无需手动输入命令,简单3步即可在K8S集群中启用GPU!
随着全球各大企业开始广泛采用Kubernetes,我们看到Kubernetes正在向新的阶段发展。一方面,Kubernetes被边缘的工作负载所采用并提供超越数据中心的价值。另一方面,Kubernetes正在驱动机器学习(ML)和高质量、高速的数据分析性能的发展。
我们现在所了解到的将Kubernetes应用于机器学习的案例主要源于Kubernetes 1.10中一个的功能,当时图形处理单元(GPUs)成为一个可调度的资源——现在这一功能处于beta版本。单独来看,这两个都是Kubernetes中令人兴奋的发展。更令人兴奋的是,可以使用Kubernetes在数据中心和边缘采用GPU。在数据中心,GPU是一种构建ML库的方式。那些训练过的库将被迁移到边缘Kubernetes集群作为机器学习的推理工具,在尽可能靠近数据收集的地方提供数据分析。
在早些时候,Kubernetes还是为分布式应用程序提供一个CPU和RAM资源的池。如果我们有CPU和RAM池,为什么不能有一个GPU池呢?这当然毫无问题,但不是所有的server都有GPU。所以,如何让我们的server在Kubernetes中可以装配GPU呢?
在本文中,我将阐述在Kubernetes集群中使用GPU的简单方法。在未来的文章中,我们还将GPU推向至边缘并向你展示如何完成这一步骤。为了真正地简化步骤,我将用Rancher UI来操作启用GPU的过程。Rancher UI只是Rancher RESTful APIs的一个客户端。你可以在GitOps、DevOps和其他自动化解决方案中使用其他API的客户端,比如Golang、Python和Terraform。不过,我们不会在此文中深入探讨这些。
本质上看,步骤十分简单:
- 为Kubernetes集群构建基础架构
- 安装Kubernetes
- 从Helm中安装gpu-operator
使用Rancher和可用的GPU资源启动和运行
Rancher是一个多集群管理解决方案并且是上述步骤的粘合剂。你可以在NVIDIA的博客中找到一个简化GPU管理的纯NVIDIA解决方案,以及一些关于gpu-operator与构建没有operator的GPU驱动堆栈有何区别的重要信息。
(https://developer.nvidia.com/blog/nvidia-gpu-operator-simplifying-gpu-management-in-kubernetes/)
前期准备
以下是在Rancher中启动和运行GPU所需的材料清单(BOM):
- Rancher
- GPU Operator(https://nvidia.github.io/gpu-operator/)
- 基础架构——我们将在AWS上使用GPU节点
在官方文档中,我们有专门的章节阐述如何高可用安装Rancher,所以我们假设你已经将Rancher安装完毕:
https://docs.rancher.cn/docs/rancher2/installation/k8s-install/_index/
流程步骤
使用GPUs安装Kubernetes集群
Rancher安装之后,我们首先将构建和配置一个Kubernetes集群(你可以使用任何带有NVIDIA GPU的集群)。
使用Global上下文,我们选择Add Cluster

并在“来自云服务商提供的主机”部分,选择Amazon EC2。

我们是通过节点驱动来实现的—— 一组预配置的基础设施模板,其中一些模板有GPU资源。
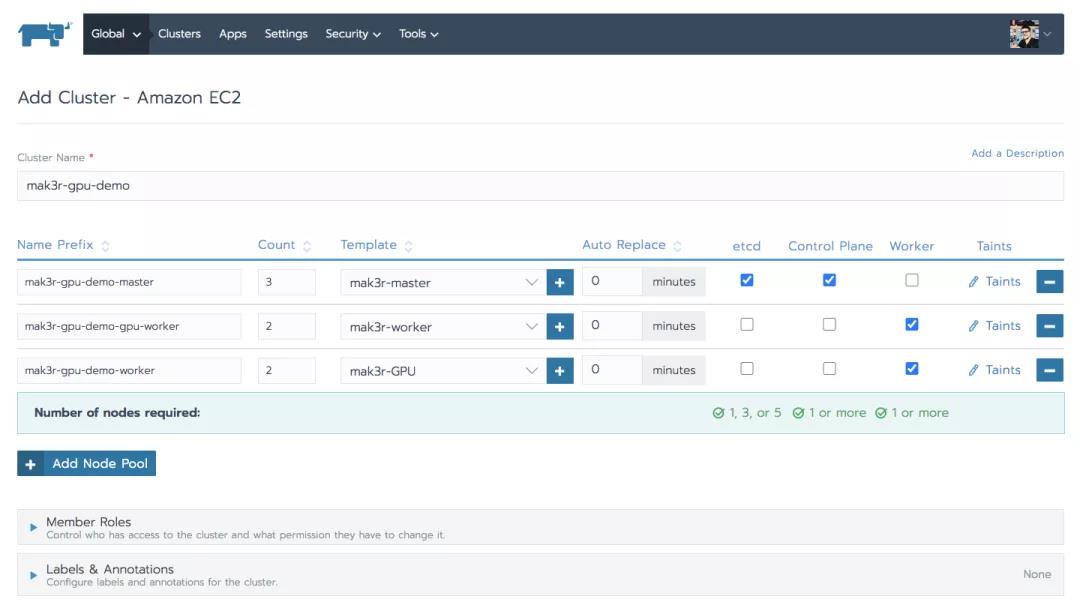
注意到这里有3个节点池:一个是为master准备的,一个是为标准的worker节点准备的,另一个是为带GPU的worker准备的。GPU的模板基于p3.2xlarge机器类型,使用Ubuntu 18.04亚马逊机器镜像或AMI(ami-0ac80df6eff0e70b5)。当然,这些选择是根据每个基础设施提供商和企业需求而变化的。另外,我们将 “Add Cluster”表单中的Kubernetes选项设置为默认值。
设置GPU Operator
现在,我们将使用GPU Operator库(https://nvidia.github.io/gpu-operator)在Rancher中设置一个catalog。(也有其他的解决方案可以暴露GPU,包括使用Linux for Tegra [L4T] Linux发行版或设备插件)在撰写本文时,GPU Operator已经通过NVIDIA Tesla Driver 440进行了测试和验证。
使用Rancher Global上下文菜单,我们选择要安装到的集群:
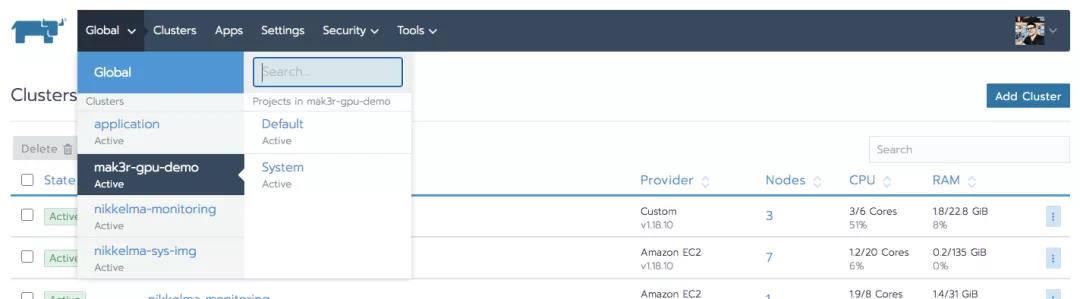
然后使用Tools菜单来查看catalog列表。
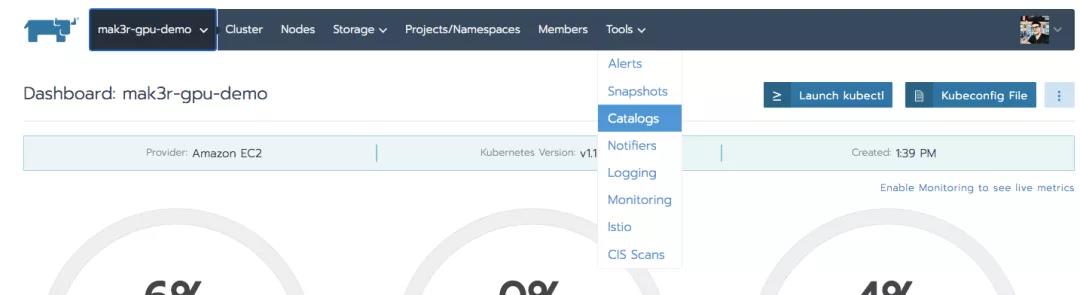
点击Add Catalog按钮并且给其命名,然后添加url:https://nvidia.github.io/gpu-operator
我们选择了Helm v3和集群范围。我们点击Create以添加Catalog到Rancher。当使用自动化时,我们可以将这一步作为集群构建的一部分。根据企业策略,我们可以添加这个Catalog到每个集群中,即使它还没有GPU节点或节点池。这一步为我们提供了访问GPU Operator chart的机会,我们接下来将安装它。
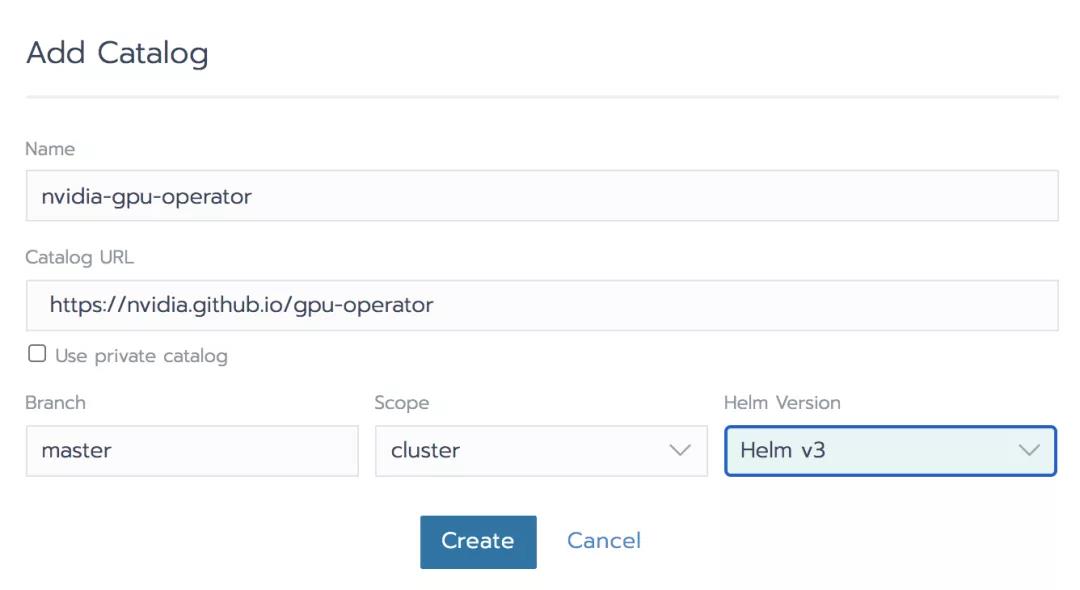
现在我们想要使用左上角的Rancher上下文菜单以进入集群的“System”项目,我们在这里添加了GPU Operator功能。

在System项目中,选择Apps:
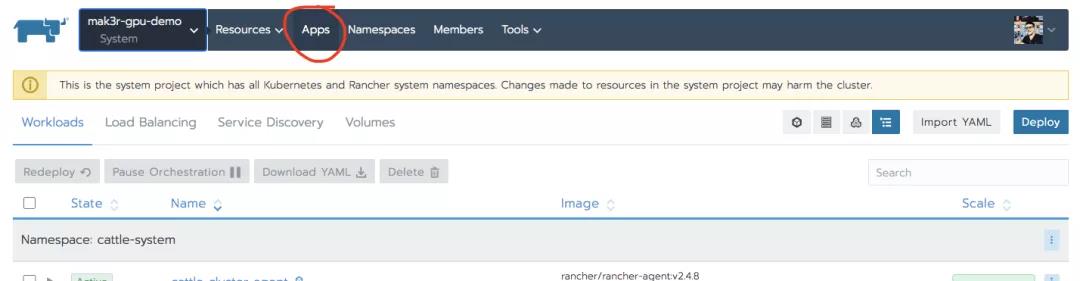
然后点击右上方的Launch按钮。
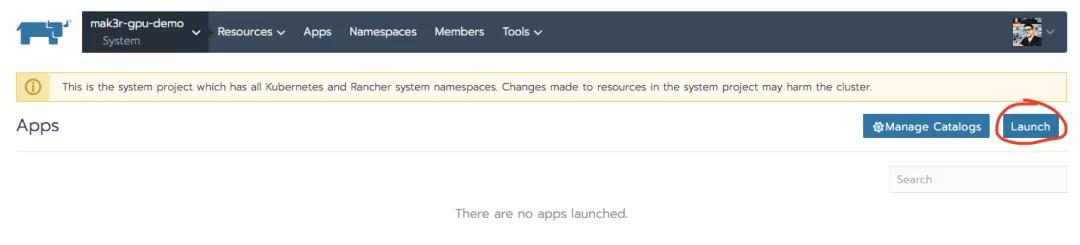
我们可以搜索“nvidia”或者向下滚动到我们刚刚创建的catalog。
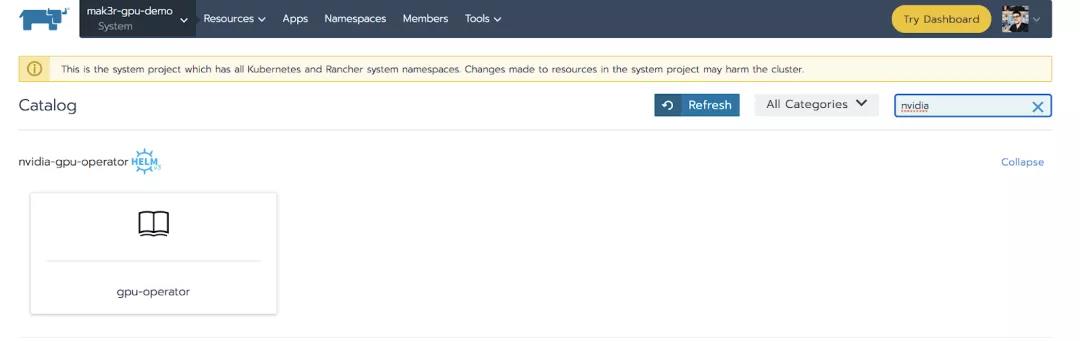
点击gpu-operator app,然后在页面底部点击Launch。
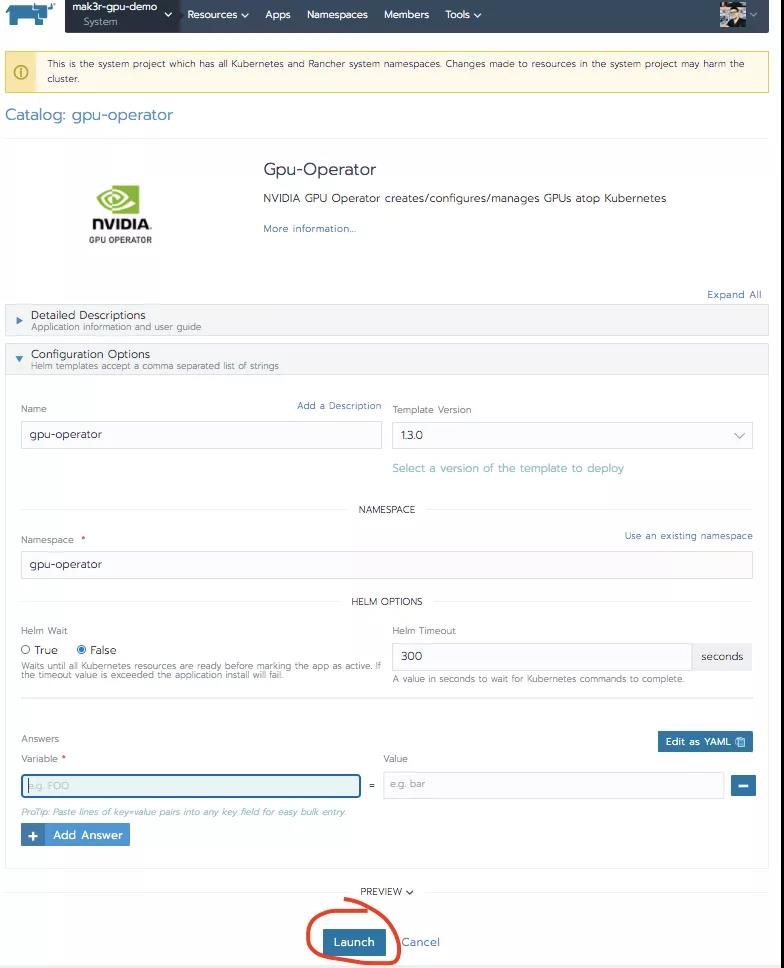
在这种情况下,所有的默认值都应该没问题。同样,我们可以通过Rancher APIs将这一步骤添加到自动化中。
利用GPU
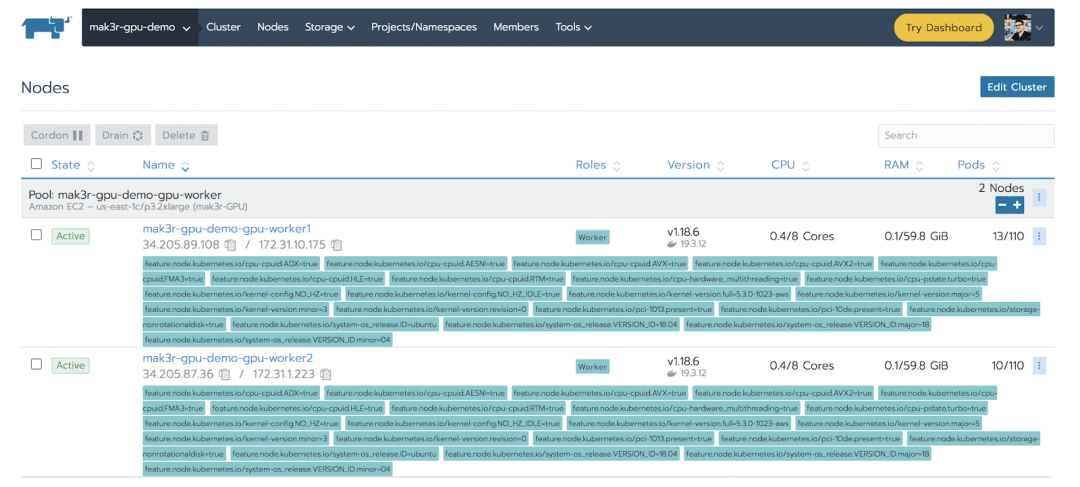
既然GPU已经可以访问,我们现在可以部署一个GPU-capable 工作负载。同时,我们可以通过在Rancher中查看Cluster -> Nodes的页面验证安装是否成功。我们看到GPU Operator已经安装了Node Feature Discovery (NFD)并且给我们的节点贴上了GPU使用的标签。
总 结
之所以能够采用如此简单的方法就能够让Kubernetes与GPU一起运行,离不开这3个重要部分:
- NVIDIA的GPU Operator
- 来自Kubernetes同名SIG的Node Feature Discovery(NFD)。
- Rancher的集群部署和catalog app集成
欢迎您根据本教程动手尝试,也请继续保持关注,在之后的教程中我们会尝试将GPU引用至边缘。
无需手动输入命令,简单3步即可在K8S集群中启用GPU!的更多相关文章
- Docker 一步搞定 ZooKeeper 集群的搭建
Docker 一步搞定 ZooKeeper 集群的搭建 背景 原来学习 ZK 时, 我是在本地搭建的伪集群, 虽然说使用起来没有什么问题, 但是总感觉部署起来有点麻烦. 刚好我发现了 ZK 已经有了 ...
- 使用 Docker 一步搞定 ZooKeeper 集群的搭建
背景 原来学习 ZK 时, 我是在本地搭建的伪集群, 虽然说使用起来没有什么问题, 但是总感觉部署起来有点麻烦. 刚好我发现了 ZK 已经有了 Docker 的镜像了, 于是就尝试了一下, 发现真是爽 ...
- 手把手教你在 TKE 集群中实现简单的蓝绿发布和灰度发布
概述 如何在腾讯云 Kubernetes 集群实现蓝绿发布和灰度发布?通常要向集群额外部署其它开源工具来实现,比如 Nginx Ingress,Traefik 等,或者让业务上 Service Mes ...
- 6.K8s集群升级、etcd备份和恢复、资源对象及其yaml文件使用总结、常用维护命令
1.K8s集群升级 集群升级有一定的风险,需充分测试验证后实施 集群升级需要停止服务,可以采用逐个节点滚动升级的方式 1.1 准备新版本二进制文件 查看现在的版本 root@k8-master1:~# ...
- [k8s]简单启动一个k8s集群
简单启动一个k8s集群 kube-master mkdir -p /root/logs/api-audit /root/logs/controller /root/logs/scheduler kub ...
- 【Oracle】RAC集群中的命令
数据库名称:racdb 节点名称:rac3.rac4 注:以下命令均在grid用户中执行 1.查看集群节点的状态: [grid@rac3 ~]$ crsctl check cluster [grid@ ...
- 使用kubectl管理Kubernetes(k8s)集群:常用命令,查看负载,命名空间namespace管理
目录 一.系统环境 二.前言 三.kubectl 3.1 kubectl语法 3.2 kubectl格式化输出 四.kubectl常用命令 五.查看kubernetes集群node节点和pod负载 5 ...
- 如何将新项目添加到github仓库中?只需简单几步~即可实现
问题描述:新建了一个项目,如何将其设置为git项目?如何关联到github上的仓库? 只需简单几步,但前提是需要已经安装好了git,并且有github账户 本文使用IntelliJ IDEA 其他编辑 ...
- 简单使用Mysql-Cluster-7.5搭建数据库集群
阅读目录 前言 mysql cluster中的几个概念解释 架构图及说明 下载mysql cluster 安装mysql cluster之前 安装配置管理节点 安装配置数据和mysql节点 测试 启动 ...
随机推荐
- linux初级之总结复习
一.linux命令复习 1.ls:列出当前目录下的文件 -h: -l: -d: -a: 2. man: 命令帮助手册 3. cd: 切换目录 -: ~: ..: cd: 4. pwd: 显示当前工作 ...
- python文件处理(对比和筛选)版本2
场景:对比两个txt文件的差异,将对比结果写入html,将不同部分写入另一个txt #!/user/bin/python #!coding=utf-8 # -*- coding: utf-8 -*- ...
- Day029 JDK8中新日期和时间API (二)
# JDK8中新日期和时间API (二) Instant介绍 Instant:时间线上的一个瞬时点. 这可能被用来记录应用程序中的事件时间 戳. 在处理时间和日期的时候,我们通常会想到年,月,日,时, ...
- mybatis运行出现org.apache.ibatis.binding.BindingException
今天学习mybatis的第一天,发现用junit测试报出了次异常:org.apache.ibatis.binding.BindingException: Type interface cn.dzp.d ...
- 回文词——线性dp
#include<iostream> #include<cstdio> using namespace std; int n,f[5002][5002]; char str1[ ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- NVIDIA 认证系统
NVIDIA 认证系统 AI 是这个时代最强大的技术,需要新一代经过调整和测试的计算机来推动其发展. 自 1 月 27 日开始,可从 NVIDIA 合作伙伴处获取用于数据中心的新型加速服务器,推动 A ...
- TensorRT Analysis Report分析报告
TensorRT Analysis Report 一.介绍 TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟.高吞吐率的部署推理.TensorRT可 ...
- Java设计模式:23种设计模式全面解析(超级详细)以及在源码中的应用
从网络上找的设计模式, 很全面,只要把UML类图看懂了, 照着类图将代码实现是很容易的事情. 步骤: 先看懂类图, 然后将代码实现, 之后再看文字 http://c.biancheng.net/des ...
- JAVA 进行图片中文字识别(准确度高)!!!
OCR 识别文字项目 该项目 可以进行两种方式进行身份证识别 1. 使用百度接口 1.1 application-dev.yml配置 ocr: # 使用baiduOcr 需要有Ocr服务器 使用百度需 ...