producer端二.Consumer端 Kafka到底会不会丢数据(data loss)? 通常不会,但有些情况下的确有可能会发生 ...
- Kafka SSL安装与配置
1.概述 最近有同学咨询说,Kafka的SSL安全认证如何安装与使用?今天笔者将通过以下几个方面来介绍Kafka的SSL: Kafka 权限介绍 Kafka SSL的安装与使用 Kafka Eagle ...
- Atitit.兼具兼容性和扩展性的配置方案attilax总结
Atitit.兼具兼容性和扩展性的配置方案attilax总结 文件配置法1 Jdbc多数据源文件配置发1 Bat文件配置法1 改进的文件配置法(采用类似i18n技术) 推荐1 使用自动化pc_id的方 ...
- Spring MVC之视图解析器和URL-Pattern的配置方案
上期讲解了第一入门案例之后接下来了解一下视图解析器与URL-Pattern的配置方案 先来说视图解析器,在上次博客文章中我们完成了入门案例,接下来我们就在上一个例子中完善一下体出视图解析器 <? ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Apache安全配置方案
Apache安全配置方案 from:http://drops.wooyun.org/%e8%bf%90%e7%bb%b4%e5%ae%89%e5%85%a8/2727 apache的一些配置主要是通过 ...
- web.config中sessionState节点的配置方案
web.config中sessionState节点的配置方案 web.config关于sessionState节点的配置方案,sessionState有五种模式:Custom,off,inProc,S ...
- gVim 配置方案 采用Vundle管理插件
在Linux下配置vim非常简单,尤其是采用Vundle来管理插件,使得一切用起来得心应手. Maple大神在github上公布了自己的vim配置方案,相当方便好用.详见 https://github ...
随机推荐
- win10实现倒计时锁屏,休眠
@ECHO OFF&SETLOCAL ENABLEDELAYEDEXPANSION SET /a s=10+1FOR /l %%i in (1,1,!s!) do ( SET /a s-=1 ...
- browse下载插件DownThemAll!
DownThemAll!是一个不错的下载插件,它安装在各类browse上.
- 【爬虫系列】0. 无内鬼,破解前端JS参数签名
PS:这是一个系列,坐等我慢慢填坑. PS:不太会直接能跑的代码,抛砖引玉. PS:那些我也不太熟练的就不搞了,包括(破滑块.验证码..) PS: 反编译搞Apk会有很长的几个文章,稍后慢慢更. 最近 ...
- 【LOJ 109 并查集】 并查集
题目描述 这是一道模板题. 维护一个 n 点的无向图,支持: 加入一条连接 u 和 v 的无向边 查询 u 和 v 的连通性 由于本题数据较大,因此输出的时候采用特殊的输出方式:用 0 或 1 代表每 ...
- 【排序+模拟】谁拿了最多奖学金 luogu-1051
题目描述 某校的惯例是在每学期的期末考试之后发放奖学金.发放的奖学金共有五种,获取的条件各自不同: 院士奖学金,每人$ 8000 $元,期末平均成绩高于\(80\)分(\(>80\)),并且在本 ...
- tomcat的单例多线程代码示例(十)
一.懒汉式单例多线程模式 1.创建模拟的servlet生成器 package cn.bjsxt.sing; import java.util.UUID; public class LszySingle ...
- 开源低代码平台开发实践二:从 0 构建一个基于 ER 图的低代码后端
前后端分离了! 第一次知道这个事情的时候,内心是困惑的. 前端都出去搞 SPA,SEO 们同意吗? 后来,SSR 来了. 他说:"SEO 们同意了!" 任何人的反对,都没用了,时代 ...
- java正则匹配字符串例子
import java.util.regex.Matcher;import java.util.regex.Pattern; public class sss { public static void ...
- 配置多个git用的ssh key
参考 http://www.sail.name/2018/12/16/ssh-config-of-mac/ 有一点注意 Host 的名字和 HostName改为一致. 因为从git仓库复制的地址是全程 ...
- csredis-in-asp.net core理论实战-哨兵模式-使用示例
csredis 开源地址 https://github.com/2881099/csredis 续上篇 csredis-in-asp.net core理论实战-主从配置.哨兵模式 示例源码 https ...