k8s endpoints controller分析
k8s endpoints controller分析
endpoints controller简介
endpoints controller是kube-controller-manager组件中众多控制器中的一个,是 endpoints 资源对象的控制器,其通过对service、pod 2种资源的监听,当这2种资源发生变化时会触发 endpoints controller 对相应的endpoints资源进行调谐操作,从而完成endpoints对象的新建、更新、删除等操作。
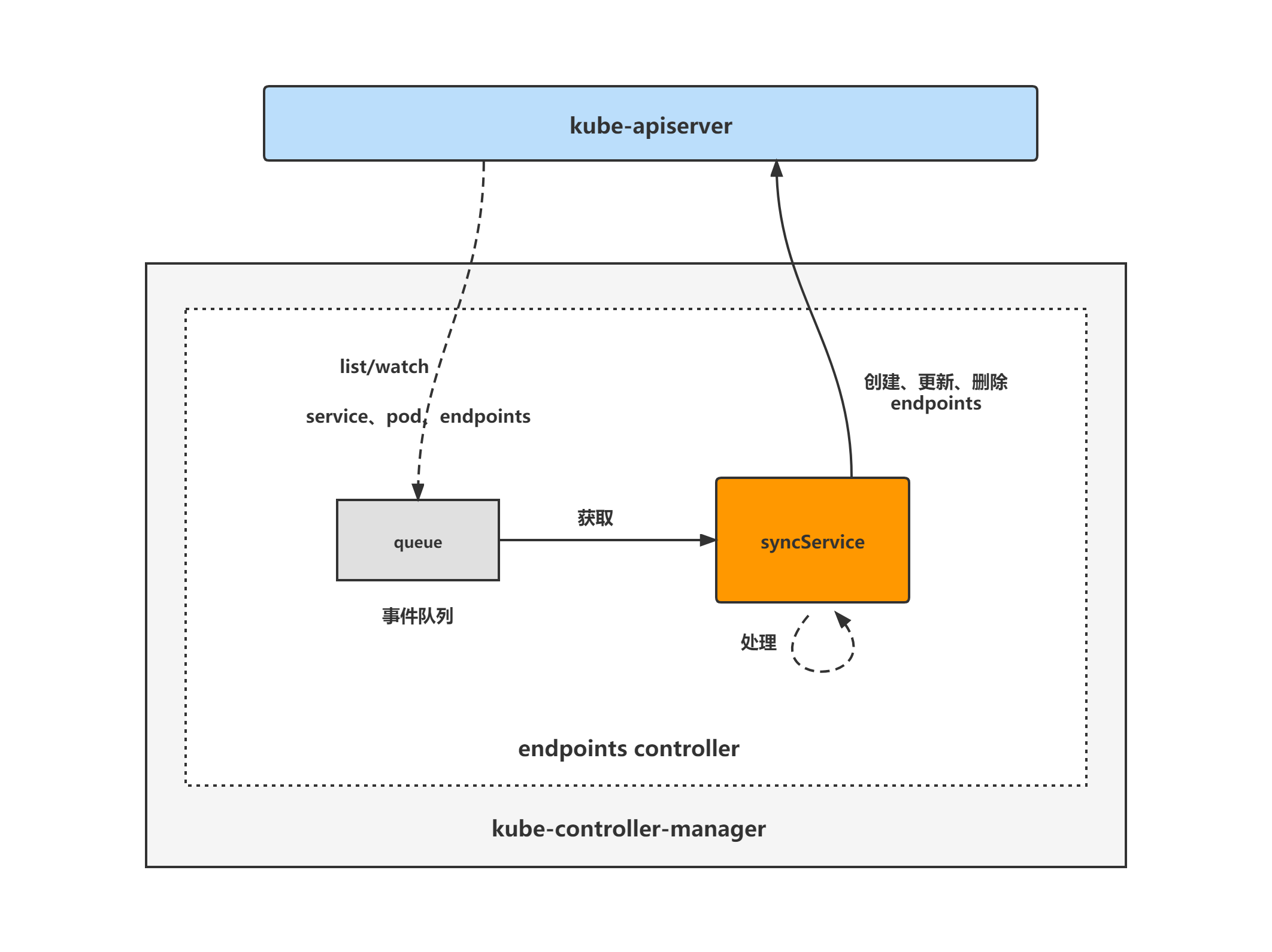
endpoints controller架构图
endpoints controller的大致组成和处理流程如下图,endpoints controller对pod、service对象注册了event handler,当有事件时,会watch到然后将对应的service对象放入到queue中,然后syncService方法为endpoints controller调谐endpoints对象的核心处理逻辑所在,从queue中取出service对象,再查询相应的pod对象列表,然后对endpoints对象做调谐处理。
service对象简介
Service 是对一组提供相同功能的 Pods 的抽象,并为它们提供一个统一的入口。借助 Service,应用可以方便的实现服务发现与负载均衡,并实现应用的零宕机升级。Service 通过标签来选取服务后端,这些匹配标签的 Pod IP 和端口列表组成 endpoints,由 kube-proxy 负责将服务 IP 负载均衡到这些 endpoints 上。
service的四种类型如下。
(1)ClusterIP
类型为ClusterIP的service,这个service有一个Cluster IP,其实就一个VIP,具体实现原理依靠kubeproxy组件,通过iptables或是ipvs实现。该类型的service 只能在集群内访问。
client访问Cluster IP,通过iptables或ipvs规则转到Real Server(endpoints),从而达到负载均衡的效果。
Headless Service
特殊的ClusterIP,通过指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。
使用场景一:自主选择权,client自行决定使用哪个Real Server,可以通过查询DNS来获取Real Server的信息。
使用场景二:Headless Service的对应的每一个Endpoints,即每一个Pod,都会有对应的DNS域名,这样Pod之间就可以通过域名互相访问(该用法常用于statefulset)。
(2)NodePort
在 ClusterIP 基础上为 Service在每台机器上绑定一个端口,这样就可以通过<NodeIP>:NodePort来访问该服务。在集群内,NodePort 服务仍然像之前的 ClusterIP 服务一样访问。
(3)LoadBalancer
在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到 <NodeIP>:NodePort。
(4)ExternalName
将服务通过 DNS CNAME 记录方式转发到指定的域名。
apiVersion: v1
kind: Service
metadata:
name: baidu-service
namespace: test
spec:
type: ExternalName
externalName: www.baidu.com
endpoints对象简介
endpoints中指定了需要连接的服务IP和端口,可以认为endpoints定义了service的backend后端。当访问service时,实际上是会将请求负载均衡到endpoints定义的服务IP与端口上面去。
另外,endpoints对象与同名称的service对象相关联。
endpoints controller分析将分为两大块进行,分别是:
(1)endpoints controller初始化与启动分析;
(2)endpoints controller处理逻辑分析。
1.endpoints controller初始化与启动分析
基于tag v1.17.4
https://github.com/kubernetes/kubernetes/releases/tag/v1.17.4
直接看到startEndpointController函数,作为endpoints controller启动分析的入口。
startEndpointController
在startEndpointController函数中启动了一个goroutine,先是调用了endpointcontroller的NewEndpointController方法初始化endpoints controller,接着调用Run方法启动endpoints controller。
// cmd/kube-controller-manager/app/core.go
func startEndpointController(ctx ControllerContext) (http.Handler, bool, error) {
go endpointcontroller.NewEndpointController(
ctx.InformerFactory.Core().V1().Pods(),
ctx.InformerFactory.Core().V1().Services(),
ctx.InformerFactory.Core().V1().Endpoints(),
ctx.ClientBuilder.ClientOrDie("endpoint-controller"),
ctx.ComponentConfig.EndpointController.EndpointUpdatesBatchPeriod.Duration,
).Run(int(ctx.ComponentConfig.EndpointController.ConcurrentEndpointSyncs), ctx.Stop)
return nil, true, nil
}
1.1 NewEndpointController
先来看到endpoints controller的初始化方法NewEndpointController。
从NewEndpointController函数代码中可以看到,endpoints controller注册了三个informer,分别是podInformer、serviceInformer与endpointsInformer,以及注册了service与pod对象的EventHandler,也即对这2个对象的event进行监听,把event放入事件队列,由endpoints controller的核心处理方法做做处理。
// pkg/controller/endpoint/endpoints_controller.go
func NewEndpointController(podInformer coreinformers.PodInformer, serviceInformer coreinformers.ServiceInformer,
endpointsInformer coreinformers.EndpointsInformer, client clientset.Interface, endpointUpdatesBatchPeriod time.Duration) *EndpointController {
broadcaster := record.NewBroadcaster()
broadcaster.StartLogging(klog.Infof)
broadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: client.CoreV1().Events("")})
recorder := broadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "endpoint-controller"})
if client != nil && client.CoreV1().RESTClient().GetRateLimiter() != nil {
ratelimiter.RegisterMetricAndTrackRateLimiterUsage("endpoint_controller", client.CoreV1().RESTClient().GetRateLimiter())
}
e := &EndpointController{
client: client,
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "endpoint"),
workerLoopPeriod: time.Second,
}
serviceInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: e.onServiceUpdate,
UpdateFunc: func(old, cur interface{}) {
e.onServiceUpdate(cur)
},
DeleteFunc: e.onServiceDelete,
})
e.serviceLister = serviceInformer.Lister()
e.servicesSynced = serviceInformer.Informer().HasSynced
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: e.addPod,
UpdateFunc: e.updatePod,
DeleteFunc: e.deletePod,
})
e.podLister = podInformer.Lister()
e.podsSynced = podInformer.Informer().HasSynced
e.endpointsLister = endpointsInformer.Lister()
e.endpointsSynced = endpointsInformer.Informer().HasSynced
e.triggerTimeTracker = endpointutil.NewTriggerTimeTracker()
e.eventBroadcaster = broadcaster
e.eventRecorder = recorder
e.endpointUpdatesBatchPeriod = endpointUpdatesBatchPeriod
e.serviceSelectorCache = endpointutil.NewServiceSelectorCache()
return e
}
1.2 Run
主要看到for循环处,根据workers的值(来源于kcm启动参数concurrent-endpoint-syncs配置),启动相应数量的goroutine,跑e.worker方法。
// pkg/controller/endpoint/endpoints_controller.go
func (e *EndpointController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer e.queue.ShutDown()
klog.Infof("Starting endpoint controller")
defer klog.Infof("Shutting down endpoint controller")
if !cache.WaitForNamedCacheSync("endpoint", stopCh, e.podsSynced, e.servicesSynced, e.endpointsSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(e.worker, e.workerLoopPeriod, stopCh)
}
go func() {
defer utilruntime.HandleCrash()
e.checkLeftoverEndpoints()
}()
<-stopCh
}
1.2.1 worker
直接看到processNextWorkItem方法,从队列queue中取出一个key,然后调用e.syncService方法对该key做处理,e.syncService方法也即endpoints controller的核心处理方法,后面会做详细分析。
// pkg/controller/endpoint/endpoints_controller.go
func (e *EndpointController) worker() {
for e.processNextWorkItem() {
}
}
func (e *EndpointController) processNextWorkItem() bool {
eKey, quit := e.queue.Get()
if quit {
return false
}
defer e.queue.Done(eKey)
err := e.syncService(eKey.(string))
e.handleErr(err, eKey)
return true
}
2.endpoints controller核心处理分析
基于tag v1.17.4
https://github.com/kubernetes/kubernetes/releases/tag/v1.17.4
直接看到syncService方法,作为endpoints controller核心处理分析的入口。
2.1 核心处理逻辑-syncService
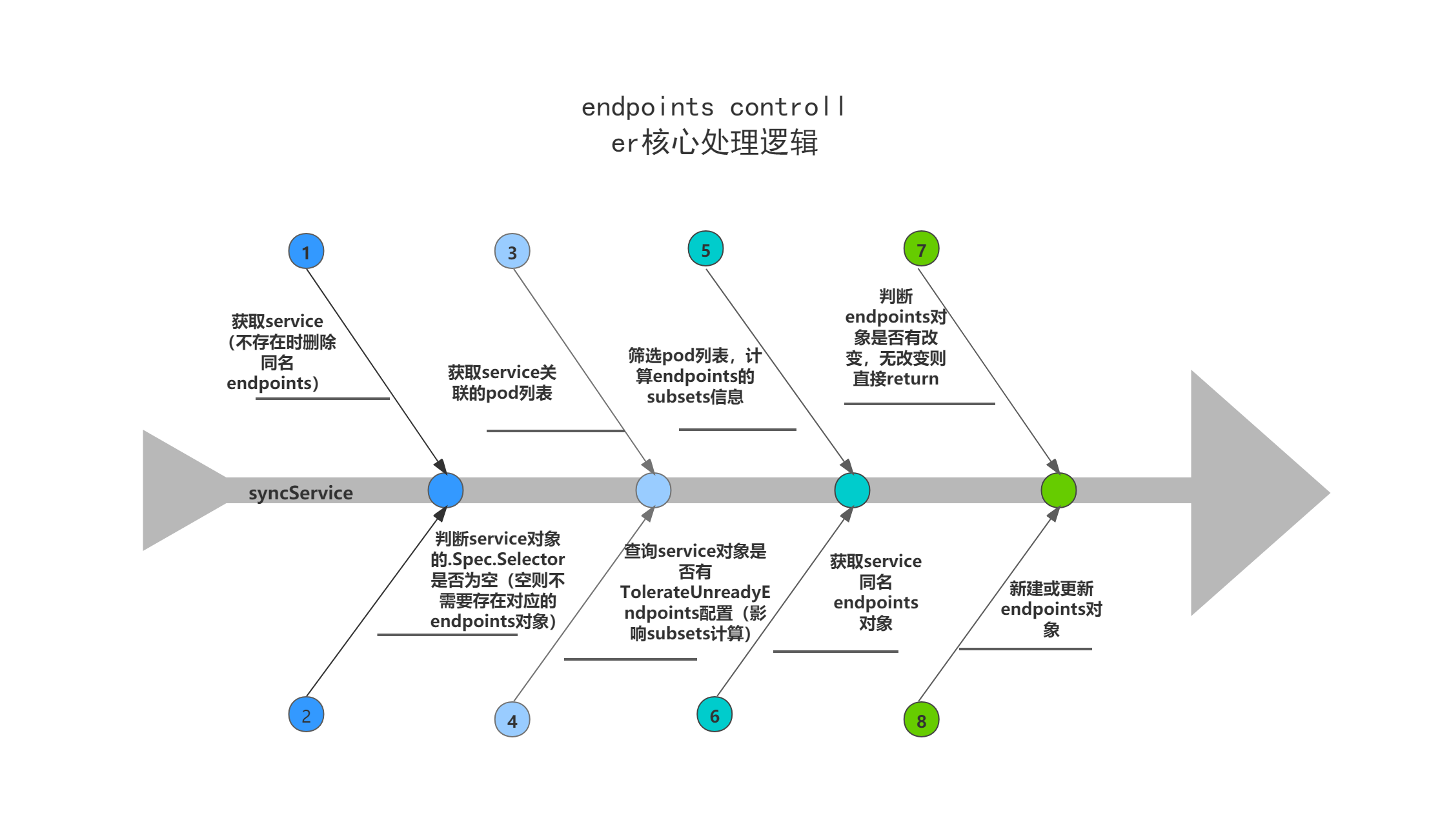
主要逻辑:
(1)获取service对象,当查询不到该service对象时,删除同名endpoints对象;
(2)当service对象的.Spec.Selector为空时,不存在对应的endpoints对象,直接返回;
(3)根据service对象的.Spec.Selector,查询与service对象匹配的pod列表;
(4)查询service的annotations中是否配置了TolerateUnreadyEndpoints,代表允许为unready的pod也创建endpoints,该配置将会影响下面对endpoints对象的subsets信息的计算;
(5)遍历service对象匹配的pod列表,找出合适的pod,计算endpoints的subsets信息;
遍历pod列表时如何计算出subsets?
(5.1)过滤掉pod ip为空的pod;
(5.2)当TolerateUnreadyEndpoints配置为false且pod的deletetimestamp不为空时,过滤掉该pod;
(5.3)当service没有ports配置,且ClusterIP为None时,为headless service,调用addEndpointSubset函数计算subsets,计算出来的subsets中的ports信息为空;
(5.4)当service有ports配置,遍历ports配置,循环调用addEndpointSubset函数计算subsets(addEndpointSubset函数在后面会展开分析)。
(6)获取endpoints对象;
(7)判断现存endpoints对象与调谐中重新计算出来的的endpoints对象的subsets与labels是否一致,一致则无需更新,直接返回;
(8)当endpoints对象不存在时新建endpoints对象,当endpoints对象存在时更新endpoints对象。
func (e *EndpointController) syncService(key string) error {
startTime := time.Now()
defer func() {
klog.V(4).Infof("Finished syncing service %q endpoints. (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
service, err := e.serviceLister.Services(namespace).Get(name)
if err != nil {
if !errors.IsNotFound(err) {
return err
}
// Delete the corresponding endpoint, as the service has been deleted.
// TODO: Please note that this will delete an endpoint when a
// service is deleted. However, if we're down at the time when
// the service is deleted, we will miss that deletion, so this
// doesn't completely solve the problem. See #6877.
err = e.client.CoreV1().Endpoints(namespace).Delete(name, nil)
if err != nil && !errors.IsNotFound(err) {
return err
}
e.triggerTimeTracker.DeleteService(namespace, name)
return nil
}
if service.Spec.Selector == nil {
// services without a selector receive no endpoints from this controller;
// these services will receive the endpoints that are created out-of-band via the REST API.
return nil
}
klog.V(5).Infof("About to update endpoints for service %q", key)
pods, err := e.podLister.Pods(service.Namespace).List(labels.Set(service.Spec.Selector).AsSelectorPreValidated())
if err != nil {
// Since we're getting stuff from a local cache, it is
// basically impossible to get this error.
return err
}
// If the user specified the older (deprecated) annotation, we have to respect it.
tolerateUnreadyEndpoints := service.Spec.PublishNotReadyAddresses
if v, ok := service.Annotations[TolerateUnreadyEndpointsAnnotation]; ok {
b, err := strconv.ParseBool(v)
if err == nil {
tolerateUnreadyEndpoints = b
} else {
utilruntime.HandleError(fmt.Errorf("Failed to parse annotation %v: %v", TolerateUnreadyEndpointsAnnotation, err))
}
}
// We call ComputeEndpointLastChangeTriggerTime here to make sure that the
// state of the trigger time tracker gets updated even if the sync turns out
// to be no-op and we don't update the endpoints object.
endpointsLastChangeTriggerTime := e.triggerTimeTracker.
ComputeEndpointLastChangeTriggerTime(namespace, service, pods)
subsets := []v1.EndpointSubset{}
var totalReadyEps int
var totalNotReadyEps int
for _, pod := range pods {
if len(pod.Status.PodIP) == 0 {
klog.V(5).Infof("Failed to find an IP for pod %s/%s", pod.Namespace, pod.Name)
continue
}
if !tolerateUnreadyEndpoints && pod.DeletionTimestamp != nil {
klog.V(5).Infof("Pod is being deleted %s/%s", pod.Namespace, pod.Name)
continue
}
ep, err := podToEndpointAddressForService(service, pod)
if err != nil {
// this will happen, if the cluster runs with some nodes configured as dual stack and some as not
// such as the case of an upgrade..
klog.V(2).Infof("failed to find endpoint for service:%v with ClusterIP:%v on pod:%v with error:%v", service.Name, service.Spec.ClusterIP, pod.Name, err)
continue
}
epa := *ep
if endpointutil.ShouldSetHostname(pod, service) {
epa.Hostname = pod.Spec.Hostname
}
// Allow headless service not to have ports.
if len(service.Spec.Ports) == 0 {
if service.Spec.ClusterIP == api.ClusterIPNone {
subsets, totalReadyEps, totalNotReadyEps = addEndpointSubset(subsets, pod, epa, nil, tolerateUnreadyEndpoints)
// No need to repack subsets for headless service without ports.
}
} else {
for i := range service.Spec.Ports {
servicePort := &service.Spec.Ports[i]
portName := servicePort.Name
portProto := servicePort.Protocol
portNum, err := podutil.FindPort(pod, servicePort)
if err != nil {
klog.V(4).Infof("Failed to find port for service %s/%s: %v", service.Namespace, service.Name, err)
continue
}
var readyEps, notReadyEps int
epp := &v1.EndpointPort{Name: portName, Port: int32(portNum), Protocol: portProto}
subsets, readyEps, notReadyEps = addEndpointSubset(subsets, pod, epa, epp, tolerateUnreadyEndpoints)
totalReadyEps = totalReadyEps + readyEps
totalNotReadyEps = totalNotReadyEps + notReadyEps
}
}
}
subsets = endpoints.RepackSubsets(subsets)
// See if there's actually an update here.
currentEndpoints, err := e.endpointsLister.Endpoints(service.Namespace).Get(service.Name)
if err != nil {
if errors.IsNotFound(err) {
currentEndpoints = &v1.Endpoints{
ObjectMeta: metav1.ObjectMeta{
Name: service.Name,
Labels: service.Labels,
},
}
} else {
return err
}
}
createEndpoints := len(currentEndpoints.ResourceVersion) == 0
if !createEndpoints &&
apiequality.Semantic.DeepEqual(currentEndpoints.Subsets, subsets) &&
apiequality.Semantic.DeepEqual(currentEndpoints.Labels, service.Labels) {
klog.V(5).Infof("endpoints are equal for %s/%s, skipping update", service.Namespace, service.Name)
return nil
}
newEndpoints := currentEndpoints.DeepCopy()
newEndpoints.Subsets = subsets
newEndpoints.Labels = service.Labels
if newEndpoints.Annotations == nil {
newEndpoints.Annotations = make(map[string]string)
}
if !endpointsLastChangeTriggerTime.IsZero() {
newEndpoints.Annotations[v1.EndpointsLastChangeTriggerTime] =
endpointsLastChangeTriggerTime.Format(time.RFC3339Nano)
} else { // No new trigger time, clear the annotation.
delete(newEndpoints.Annotations, v1.EndpointsLastChangeTriggerTime)
}
if newEndpoints.Labels == nil {
newEndpoints.Labels = make(map[string]string)
}
if !helper.IsServiceIPSet(service) {
newEndpoints.Labels = utillabels.CloneAndAddLabel(newEndpoints.Labels, v1.IsHeadlessService, "")
} else {
newEndpoints.Labels = utillabels.CloneAndRemoveLabel(newEndpoints.Labels, v1.IsHeadlessService)
}
klog.V(4).Infof("Update endpoints for %v/%v, ready: %d not ready: %d", service.Namespace, service.Name, totalReadyEps, totalNotReadyEps)
if createEndpoints {
// No previous endpoints, create them
_, err = e.client.CoreV1().Endpoints(service.Namespace).Create(newEndpoints)
} else {
// Pre-existing
_, err = e.client.CoreV1().Endpoints(service.Namespace).Update(newEndpoints)
}
if err != nil {
if createEndpoints && errors.IsForbidden(err) {
// A request is forbidden primarily for two reasons:
// 1. namespace is terminating, endpoint creation is not allowed by default.
// 2. policy is misconfigured, in which case no service would function anywhere.
// Given the frequency of 1, we log at a lower level.
klog.V(5).Infof("Forbidden from creating endpoints: %v", err)
// If the namespace is terminating, creates will continue to fail. Simply drop the item.
if errors.HasStatusCause(err, v1.NamespaceTerminatingCause) {
return nil
}
}
if createEndpoints {
e.eventRecorder.Eventf(newEndpoints, v1.EventTypeWarning, "FailedToCreateEndpoint", "Failed to create endpoint for service %v/%v: %v", service.Namespace, service.Name, err)
} else {
e.eventRecorder.Eventf(newEndpoints, v1.EventTypeWarning, "FailedToUpdateEndpoint", "Failed to update endpoint %v/%v: %v", service.Namespace, service.Name, err)
}
return err
}
return nil
}
2.1.1 addEndpointSubset
下面来展开分析下计算service对象subsets信息的函数addEndpointSubset,计算出的subsets包括了Address(ReadyAddresses)与NotReadyAddresses。
主要逻辑:
(1)当配置了tolerateUnreadyEndpoints且为true时,或pod处于ready状态时,将计算进subsets中的Addresses;
(2)当配置了tolerateUnreadyEndpoints且为false或没有配置时,或pod不处于ready状态时,调用shouldPodBeInEndpoints函数,返回true时将计算进subsets中的NotReadyAddresses。
(2.1)当pod.Spec.RestartPolicy为Never,Pod Status.Phase不为Failed/Successed时,将计算进subsets中的NotReadyAddresses;
(2.2)当pod.Spec.RestartPolicy为OnFailure, Pod Status.Phase不为Successed时,Pod对应的EndpointAddress也会被加入到NotReadyAddresses中;
(2.3)其他情况下,将计算进subsets中的NotReadyAddresses。
// pkg/controller/endpoint/endpoints_controller.go
func addEndpointSubset(subsets []v1.EndpointSubset, pod *v1.Pod, epa v1.EndpointAddress,
epp *v1.EndpointPort, tolerateUnreadyEndpoints bool) ([]v1.EndpointSubset, int, int) {
var readyEps int
var notReadyEps int
ports := []v1.EndpointPort{}
if epp != nil {
ports = append(ports, *epp)
}
if tolerateUnreadyEndpoints || podutil.IsPodReady(pod) {
subsets = append(subsets, v1.EndpointSubset{
Addresses: []v1.EndpointAddress{epa},
Ports: ports,
})
readyEps++
} else if shouldPodBeInEndpoints(pod) {
klog.V(5).Infof("Pod is out of service: %s/%s", pod.Namespace, pod.Name)
subsets = append(subsets, v1.EndpointSubset{
NotReadyAddresses: []v1.EndpointAddress{epa},
Ports: ports,
})
notReadyEps++
}
return subsets, readyEps, notReadyEps
}
func shouldPodBeInEndpoints(pod *v1.Pod) bool {
switch pod.Spec.RestartPolicy {
case v1.RestartPolicyNever:
return pod.Status.Phase != v1.PodFailed && pod.Status.Phase != v1.PodSucceeded
case v1.RestartPolicyOnFailure:
return pod.Status.Phase != v1.PodSucceeded
default:
return true
}
}
IsPodReady
当在pod的.status.conditions中,type为Ready的status属性值为True时,IsPodReady返回true。
// pkg/api/v1/pod/util.go
// IsPodReady returns true if a pod is ready; false otherwise.
func IsPodReady(pod *v1.Pod) bool {
return IsPodReadyConditionTrue(pod.Status)
}
// GetPodReadyCondition extracts the pod ready condition from the given status and returns that.
// Returns nil if the condition is not present.
func GetPodReadyCondition(status v1.PodStatus) *v1.PodCondition {
_, condition := GetPodCondition(&status, v1.PodReady)
return condition
}
总结
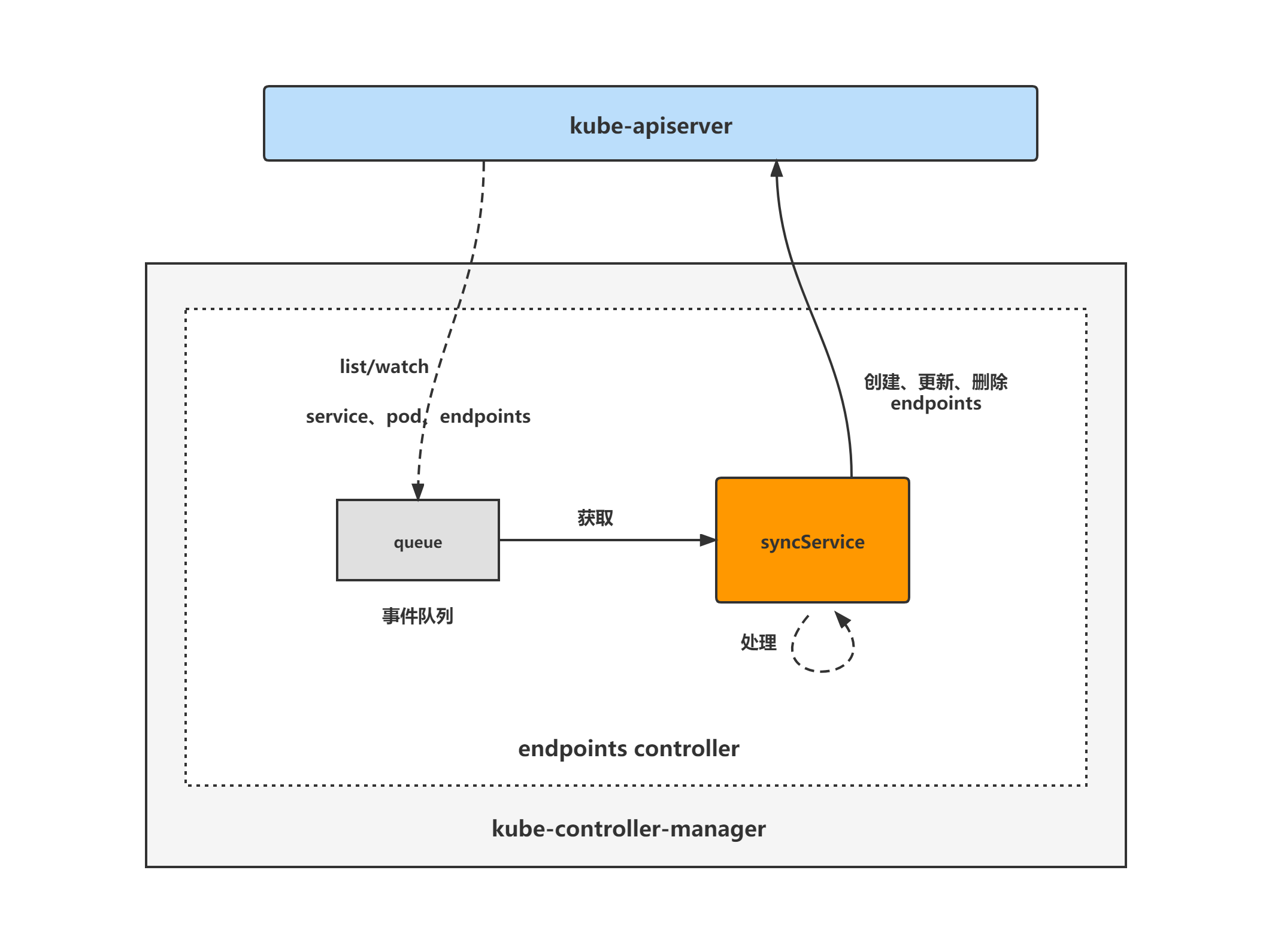
endpoints controller架构图
endpoints controller的大致组成和处理流程如下图,endpoints controller对pod、service对象注册了event handler,当有事件时,会watch到然后将对应的service对象放入到queue中,然后syncService方法为endpoints controller调谐endpoints对象的核心处理逻辑所在,从queue中取出service对象,再查询相应的pod对象列表,然后对endpoints对象做调谐处理。
endpoints controller核心处理逻辑
endpoints controller的核心处理逻辑是获取service对象,当service不存在时删除同名endpoints对象,当存在时,根据service对象所关联的pod列表,计算出endpoints对象的最新subsets信息,然后新建或更新endpoints对象。
k8s endpoints controller分析的更多相关文章
- k8s replicaset controller分析(2)-核心处理逻辑分析
replicaset controller分析 replicaset controller简介 replicaset controller是kube-controller-manager组件中众多控制 ...
- k8s replicaset controller分析(1)-初始化与启动分析
replicaset controller分析 replicaset controller简介 replicaset controller是kube-controller-manager组件中众多控制 ...
- k8s replicaset controller 分析(3)-expectations 机制分析
replicaset controller分析 replicaset controller简介 replicaset controller是kube-controller-manager组件中众多控制 ...
- k8s deployment controller源码分析
deployment controller简介 deployment controller是kube-controller-manager组件中众多控制器中的一个,是 deployment 资源对象的 ...
- k8s statefulset controller源码分析
statefulset controller分析 statefulset简介 statefulset是Kubernetes提供的管理有状态应用的对象,而deployment用于管理无状态应用. 有状态 ...
- k8s daemonset controller源码分析
daemonset controller分析 daemonset controller简介 daemonset controller是kube-controller-manager组件中众多控制器中的 ...
- k8s garbage collector分析(1)-启动分析
k8s garbage collector分析(1)-启动分析 garbage collector介绍 Kubernetes garbage collector即垃圾收集器,存在于kube-contr ...
- k8s源码分析准备工作 - 源码准备
本文原始地址:https://farmer-hutao.github.io/k8s-source-code-analysis/ 项目github地址:https://github.com/farmer ...
- k8s自定义controller设计与实现
k8s自定义controller设计与实现 创建CRD 登录可以执行kubectl命令的机器,创建student.yaml apiVersion: apiextensions.k8s.io/v1bet ...
随机推荐
- Docker安装Jenkins 从GitLab上拉取代码打包SpringBoot项目并部署到服务器
1. 安装Jenkins 采用 Docker 方式安装 jenkins 首先,宿主机上需要安装java和maven,这里我的安装目录如下: 由于是docker安装,jenkins将来是在容器里面运行 ...
- Python+selenium自动化生成测试报告
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Kubernetes全栈架构师(资源调度下)--学习笔记
目录 StatefulSet扩容缩容 StatefulSet更新策略 StatefulSet灰度发布 StatefulSet级联删除和非级联删除 守护进程服务DaemonSet DaemonSet的使 ...
- mysql8.0.20安装教程,mysql下载安装教程8.0.20
mysql8.0.20下载安装教程 mysql8.0.20安装教程 mysql安装包+mysql学习视频+mysql面试指南视频教程 下载地址: 链接:https://pan.baidu.com/s ...
- 聊聊我对 GraphQL 的一些认知
每隔一段时间就能看到一篇 GraphQL 的文章,但是打开文章一看,基本上就是简单的介绍下 GraphQL 的特性.很多文章其实就是 github 上找个 GraphQL 的项目,然后按照对应的 de ...
- 数据库MySQL主从-GTID
1.第一步在主服务器上/etc/my.cnf/下添加 log-bin=log-bin server-id=1 gtid_mode=ON enforce_gtid_consistency 2.第二步:重 ...
- C++核心编程 4 类和对象-对象的初始化和清理
构造函数和析构函数 对象的初始化和清理工作是两个非常重要的安全问题,一个对象或者变量没有初始状态,对其使用结果是未知的,同样,使用完一个对象或变量,没有及时清理,也会造成一定的安全问题.C++利用了构 ...
- 《Spring源码深度解析》学习笔记——Spring的整体架构与容器的基本实现
pring框架是一个分层架构,它包含一系列的功能要素,并被分为大约20个模块,如下图所示 这些模块被总结为以下几个部分: Core Container Core Container(核心容器)包含有C ...
- [Beta]the Agiles Scrum Meeting 9
会议时间:2020.5.24 21:00 1.每个人的工作 今天已完成的工作 成员 已完成的工作 issue yjy 撰写技术博客 tq 实现评测机获取评测状态功能 评测部分增加更多评测指标 wjx ...
- Spring Cloud Gateway GatewayFilter的使用
Spring Cloud Gateway GatewayFilter的使用 一.GatewayFilter的作用 二.Spring Cloud Gateway内置的 GatewayFilter 1.A ...