Kubernetes架构原理
1.了解架构
在研究Kubernetes如何实现其功能之前,先具体了解下Kubernetes集群有哪些组件。Kubernetes集群分为两部分:
- Kubernetes控制平面
- (工作)节点
具体看下这两个部分做了什么,以及内部运行的内容。
控制平面的组件
控制平面负责控制并使得整个集群正常运转。控制平面包含如下组件:
- etcd分布式持久化存储
- API服务器
- 调度器
- 控制器管理器
这些组件用来存储、管理集群状态,但它们不是运行应用的容器。
工作节点上运行的组件
运行容器的任务依赖于每个工作节点上运行的组件:
- Kubelet
- Kubelet服务代理(kube-proxy)
- 容器运行时(Docker、rkt或者其他)
附加组件
除了控制平面(和运行在节点上的组件,还要有几个附加组件,这样才能提供所有之前讨论的功能。包含:
- Kubernetes DNS 服务器
- 仪表板
- Ingress控制器
- Heapster(容器集群监控)1.12版本以上已更改
- 容器网络接口插件(本章后面会做讨论)
1.1 Kubernetes组件的分布式特性
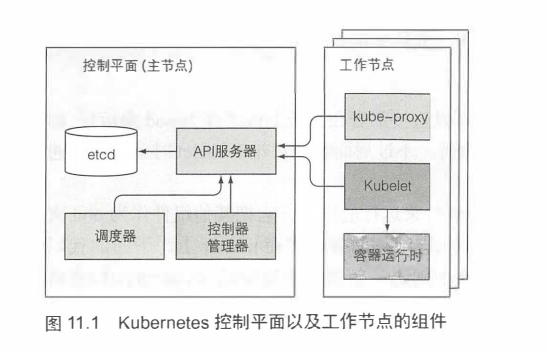
之前提到的组件都是作为单独进程运行的。图11.1描述了各个组件及它们之间的依赖关系。
若要启用Kubernetes提供的所有特性,需要运行所有的这些组件。但是有几个组件无须其他组件,单独运行也能提供非常有用的工作。接下来会详细查看每一个组件。
检查控制平面组件的状态
API服务器对外暴露了一个名为ComponentStatus的API资源,用来显示每个控制平面组件的健康状态。可以通过kubectl列出各个组件以及它们的状态:
$ kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
组件间如何通信
Kubernetes系统组件间只能通过API服务器通信,它们之间不会直接通信。API服务器是和etcd通信的唯一组件。其他组件不会直接和etcd通信,而是通过API服务器来修改集群状态。
API服务器和其他组件的连接基本都是由组件发起的,如图11.1所示。但是,当使用kubectl获取日志、使用kubectl attach连接到一个运行中的容器或运行kubectl port-forward命令时,API服务器会向Kubelet发起连接。
注意:kubectl attach命令和kubectl exec命令类似,区别是:前者会附属到容器中运行着的主进程上,而后者是重新运行一个进程。
单组件运行多实例
尽管工作节点上的组件都需要运行在同一个节点上,控制平面的组件可以被简单地分割在多台服务器上。为了保证高可用性,控制平面的每个组件可以有多个实例。etcd和API服务器的多个实例可以同时并行工作,但是,调度器和控制器管理器在给定时间内只能有一个实例起作用,其他实例处于待命模式。
组件是如何运行的
控制平面的组件以及kube-proxy可以直接部署在系统上或者作为pod来运行(如图11.1所示)。听到这个你可能比较惊讶,不过后面我们讨论Kubelet时就都说得通了。
Kubelet是唯一一直作为常规系统组件来运行的组件,它把其他组件作为pod来运行。为了将控制平面作为pod来运行,Kubelet被部署在master上。下面的代码清单展示了通过kubeadm创建的集群里的kube-system命名空间里的pod。
#代码11.1 作为pod运行的kubernetes组件
$ kubectl get po -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName -n kube-system
POD NODE
kube-controller-manager-master master
kube-dns-2334855451-37d9k master
etcd-master master
kube-apiserver-master master
kube-scheduler-master master
kube-flannel-ds-tgj9k node1
kube-proxy-ny3xm node1
kube-flannel-ds-0eek8 node2
kube-proxy-sp362 node2
kube-flannel-ds-r5yf4 node3
kube-proxy-og9ac node3
如代码清单所示,所有的控制平面组件在主节点上作为pod运行。这里有三个工作节点,每一个节点运行kube-proxy和一个Flannel pod,用来为pod提供重叠网络(后面会再讨论Flannel)。
提示:如代码清单所示,可以通过-o custom-columns选项自定义展示的列以及--sort -by对资源列表进行排序。
现在,对每一个组件进行研究,从控制平面的底层组件---持久化存储组件开始。
1.2 Kubernetes如何使用etcd
让创建的所有对象---pod、ReplicationController、服务和私密凭据等,需要以持久化方式存储到某个地方,这样它们的manifest在API服务器重启和失败的时候才不会丢失。为此,Kubernetes使用了etcd,etcd是一个响应快、分布式、一致的key-value存储。因为它是分布式的,故可以运行多个etcd实例来获取高可用性和更好的性能。
唯一能直接和etcd通信的是Kubernetes的API服务器。所有其他组件通过API服务器间接地读取、写入数据到etcd。这带来一些好处,其中之一就是增强乐观锁系统、验证系统的健壮性;并且,通过把实际存储机制从其他组件抽离,未来替换起来也更容易。值得强调的是,etcd是Kubernetes存储集群状态和元数据的唯一的地方。
关于乐观并发控制
乐观并发控制(有时候指乐观锁)是指一段数据包含一个版本数字,而不是锁住该段数据并阻止读写操作。每当更新数据,版本数就会增加。当更新数据时,就会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。如果增加过,那么更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
两个客户端尝试更新同一个数据条目,只有第一个会成功。
所有的 Kubernetes包含一个metadata.resourceVersion宇段,当更新对象时,客户端需要返回该值到API服务器。如果版本值与etcd中存储的不匹配,API服务器会拒绝该更新。
资源如何存储在etcd中
K8s1.12发布的时候,Kubernetes既可以用etcd版本2也可以用版本3,但目前更推荐版本3,它的性能更好。etcd v2把key存储在一个层级键空间中,这使得键值对类似文件系统的文件。etcd中每个key要么是一个目录,包含其他key,要么是一个常规key,对应一个值。etcd v3不支持目录,但是由于key格式保持不变(键可以包含斜杠),仍然可以认为它们可以被组织为目录。Kubernetes存储所有数据到etcd的/registry下。下面的代码清单显示/registry下存储的一系列key。
#代码清单11.2 etcd中存储的Kubernetes的顶层条目
$ etcdctl ls /registry
/registry/configmaps
/registry/daemonsets
/registry/deployments
/registry/events
/registry/namespaces
/registry/pods
注意:如果使用etcd v3的API, 就无法使用ls命令来查看目录的内容。 但是,可以通过etcdctl get /registry --prefix=true列出所有以给定前缀开始的key。
#代码11.3 /registry/pods 目录下的key
$ etcdctl ls /registry/pods
/registry/pods/default
/registry/pods/kube-system
从名称可以看出,这两个条目对应default和kube-system命名空间,意味着pod按命名空间存储。下面的代码清单显示/registry/pods/default目录下的条目。
#代码11.4 default 命名空间中的pod的etcd条目
$ etcdctl ls /registry/pods/default
/registry/pods/default/kubia-159041347-xk0vc
/registry/pods/default/kubia-159041347-wt6ga
/registry/pods/default/kubia-159041347-hp2o5
每个条目对应一个单独的pod。这些不是目录,而是键值对。下面的代码清单展示了其中一条存储的内容。
#代码 11.5 一个etcd条目代表一个pod
$ etcdctl get /registry/pods/default/kubia-159041347-wt6ga
{"kind":"Pod","apiVersion":"v1","metadata":{"name":"kubia-159041347-wt6ga", "generateName":"kubia-159041347-","namespace":"default","selfLink":...
这就是一个JSON格式的pod定义。API服务器将资源的完整JSON形式存储到etcd中。由于etcd的层级键空间,可以想象成把资源以JSON文件格式存储到文件系统中。简单易懂,对吧?
警告:Kubernetes1.7之前的版本,密钥凭据的JSON内容也像上面一样存储(没有加密)。如果有人有权限直接访问etcd,那么可以获取所有的密钥凭据。从1.7版本开始,密钥凭据会被加密,这样存储起来更加安全。
确保存储对象的一致性和可验证性
Kubernetes要求所有控制平面组件只能通过API服务器操作存储模块。使用这种方式更新集群状态总是一致的,因为API服务器实现了乐观锁机制,如果有错误的话,也会更少。API服务器同时确保写入存储的数据总是有效的,只有授权的客户端才能更改数据。
确保etcd集群一致性
为保证高可用性,常常会运行多个etcd实例。多个etcd实例需要保持一致。这种分布式系统需要对系统的实际状态达成一致。etcd使用RAFT—致性算法来保证这一点,确保在任何时间点,每个节点的状态要么是大部分节点的当前状态,要么是之前确认过的状态。
连接到etcd集群不同节点的客户端,得到的要么是当前的实际状态,要么是之前的状态(在Kubernetes中,etcd的唯一客户端是API服务器,但有可能有多个实例)。
一致性算法要求集群大部分(法定数量)节点参与才能进行到下一个状态。结果就是,如果集群分裂为两个不互联的节点组,两个组的状态不可能不一致,因为要从之前状态变化到新状态,需要有过半的节点参与状态变更。如果一个组包含了大部分节点,那么另外一组只有少量节点成员。第一个组就可以更改集群状态,后者则不可以。当两个组重新恢复连接,第二个组的节点会更新为第一个组的节点的状态。
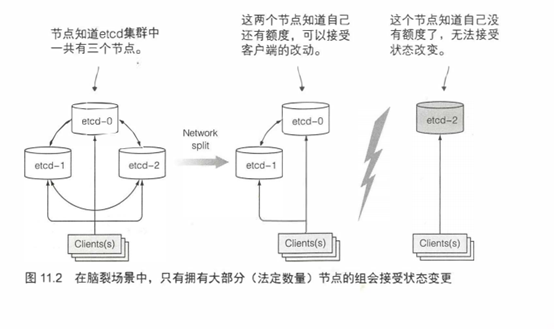
为什么eted实例数量应该是奇数
etcd通常部署奇数个实例。你一定想知道为什么。比较有一个实例和有两个实例的情况时。有两个实例时,要求另一个实例必须在线,这样才能符合超过半数的数量要求。如果有一个宕机,那么etcd集群就不能转换到新状态,因为没有超过半数。两个实例的情况比一个实例的情况更糟。对比单节点宕机,在有两个实例的情况下,整个集群挂掉的概率增加了 100%。
比较3节点和4节点也是同样的情况。3节点情况下,一个实例宕机,但超过半数(2个)的节点仍然运行着。对于4节点情况,需要3个节点才能超过半数(2个不够)。对于3节点和4节点,假设只有一个实例会宕机。当以4节点运行时,一个节点失败后,剩余节点宕机的可能性会更大(对比3节点集群,一个节点宕机还剩两个节点的情况)。
通常,对于大集群,etcd集群有5个或7个节点就足够了。可以允许2-3个节点宕机,这对于大多数场景来说足够了。
1.3 API服务器做了什么
KubernetesAPI服务器作为中心组件,其他组件或者客户端(如kubectl)都会去调用它。以RESTfulAPI的形式提供了可以查询、修改集群状态的CRUDCCreate、Read、Update、Delete)接口。它将状态存储到etcd中。
API服务器除了提供一种一致的方式将对象存储到etcd,也对这些对象做校验,这样客户端就无法存入非法的对象了(直接写入存储的话是有可能的)。除了校验,还会处理乐观锁,这样对于并发更新的情况,对对象做更改就不会被其他客户端覆盖。
API服务器的客户端之一就是使用的命令行工具kubectl。举个例子,当以JSON文件创建一个资源,kubectl通过一个HTTP POST请求将文件内容发布到API服务器。图11.3显示了接收到请求后API服务器内部发生了什么,后面会做更详细的介绍。
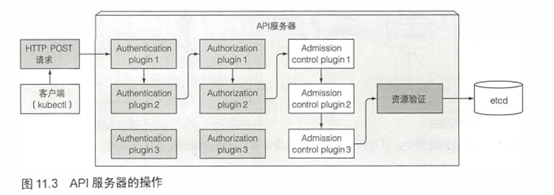
通过认证插件认证客户端
首先,API服务器需要认证发送请求的客户端。这是通过配置在API服务器上的一个或多个认证插件来实现的。API服务器会轮流调用这些插件,直到有一个能确认是谁发送了该请求。这是通过检查HTTP请求实现的。
根据认证方式,用户信息可以从客户端证书或者HTTP标头(例如Authorization)获取。插件抽取客户端的用户名、用户ID和归属组。这些数据在下一阶段,认证的时候会用到。
通过授权插件授权客户端
除了认证插件,API服务器还可以配置使用一个或多个授权插件。它们的作用是决定认证的用户是否可以对请求资源执行请求操作。例如,当创建pod时,API服务器会轮询所有的授权插件,来确认该用户是否可以在请求命名空间创建pod。一旦插件确认了用户可以执行该操作,API服务器会继续下一步操作。
通过准入控制插件验证AND/OR修改资源请求
如果请求尝试创建、修改或者删除一个资源,请求需要经过准入控制插件的验证。同理,服务器会配置多个准入控制插件。这些插件会因为各种原因修改资源,可能会初始化资源定义中漏配的字段为默认值甚至重写它们。插件甚至会去修改并不在请求中的相关资源,同时也会因为某些原因拒绝一个请求。资源需要经过所有准入控制插件的验证。
注意:如果请求只是尝试读取数据,则不会做准入控制的验证。
准入控制插件包括
- AlwaysPullImages--重写pod的imagePullPolicy为Always,强制每次部署pod时拉取镜像。
- ServiceAccount--未明确定义服务账户的使用默认账户。
- NamespaceLifecycle--防止在命名空间中创建正在被删除的pod,或在不存在的命名空间中创建pod。
- ResourceQuota--保证特定命名空间中的pod只能使用该命名空间分配数量的资源,如CPU和内存。
更多的准入控制插件可以在https://kubernetes.io/docs/admin/admission-controllers/中查看文档。
验证资源以及持久化存储
请求通过了所有的准入控制插件后,API服务器会验证存储到etcd的对象,然后返回一个响应给客户端。
1.4 API服务器如何通知客户端资源变更
除了前面讨论的,API服务器没有做其他额外的工作。例如,当创建一个ReplicaSet资源时,它不会去创建pod,同时它不会去管理服务的端点。那是控制器管理器的工作。
API服务器甚至也没有告诉这些控制器去做什么。它做的就是,启动这些控制器,以及其他一些组件来监控己部署资源的变更。控制平面可以请求订阅资源被创建、修改或删除的通知。这使得组件可以在集群元数据变化时候执行任何需要做的任务。
客户端通过创建到API服务器的HTTP连接来监听变更。通过此连接,客户端会接收到监听对象的一系列变更通知。每当更新对象,服务器把新版本对象发送至所有监听该对象的客户端。图11.4显示客户端如何监听pod的变更,以及如何将pod的变更存储到etcd,然后通知所有监听该pod的客户端。
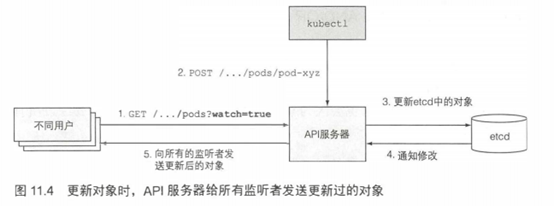
kubectl工具作为API服务器的客户端之一,也支持监听资源。例如,当部署pod时,不需要重复执行kubectl get pods来定期查询pod列表。可以使用--watch标志,每当创建、修改、删除pod时就会通知你,如下面的代码清单所示。
#代码11.6 监听创建删除pod事件
$ kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
kubia-159041347-14j3i 0/1 Pending 0 0s
kubia-159041347-14j3i 0/1 Pending 0 0s
kubia-159041347-14j3i 0/1 ContainerCreating 0 1s
kubia-159041347-14j3i 0/1 Running 0 3s
kubia-159041347-14j3i 1/1 Running 0 5s
kubia-159041347-14j3i 1/1 Terminating 0 9s
kubia-159041347-14j3i 0/1 Terminating 0 17s
kubia-159041347-14j3i 0/1 Terminating 0 17s
kubia-159041347-14j3i 0/1 Terminating 0 17s
甚至可以让kubectl打印出整个监听事件的YAML文件,如下:
$ kubectl get pods -o yaml - -watch
监听机制同样也可以用于调度器。调度器是下一个要着重讲解的控制平面组件。
1.5 了解调度器
前面己经学习过,通常不会去指定pod应该运行在哪个集群节点上,这项工作交给调度器。宏观来看,调度器的操作比较简单。就是利用API服务器的监听机制等待新创建的pod,然后给每个新的、没有节点集的pod分配节点。
调度器不会命令选中的节点(或者节点上运行的Kubelet)去运行pod。调度器做的就是通过API服务器更新pod的定义。然后API服务器再去通知Kubelet(同样,通过之前描述的监听机制)该pod己经被调度过。当目标节点上的Kubelet发现该pod被调度到本节点,它就会创建并且运行pod的容器。
尽管宏观上调度的过程看起来比较简单,但实际上为pod选择最佳节点的任务并不简单。当然,最简单的调度方式是不关心节点上己经运行的pod,随机选择一个节点。另一方面,调度器可以利用高级技术,例如机器学习,来预测接下来几分钟或几小时哪种类型的pod将会被调度,然后以最大的硬件利用率、无须重新调度已运行pod的方式来调度。Kubernetes的默认调度器实现方式处于最简单和最复杂程度之间。
默认的调度算法
选择节点操作可以分解为两部分,如图11.5所示:
- 过滤所有节点,找出能分配给pod的可用节点列表。
- 对可用节点按优先级排序,找出最优节点。如果多个节点都有最高的优先级分数,那么则循环分配,确保平均分配给pod。

查找可用节点
为了决定哪些节点对pod可用,调度器会给每个节点下发一组配置好的预测函数。这些函数检查
- 节点是否能满足pod对硬件资源的请求。
- 节点是否耗尽资源(是否报告过内存/硬盘压力参数)?
- pod是否要求被调度到指定节点(通过名字),是否是当前节点?
- 节点是否有和pod规格定义里的节点选择器一致的标签(如果定义了的话)?
- 如果pod要求绑定指定的主机端口那么这个节点上的这个端口是否己经被占用?
- 如果pod要求有特定类型的卷,该节点是否能为此pod加载此卷,或者说该节点上是否己经有pod在使用该卷了?
- pod是否能够容忍节点的污点。
- pod是否定义了节点、pod的亲缘性以及非亲缘性规则?如果是,那么调度节点给该pod是否会违反规则?
所有这些测试都必须通过,节点才有资格调度给pod。在对每个节点做过这些检查后,调度器得到节点集的一个子集。任何这些节点都可以运行pod,因为它们都有足够的可用资源,也确认过满足pod定义的所有要求。
为pod选择最佳节点
尽管所有这些节点都能运行pod,其中的一些可能还是优于另外一些。假设有一个2节点集群,两个节点都可用,但是其中一个运行10个pod,而另一个,不知道什么原因,当前没有运行任何pod。本例中,明显调度器应该选第二个节点。
或者说,如果两个节点是由云平台提供的服务,那么更好的方式是,pod调度给第一个节点,将第二个节点释放回云服务商以节省资金。
pod高级调度
考虑另外一个例子。假设一个pod有多个副本。理想情况下,你会期望副本能够分散在尽可能多的节点上,而不是全部分配到单独一个节点上。该节点的宕机会导致pod支持的服务不可用。但是如果pod分散在不同的节点上,单个节点宕机,并不会对服务造成什么影响。
默认情况下,归属同一服务和ReplicaSet的pod会分散在多个节点上。但不保证每次都是这样。不过可以通过定义pod的亲缘性、非亲缘规则强制pod分散在集群内或者集中在一起,相关内容会在pod的高级调度介绍。
仅通过这两个简单的例子就说明了调度有多复杂,因为它依赖于大量的因子。因此,调度器既可以配置成满足特定的需要或者基础设施特性,也可以整体替换为一个定制的实现。可以抛开调度器运行一个Kubernetes不过那样的话,就需要手动实现调度了。
使用多个调度器
可以在集群中运行多个调度器而非单个。然后,对每一个pod,可以通过在pod特性中设置schedulerName属性指定调度器来调度特定的pod。
未设置该属性的pod由默认调度器调度,因此其schedulerName被设置为default-scheduler。其他设置了该属性的pod会被默认调度器忽略掉,它们要么是手动调用,要么被监听这类pod的调度器调用。
可以实现自己的调度器,部署到集群,或者可以部署有不同配置项的额外 Kubernetes调度器实例。
1.6 介绍控制器管理器中运行的控制器
如前面提到的,API服务器只做了存储资源到etcd和通知客户端有变更的工作。 调度器则只是给pod分配节点,所以需要有活跃的组件确保系统真实状态朝API服务器定义的期望的状态收敛。这个工作由控制器管理器里的控制器来实现。
单个控制器、管理器进程当前组合了多个执行不同非冲突任务的控制器。这些控制器最终会被分解到不同的进程,如果需要的话,能够用自定义实现替换它们每一个。控制器包括
- Replication管理器(ReplicationController资源的管理器)
- ReplicaSet、DaemonSet以及Job控制器
- Deployment控制器
- StatefolSet控制器
- Node控制器
- Service控制器
- Endpoints控制器
- Namespace控制器
- PersistentVolume控制器
- 其他
每个控制器做什么通过名字显而易见。通过上述列表,几乎可以知道创建每个资源对应的控制器是什么。资源描述了集群中应该运行什么,而控制器就是活跃的Kubernetes组件,去做具体工作部署资源。
了解控制器做了什么以及如何做的
控制器做了许多不同的事情,但是它们都通过API服务器监听资源(部署、服务等)变更,并且不论是创建新对象还是更新、删除己有对象,都对变更执行相应操作。大多数情况下,这些操作涵盖了新建其他资源或者更新监听的资源本身(例如,更新对象的status)。
总的来说,控制器执行一个“调和”循环,将实际状态调整为期望状态(在资源spec部分定义),然后将新的实际状态写入资源的status部分。控制器利用监听机制来订阅变更,但是由于使用监听机制并不保证控制器不会漏掉时间,所以仍然需要定期执行重列举操作来确保不会丢掉什么。
控制器之间不会直接通信,它们甚至不知道其他控制器的存在。每个控制器都连接到API服务器,通过1.3节《API服务器做了什么》描述的监听机制,请求订阅该控制器负责的一系列资源的变更。
概括地了解了每个控制器做了什么,但是如果想深入了解它们做了什么,建议直接看源代码。边栏阐述了如何上手看源代码。
浏览控制器源代码的几个要点
控制器的源代码可以从 https://github.com/kubernetes/kubernetes/blob/master/pkg/controller获取。
每个控制器一般有一个构造器,内部会创建一个Informer,其实是个监听器,每次API对象有更新就会被调用。通常,Informer会监听特定类型的资源变更事件。查看构造器可以了解控制器监听的是哪个资源。
接下来,去看worker()方法。其中定义了每次控制器需要工作的时候都会调用worker()方法。实际的函数通常保存在一个叫syncHandler或类似的字段里。该字段也在构造器里初始化,可以在那里找到被调用函数名。该函数是所有魔法发生的地方。
Replication管理器
启动ReplicationController资源的控制器叫作Replication管理器。应该都了解ReplicationController是如何工作的,其实不是ReplicationController做了实际的工作,而是Replication管理器。
ReplicationController的操作可以理解为一个无限循环,每次循环,控制器都会查找符合其pod选择器定义的pod的数量,并且将该数值和期望的复制集(replica)数量做比较。
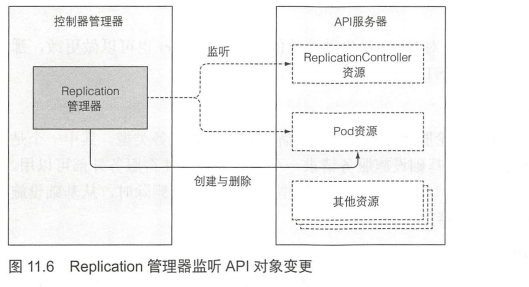
API服务器可以通过监听机制通知客户端,那么明显地,控制器不会每次循环去轮询pod,而是通过监听机制订阅可能影响期望的复制集(replica)数量或者符合条件pod数量的变更事件(见图11.6)。任何该类型的变化,将触发控制器重新检查期望的以及实际的复制集数量,然后做出相应操作。
当运行的pod实例太少时,ReplicationController会运行额外的实例,但它自己实际上不会去运行pod。它会创建新的pod清单,发布到API服务器,让调度器以及Kubelet来做调度工作并运行pod。
Replication管理器通过API服务器操纵pod API对象来完成其工作。所有控制器就是这样运作的。
RerlicaSet、DaemonSet以及Job控制器
ReplicaSet控制器基本上做了和前面描述的Replication管理器一样的事情,所以这里不再赘述。DaemonSet以及Job控制器比较相似,从它们各自资源集中定义的pod模板创建pod资源。与Replication管理器类似,这些控制器不会运行pod,而是将pod定义到发布API服务器,让Kubelet创建容器并运行。
Deployment控制器
Deployment控制器负责使deployment的实际状态与对应DeploymentAPI对象的期望状态同步。
每次Deployment对象修改后(如果修改会影响到部署的pod),Deployment控制器都会滚动升级到新的版本。通过创建一个ReplicaSet,然后按照Deployment中定义的策略同时伸缩新、旧RelicaSet,直到旧pod被新的代替。并不会直接创建任何pod。
StatefulSet控制器
StatefulSet控制器,类似于ReplicaSet控制器以及其他相关控制器,根据StatefulSet资源定义创建、管理、删除pod。其他的控制器只管理pod,而StatefulSet控制器会初始化并管理每个pod实例的持久卷声明字段。
Node控制器
Node控制器管理Node资源,描述了集群工作节点。其中,Node控制器使节点对象列表与集群中实际运行的机器列表保持同步。同时监控每个节点的健康状态,删除不可达节点的pod。
Node控制器不是唯一对Node对象做更改的组件。Kubelet也可以做更改,那么显然可以由用户通过REST API调用做更改。
Service控制器
在服务中,有很多存在不同服务类型。其中一个是LoadBalancer服务,从基础设施服务请求一个负载均衡器使得服务外部可以用。Service控制器就是用来在LoadBalancer类型服务被创建或删除时,从基础设施服务请求、释放负载均衡器的。
Endpoint控制器
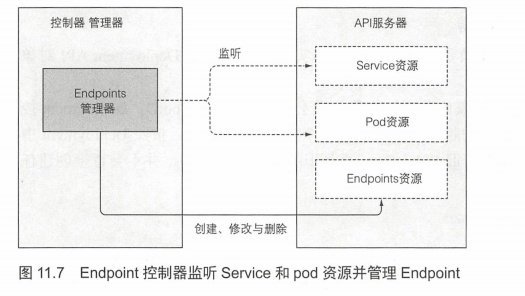
Service不会直接连接到pod,而是包含一个端点列表(IP和端口), 列表要么是手动,要么是根据Service定义的pod选择器自动创建、更新。Endpoint控制器作为活动的组件,定期根据匹配标签选择器的pod的IP、端口更新端点列表。
如图11.7所示,控制器同时监听了Service和pod。当Service被添加、修改,或者pod被添加、修改或删除时,控制器会选中匹配Service的pod选择器的pod,将其IP和端口添加到Endpoint资源中。请记住,Endpoint对象是个独立的对象,所以当需要的时候控制器会创建它。同样地,当删除Service时,Endpoint对象也会被删除。
Namespace控制器
大部分资源归属于某个特定命名空间。当删除一个Namespace资源时,该命名空间里的所有资源都会被删除。这就是Namespace控制器做的事情。当收到删除Namespace对象的通知时,控制器通过API服务器删除所有归属该命名空间的资源。
PersistentVolume控制器
持久卷以及持久卷声明:一旦用户创建了一个持久卷声明,Kubernetes必须找到一个合适的持久卷同时将其和声明绑定。这些由持久卷控制器实现。
对于一个持久卷声明,控制器为声明查找最佳匹配项,通过选择匹配声明中的访问模式,并且声明的容量大于需求的容量的最小持久卷。实现方式是保存一份有序的持久卷列表,对于每种访问模式按照容量升序排列,返回列表的第一个卷。
当用户删除持久卷声明时,会解绑卷,然后根据卷的回收策略进行回收(原样保留、删除或清空)。
唤醒控制器
现在,总体来说应该了解每个控制器做了什么,以及是如何工作的有个比较好的感觉。再一次强调,所有这些控制器是通过API服务器来操作API对象的。它们不会直接和Kubelet通信或者发送任何类型的指令。实际上,它们不知道Kubelet的存在。控制器更新API服务器的一个资源后,Kubelet和Kubernetes Service Proxy(也不知道控制器的存在)会做它们的工作,例如启动pod容器、加载网络存储,或者就服务而言,创建跨pod的负载均衡。
控制平面处理了整个系统的一部分操作,为了完全理解Kubernetes集群的内部运作方式,还需要理解Kubelet和Kubernetes Service Proxy做了什么。下面将学习这些内容。
1.7 Kubelet做了什么
所有Kubernetes控制平面的控制器都运行在主节点上,而Kubelet以及Service Proxy都运行在工作节点(实际pod容器运行的地方)上。Kubelet究竟做了什么事情?
了解Kubelet的工作内容
简单地说,Kubelet就是负责所有运行在工作节点上内容的组件。它第一个任务就是在API服务器中创建一个Node资源来注册该节点。然后需要持续监控API服务器是否把该节点分配给pod,然后启动pod容器。具体实现方式是告知配置好的容器运行时(Docker、CoreOS的Rkt,或者其他一些东西)来从特定容器镜像运行容器。Kubelet随后持续监控运行的容器,向API服务器报告它们的状态、事件和资源消耗。
Kubelet也是运行容器存活探针的组件,当探针报错时它会重启容器。最后一点, 当pod从API服务器删除时,Kubelet终止容器,并通知服务器pod己经被终止了。
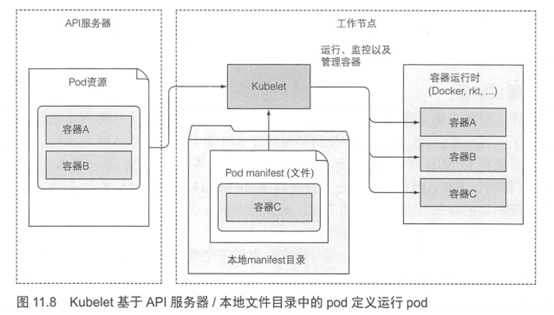
抛开API服务器运行静态pod
尽管Kubelet—般会和API服务器通信并从中获取pod清单,它也可以基于本地指定目录下的pod清单来运行pod,如图11.8所示。如本章开头所示,该特性用于将容器化版本的控制平面组件以pod形式运行。
不但可以按照原有的方式运行Kubernetes系统组件,也可以将pod清单放到Kubelet的清单目录中,让Kubelet运行和管理它们。
也可以同样的方式运行自定义的系统容器,不过推荐用DaemonSet来做这项工作。
1.8 Kubernetes Service Proxy 的作用
除了Kubelet,每个工作节点还会运行kube-proxy,用于确保客户端可以通过Kubernetes API连接到定义的服务。kube-proxy确保对服务IP和端口的连接最终能到达支持服务(或者其他,非pod服务终端)的某个pod处。如果有多个pod支撑一个服务,那么代理会发挥对pod的负载均衡作用。
为什么被叫作代理
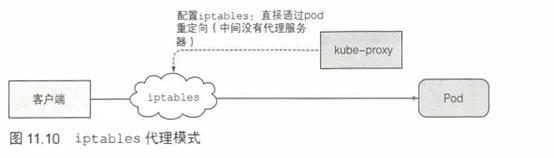
kubeproxy最初实现为userspace代理。利用实际的服务器集成接收连接,同时代理给pod。为了拦截发往服务IP的连接,代理配置了iptables规则 (iptables是一个管理Linux内核数据包过滤功能的工具),重定向连接到代理服务器。userspace代理模式大致如图11.9所示。

kube-proxy之所以叫这个名字是因为它确实就是一个代理器,不过当前性能更好的实现方式仅仅通过iptables规则重定向数据包到一个随机选择的后端pod,而不会传递到一个实际的代理服务器。这个模式称为iptables代理模式,如图11.10所示。
但是iptables受限于集群的规模,规模越大,iptables的速度越慢,所以在后期出现了一个IPVS模式,性能有着更大的提升。
Userspace和iptables的主要区别是:数据包是否会传递给kube-proxy, 是否必须在用户空间处理,或者数据包只会在内核处理(内核空间)。这对性能有巨大的影响。加上后期出现的IPVS,有了多样化的调度算法和专门针对负载均衡的IPVS组件。各方面有了更大的提升
1.9 介绍 Kubernetes 插件
讨论了Kubernetes集群正常工作所需要的一些核心组件。但在开头的几章中,也罗列了一些插件,它们不是必需的;这些插件用于启用Kubernetes服务的DNS查询,通过单个外部IP地址暴露多个HTTP服务、Kubernetes web仪表板等特性。
如何部署插件
通过提交YAML清单文件到API服务器,各插件可以去kubernetes查找,这里不做过多讲解。
介绍DNS服务器如何工作
集群中的所有pod默认配置使用集群内部DNS服务器。这使得pod能够轻松地通过名称查询到服务,甚至是无头服务pod的IP地址。
DNS服务pod通过kube-dns服务对外暴露,使得该pod能够像其他pod—样在集群中移动。服务的IP地址在集群每个容器的/etc/reslv.conf文件的nameserver中定义。kube-dns pod利用API服务器的监控机制来订阅Service和Endpoint的变动,以及DNS记录的变更,使得其客户端(相对地)总是能够获取到最新的DNS信息。客观地说,在Service和Endpoint资源发生变化到DNS pod收到订阅通知时间点之间,DNS记录可能会无效。
Ingress控制器如何工作
和DNS插件相比,Ingress控制器的实现有点不同,但它们大部分的工作方式相同。Ingress控制器运行一个反向代理服务器(例如,类似Nginx),根据集群中定义的Ingress、Service以及Endpoint资源来配置该控制器。所以需要订阅这些资源(通过监听机制),然后每次其中一个发生变化则更新代理服务器的配置。
尽管Ingress资源的定义指向一个Service,Ingress控制器会直接将流量转到服务的pod而不经过服务IP。当外部客户端通过Ingress控制器连接时,会对客户端IP进行保存,这使得在某些用例中,控制器比Service更受欢迎。
使用其他插件
了解了DNS服务器和Ingress控制器插件同控制器管理器中运行的控制器比较相似,除了它们不会仅通过API服务器监听、修改资源,也会接收客户端的连接。
其他插件也类似。它们都需要监听集群状态,当有变更时执行相应动作。会在剩余的章节中介绍一些其他的插件。
1.10 总结
了解了整个Kubernetes系统由相对小的、完善功能划分的松耦合组件构成。API服务器、调度器、控制器管理器中运行的控制器、Kubelet以及kube-proxy一起合作来保证实际的状态和定义的期望状态一致。
例如,向API服务器提交一个pod配置会触发Kubernetes组件间的协作,这会导致pod的容器运行。这里的细节将会在接下来的部分详细说明。
2.控制器之前如何协作
现在了解了Kubernetes集群包含哪些组件。为了强化对Kubernetes工作方式的理解,看一下当一个pod资源被创建时会发生什么。因为一般不会直接创建pod,所以创建Deployment资源作为替代,然后观察启动pod的容器会发生什么。
2.1 了解涉及哪些组件
在启动整个流程之前,控制器、调度器、Kubelet就己经通过API服务器监听它们各自资源类型的变化了。如图11.11所示。图中描画的每个组件在即将触发的流程中都起到一定的作用。图表中不包含etcd,因为它被隐藏在API服务器之后,可以想象成API服务器就是对象存储的地方。
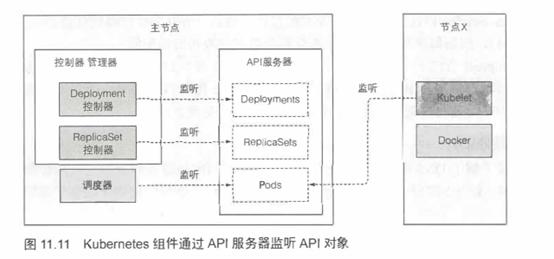
2.2 事件链
准备包含Deployment清单的YAML文件,通过kubetctl提交到Kubernetes。kubectl通过HTTP POST请求发送清单到Kubernetes API服务器。API服务器检查Deployment定义,存储到etcd,返回响应给kubectl。现在事件链开始被揭示出来,如图11.12所示。
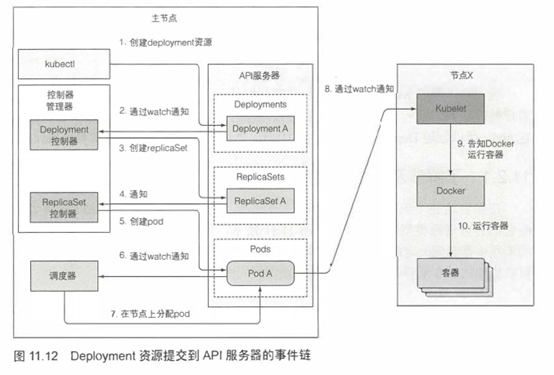
Deployment控制器生成ReplicaSet
当新创建Deployment资源时,所有通过API服务器监听机制监听Deployment列表的客户端马上会收到通知。其中有个客户端叫Deployment控制器,之前讨论过,该控制器是一个负责处理部署事务的活动组件。
一个Deployment由一个或多个Replicaset支持, ReplicaSet后面会创建实际的pod。当Deployment控制器检查到有一个新的Deployment对象时,会按照Deploymnet当前定义创建ReplicaSet。这包括通过KubernetesAPI创建一个新的ReplicaSet资源。Deployment控制器完全不会去处理单个pod。
ReplicaSet控制器创建pod资源
新创建的ReplicaSet由ReplicaSet控制器(通过API服务器创建、修改、删除 ReplicaSet资源)接收。控制器会考虑replica数量、ReplicaSet中定义的pod选择器,然后检查是否有足够的满足选择器的pod。
然后控制器会基于ReplicatSet的pod模板创建pod资源(当Deployment控制器创建ReplicaSet时,会从Deployment复制pod模板)。
调度器分配节点给新创建的pod
新创建的pod目前保存在etcd中,但是它们每个都缺少一个重要的东西——它们还没有任何关联节点。它们的nodeName属性还未被设置。调度器会监控像这样的pod,发现一个,就会为pod选择最佳节点,并将节点分配给podLpod的定义现在就会包含它应该运行在哪个节点。
目前,所有的一切都发生在Kubernetes控制平面中。参与这个全过程的控制器没有做其他具体的事情,除了通过API服务器更新资源。
Kubelet运行pod容器
目前,工作节点还没做任何事情,pod容器还没有被启动起来,pod容器的图片还没有下载。
随着pod目前分配给了特定的节点,节点上的Kubelet终于可以工作了。Kubelet通过API服务器监听pod变更,发现有新的pod分配到本节点后,会去检查pod定义,然后命令Docker或者任何使用的容器运行时来启动pod容器,容器运行时就会去运行容器。
2.3 观察集群事件
控制平面组件和Kubelet执行动作时,都会发送事件给API服务器。发送事件是通过创建事件资源来实现的,事件资源和其他的Kubernetes资源类似。每次使用kubectl describe来检查资源的时候,就能看到资源相关的事件,也可以直接用kubectl get events 获取事件。
可能是个人的感受,使用kubectl get检查事件比较痛苦,因为不是以合适的时间顺序显示的。当一个事件发生了多次,该事件只会被显示一次,显示首次出现时间、最后一次出现时间以及发生次数。幸运的是,利用--watch选项监听事件肉眼看起来更简单,对于观察集群发生了什么也更有用。
下面的代码清单展示了前述过程中发出的事件(由于页面空间有限,有些列被删掉了,输出也做了改动)。
#代码11.9 观察控制器发出的事件
$ kuberctl get events --watch
NAME KIND REASON SOURCE
... kubia Deployment ScalingReplicaSet deployment-controller scaled up replica set kubia-193 to 3
... kubia-193 ReplicaSet SuccessfulCreate replicaset-contorller Created pod:kubia-193-w7112
... kubia-193-tpg6j Pod Scheduled default-scheduler Successfully assigned kubia-193-tpg6j to node1
... kubia-193 ReplicaSet SuccessfulCreate replicaset-contorller Created :kubia-193-39590
SOURCE列显示执行动作的控制器,NAME 和KIND列显示控制器作用的资源。REASON列以及MESSAGE列(显示在每一项的第二行)提供控制器所做的更详细的信息。
3.了解运行中的pod是什么
当pod运行时,仔细看一下,运行的pod到底是什么。如果pod包含单个容器,那么你认为Kubelet会只运行单个容器,还是更多?
想象运行单个容器的pod,假设创建了一个Nginx pod:
$ kubectl run nginx --image=nginx
deployment "nginx" created
此时,可以ssh到运行pod的工作节点,检查一系列运行的Docker容器。使用minikube ssh来ssh到单个节点。如果用GKE,可以通过gcloud compute ssh <node name>来ssh到一个节点。
一旦进入节点内部,可以通过docker ps命令列出所有运行的容器,如下面的代码清单所示。
#代码11.10 列出运行的Docker容器 :这里已经把不想关的信息删除了
docker@minikubeVM:-$ docker ps
CONTAINER ID IMAGE COMMAND CREATED
c917a6f3c3f7 nginx “nginx -g 'daemon off'” 4 seconds ago
98b8bf797174 gcr.io/.../pause:3.0 "/pause" 7 seconds ago
看到了Nginx容器,以及一个附加容器。从COMMAND列判断,附加容器没有做任何事情(容器命令是"pause")。仔细观察,会发现容器是在Nginx容器前几秒创建的。它的作用是什么?
被暂停的容器将一个pod所有的容器收纳到一起。还记得一个pod的所有容器是如何共享同一个网络和Linux命名空间的吗?暂停的容器是一个基础容器,它的唯一目的就是保存所有的命名空间。所有pod的其他用户定义容器使用pod的该基础容器的命名空间。
实际的应用容器可能会挂掉并重启。当容器重启,容器需要处于与之前相同的Linux命名空间中。基础容器使这成为可能,因为它的生命周期和pod绑定,基础容器pod被调度直到被删除一直会运行。如果基础pod在这期间被关闭,Kubelet会重新创建它,以及pod的所有容器。
4.跨pod网络
现在,你知道每个pod有自己唯一的IP地址,可以通过一个扁平的、非NAT网络和其他pod通信。Kubernetes是如何做到这一点的?简单来说,Kubernetes不负责这块。网络是由系统管理员或者ContainerNetworklnterface(CNI)插件建立的,而非Kubernetes本身。
4.1 网络应该是什么样的
Kubernetes并不会要求使用特定的网络技术,但是授权pod(或者更准确地说,其容器)不论是否运行在同一个工作节点上,可以互相通信。pod用于通信的网络必须是:pod自己认为的IP地址一定和所有其他节点认为该pod拥有的IP地址一致。
当podA连接(发送网络包)到podB时,podB获取到的源IP地址必须和podA自己认为的IP地址一致。其间应该没有网络地址转换(NAT)操作---podA发送到podB的包必须保持源和目的地址不变。
这很重要,保证运行在pod内部的应用网络的简洁性,就像运行在同一个网关机上一样。pod没有NAT使得运行在其中的应用可以自己注册在其他pod中。
例如,有客户端pod X和pod Y,为所有通过它们注册的pod提供通知服务。pod X连接到pod Y并且告诉pod Y, “你好,我是pod X,IP地址为1.2.3.4请把更新发送到这个IP地址”。提供服务的pod可以通过收到的IP地址连接第一个pod。
pod到节点及节点到pod通信也应用了无NAT通信。但是当pod和internet上的服务通信时,pod发送包的源IP不需要改变,因为pod的IP是私有的。向外发送包的源IP地址会被改成主机工作节点的IP地址。
构建一个像样的Kubernetes集群包含按照这些要求建立网络。有不同的方法和技术来建立,在给定场景中它们都有其优点和缺点。因此,这里不会深入探究特定的技术,会阐述跨pod网络通用的工作原理。
4.2 深入了解网络工作原理
<了解运行中pod是什么>介绍了创建pod的IP地址以及网络命名空间,由基础设施容 器(暂停容器)来保存这些信息,然后pod容器就可以使用网络命名空间了。pod网络接口就是生成在基础设施容器的一些东西。现在看一下接口是如何被创建的,以及如何连接到其他pod的接口,如图11.15所示。
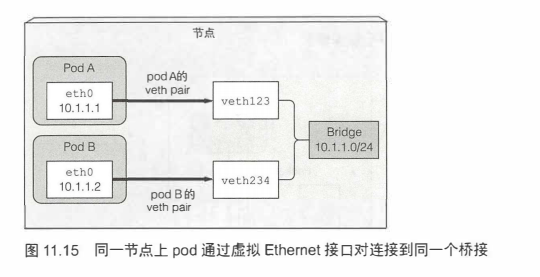
同节点pod通信
基础设施容器启动之前,会为容器创建一个虚拟Ethernet接口对(一个veth pair),其中一个对的接口保留在主机的命名空间中(在节点上运行ifconfg命令时可以看到vethXXX的条目),而其他的对被移入容器网络命名空间,并重命名为ethO。两个虚拟接口就像管道的两端(或者说像Ethernet电缆连接的两个网络设备)一从一端进入,另一端出来,等等。
主机网络命名空间的接口会绑定到容器运行时配置使用的网络桥接上。从网桥的地址段中取IP地址赋值给容器内的ethO接口。应用的任何运行在容器内部的程 序都会发送数据到ethO网络接口(在容器命名空间中的那一个),数据从主机命名 空间的另一个veth接口出来,然后发送给网桥。这意味着任何连接到网桥的网络接口都可以接收该数据。
如果podA发送网络包到podB,报文首先会经过podA的veth对到网桥然后经过podB的veth对。所有节点上的容器都会连接到同一个网桥,意味着它们都能够互相通信。但是要让运行在不同节点上的容器之间能够通信,这些节点的网桥需要以某种方式连接起来。
不同节点上的pod通信
有多种连接不同节点上的网桥的方式。可以通过overlay或underlay网络,或者常规的三层路由,会在后面看到。
跨整个集群的pod的IP地址必须是唯一的,所以跨节点的网桥必须使用非重叠地址段,防止不同节点上的pod拿到同一个IP。如图11.16所示的例子,节点A上的网桥使用10.1.1.0/24 IP段,节点B上的网桥使用10.1.2.0/24 IP段,确保没有IP地址冲突的可能性。
图11.16显示了通过三层网络支持跨两个节点pod通信,节点的物理网络接口也需要连接到网桥。节点A的路由表需要被配置成图中所示,这样所有目的地为10.1.2.0/24的报文会被路由到节B,同时节点B的路由表需要被配置成图中所示,这样发送到10.1.1.0/24的包会被发送到节点A。
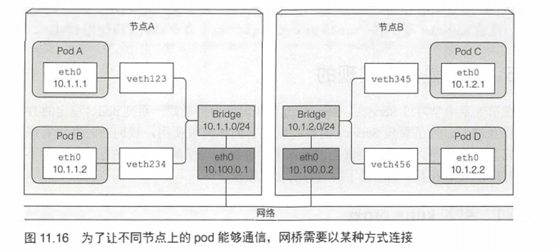
按照该配置,当报文从一个节点上容器发送到其他节点上的容器,报文先通过veth pair,通过网桥到节点物理适配器,然后通过网线传到其他节点的物理适配器,再通过其他节点的网桥,最终经过veth pair到达目标容器。
仅当节点连接到相同网关、之间没有任何路由时上述方案有效。否则,路由器会扔包因为它们所涉及的podIP是私有的。当然,也可以配置路由使其在节点间能够路由报文,但是随着节点数量增加,配置会变得更困难,也更容易出错。因此,使用SDN(软件定义网络)技术可以简化问题,SDN可以让节点忽略底层网络拓扑,无论多复杂,结果就像连接到同一个网关上。从pod发出的报文会被封装,通过网络发送给运行其他pod的网络,然后被解封装、以原始格式传递给pod。
4.3 容器网络接口
为了让连接容器到网络更加方便,启动一个项目容器网络接口(CNI)。CNI允许Kubernetes可配置使用任何CNI插件。这些插件包含
- Calico
- Flannel
- Romana
- Weave Net
- 其他
这里不会深入探究这些插件的细节,如果想要了解更多,可以参考https://kubernetes.io/docs/concepts/cluster-administration/addons/.
安装一个网络插件并不难,只需要部署一个包含DaemonSet以及其他支持资源的YAML。每个插件项目首页都会提供这样一个YAML文件。如你所想,DaemonSet用于往所有集群节点部署一个网络代理,然后会绑定CNI接口到节点。但是,注意Kubetlet需要用--network-plugin=cni命令启动才能使用CNI。
5.服务是如何实现的
其它篇章讲解过Service,Service允许长时间对外暴露一系列pod、稳定的IP地址以及端口。为了聚焦Service的目的以及它们如何被使用,当时并没有深入探究其工作原理。但是,要真正理解服务,并更好地了解当事情的行为与预期不一致时应该从哪着手,就需要了解服务的实现原理。
和Service相关的任何事情都由每个节点上运行的kube-proxy进程处理。开始的时候,kube-proxy确实是一个proxy,等待连接,对每个进来的连接,连接到一个pod。这称为userspace(用户空间)代理模式。后来,性能更好的iptables代理模式取代了它。iptables代理模式目前是默认的模式,如果有需要也仍然可以配置Kubernetes使用旧模式。也可以设置成为IPVS模式。
具体的网络模式章节可以参考以下文章:Kubernetes的网络代理模式
6.运行高可用集群
6.1 让应用变成高可用
当在Kubernetes运行应用时,有不同的控制器来保证你的应用平滑运行,即使节点宕机也能够保持特定的规模。为了保证你的应用的高可用性,只需通过Deployment资源运行应用,配置合适数量的复制集,其他的交给Kubernetes处理。
运行多实例来减少宕机可能性
需要你的应用可以水平扩展,不过即使不可以,仍然可以使用Deployment,将复制集数量设为1。如果复制集不可用,会快速替换为一个新的,尽管不会同时发生。让所有相关控制器都发现有节点宕机、创建新的pod复制集、启动pod容器可能需 要一些时间。不可避免中间会有小段宕机时间。
对不能水平扩展的应用使用领导选举机制
为了避免宕机,需要在运行一个活跃的应用的同时再运行一个附加的非活跃复制集,通过一个快速起效租约或者领导选举机制来确保只有一个是有效的。以防不熟悉领导者选举算法,提一下,它是一种分布式环境中多应用实例对谁是领导者达成一致的方式。例如,领导者要么是唯一执行任务的那个,其他所有节点都在等待该领导者宕机,然后自己变成领导者;或者是都是活跃的,但是领导者是唯一能够执行写操作的,而其他的只能读数据。这样能保证两个实例不会做同一个任务,否则会因为竞争条件导致不可预测的系统行为。
该机制自身不需要集成到应用中,可以使用一个sidecar容器来执行所有的领导选举操作,通知主容器什么时候它应该活跃起来。一个Kubernetes中领导选举的例子: https://github.com/kubemetes/contrib/tree/master/election。
保证应用高可用相对简单,因为Kubernetes几乎替你完成所有事情。但是假如 Kubernetes自身宕机了呢?如果是运行Kubernetes控制平面组件的服务器挂了呢? 这些组件是如何做到高可用的呢?
6.2 让Kubernetes控制平面变得高可用
为了使得Kubernetes高可用,需要运行多个主节点,即运行下述组件的多个实例:
- etcd分布式数据存储,所有API对象存于此处
- API服务器
- 控制器管理器,所有控制器运行的进程
- 调度器
不需要深入了解如何安装和运行这些组件的细节。看一下如何让这些组件高可用。
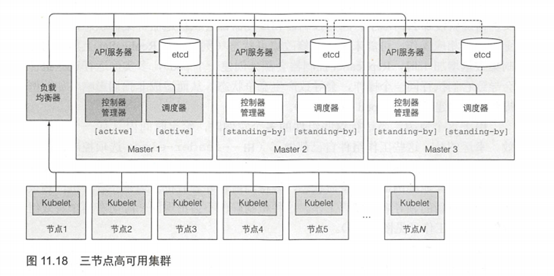
因为etcd被设计为一个分布式系统,其核心特性之一就是可以运行多个etcd实例,所以它做到高可用并非难事。要做的就是将其运行在合适数量的机器上(3个、5个或者7个,如章节刚开始所述),使得它们能够互相感知。实现方式通过在每个实例的配置中包含其他实例的列表。例如,当启动一个实例时,指定其他etcd实例可达的IP和端口。
etcd会跨实例复制数据,所以三节点中其中一个宕机并不会影响处理读写操作。为了增加错误容忍度不仅仅支持一台机器宕机,需要运行5个或者7个etcd节点,这样集群可以分别容忍2个或者3个节点宕机。拥有超过7个实例基本上没有必要,并且会影响性能。
运行多实例API服务器
保证API服务器高可用甚至更简单,因为API服务器是(几乎全部)无状态的 (所有数据存储在etcd中,API服务器不做缓存),需要多少就能运行多少API服务器,它们直接不需要感知对方存在。通常,一个API服务器会和每个etcd实例搭配。这样做,etcd实例之前就不需要任何负载均衡器,因为每个API服务器只和本地etcd实例通信。
而API服务器确实需要一个负载均衡器,这样客户端(kubectl,也有可能是控制器管理器、调度器以及所有Kubelet)总是只连接到健康的API服务器实例。
确保控制器和调度器的高可用性
对比API服务器可以同时运行多个复制集,运行控制器管理器或者调度器的多实例情况就没那么简单了。因为控制器和调度器都会积极地监听集群状态,发生变更时做出相应操作,可能未来还会修改集群状态(例如,当ReplicaSet上期望的复制集数量增加1时,ReplicaSet控制器会额外创建一个pod),多实例运行这些组件会导致它们执行同一个操作,会导致产生竞争状态,从而造成非预期影响(如前例提到的,创建了两个新pod而非一个)。
由于这个原因,当运行这些组件的多个实例时,给定时间内只有一个实例有效。幸运的是,这些工作组件自己都做了(由--leader-elect选项控制,默认为true)。只有当成为选定的领导者时,组件才可能有效。只有领导者才会执行实际的工作,而其他实例都处于待命状态,等待当前领导者宕机。当领导者宕机,剩余实例会选举新的领导者,接管工作。这种机制确保不会出现同一时间有两个有效组件做同样的工作。
控制器管理器和调度器可以和API服务器、etcd搭配运行,或者也可以运行在不同的机器上。当搭配运行时,可以直接跟本地API服务器通信;否则就是通过负载均衡器连接到API服务器。
控制平面组件使用的领导选举机制
选举领导时这些组件不需要互相通信。领导选举机制的实现方式是在API服务器中创建一个资源,而且甚至不是什么特殊种类的资源---Endpoint资源就可以拿来用于达到目的(滥用更贴切一点)。
使用Endpoint对象来完成该工作没有什么特别之处。使用Endpoint对象的原因是只要没有同名Service存在,就没有副作用。也可以使用任何其他资源(事实上,领导选举机制不就会使用ConfigMap来替代Endpoint)。
你一定对资源如何被应用于该目的感兴趣。以调度器为例。所有调度器实例都会尝试创建(之后更新)一个Endpoint资源,称为kube-scheduler。可以在kube-system命名空间中找到它,如下面的代码清单所示。
#代码11.11 用于领导选举kube-scheduler Endpoint资源
$ kubectl get endpoints kube-scheduler -n kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"minikube","leaseDurationSeconds":15,"acquireTime":"2017-05-27T18:54:53Z","renewTime":"2017-05-28T13:07:49Z","leaderTransitions":0}'
control-plane.alpha.kubernetes.io/leader注释是比较重要的部分。如你所见,其中包含了一个叫作holderldentity的字段,包含了当前领导者的名字。第一个成功将姓名填入该字段的实例成为领导者。实例之间会竞争,但是最终只有一个胜出。
还记得之前讨论过的乐观并发概念吗?乐观并发保证如果有多个实例尝试写名字到资源,只有一个会成功。根据是否写成功,每个实例就知道自己是否是领导者。
一旦成为领导者,必须顶起更新资源(默认每2秒),这样所有其他的实例就知道它是否还存活。当领导者宕机,其他实例会发现资源有一阵没被更新了,就会尝试将自己的名字写到资源中尝试成为领导者。简单吧,对吧?
Kubernetes架构原理的更多相关文章
- Istio入门实战与架构原理——使用Docker Compose搭建Service Mesh
本文将介绍如何使用Docker Compose搭建Istio.Istio号称支持多种平台(不仅仅Kubernetes).然而,官网上非基于Kubernetes的教程仿佛不是亲儿子,写得非常随便,不仅缺 ...
- k8s入坑之路(2)kubernetes架构详解
每个微服务通过 Docker 进行发布,随着业务的发展,系统中遍布着各种各样的容器.于是,容器的资源调度,部署运行,扩容缩容就是我们要面临的问题. 基于 Kubernetes 作为容器集群的管理平 ...
- 【转载】k8s入坑之路(2)kubernetes架构详解
每个微服务通过 Docker 进行发布,随着业务的发展,系统中遍布着各种各样的容器.于是,容器的资源调度,部署运行,扩容缩容就是我们要面临的问题. 基于 Kubernetes 作为容器集群的管理平台被 ...
- NET/ASP.NET Routing路由(深入解析路由系统架构原理)(转载)
NET/ASP.NET Routing路由(深入解析路由系统架构原理) 阅读目录: 1.开篇介绍 2.ASP.NET Routing 路由对象模型的位置 3.ASP.NET Routing 路由对象模 ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- Kubernetes 架构(下)- 每天5分钟玩转 Docker 容器技术(121)
上一节我们讨论了 Kubernetes 架构 Master 上运行的服务,本节讨论 Node 节点. Node 是 Pod 运行的地方,Kubernetes 支持 Docker.rkt 等容器 Run ...
- Hive的配置| 架构原理
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hi ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
随机推荐
- Java线程池的工作流程
线程池刚被创建的时候,只是向系统里申请一个用于执行流程队列和管理线程池的线程资源.在调用execute()添加一个任务时,线程池会按照以下流程执行: 1.如果正在运行的线程数少于corePoolSiz ...
- Envoy:主动健康监测
实验文件 docker-compose version: '3' services: envoy: image: envoyproxy/envoy-alpine:v1.15-latest enviro ...
- WIKI和JIRA-安装与使用
1.Wiki介绍1.1 Wiki(多人协作的写作系统)是一种超文本系统,这种超文本系统支持面向社群的协作式写作,即人人可编辑.在公司的项目管理中,可以把它当作文档管理和信息组织(Portlet)系统来 ...
- ipmitool -I lanplus -H IPADDR -U USERNAME -P PASSWORD power reset
IPMI是智能型平台管理接口(Intelligent Platform Management Interface)的缩写,是管理基于 Intel结构的企业系统中所使用的外围设备采用的一种工业标准,该标 ...
- mysql基础之数据库变量(参数)管理
数据库的数据存放路径:[root@ren7 mysql]# pwd /var/lib/mysql [root@ren7 mysql]# ls aria_log.00000001 ibdata1 mul ...
- .NET6系列:微软正式宣布Visual Studio 2022
系列目录 [已更新最新开发文章,点击查看详细] 首先,我们要感谢正在阅读这篇文章的你,我们所有的产品开发都始于你也止于你,无论你是在开发者社区上发帖,还是填写了调查问卷,还是向我们发送了反馈意 ...
- Ansible-快速启动
Ansible是一款简单的运维自动化工具,只需要使用ssh协议连接就可以来进行系统管理,自动化执行命令,部署等任务. Ansible的特点 1.ansible轻量级无客户端agentless,只需要双 ...
- android格式化日期
import android.text.format.DateFormat import java.util.* dateTextView.text = DateFormat.format(" ...
- ELK搭建-windows
一.E 二.L 启动 三.K 四.filebeat 五.配置文件使用 1.logstash-sample.conf # Sample Logstash configuration for creati ...
- 循环IRNNv2Layer实现
循环IRNNv2Layer实现 IRNNv2Layer实现循环层,例如循环神经网络(RNN),门控循环单元(GRU)和长期短期记忆(LSTM).支持的类型为RNN,GRU和LSTM.它执行循环操作,该 ...